一种基于CTC-Conformer的语音情绪识别方法
- 国知局
- 2024-06-21 11:48:39
本发明自然语言处理领域,具体是一种基于ctc-conformer的语音情绪识别方法。
背景技术:
1、语音是人类之间最快速、最高效的一种交流手段,也是最悠久的一种交流方式,最早可以追溯到原始社会时期,随着人工智能的发展,语音交流已经不再是人类独有的专利,自从苹果公司在2011年10月份发布iphone 4s时宣布语音助手siri的诞生,人类便开始真正迈进通过语音与人机进行交互的时代。
2、语音信号是人类之间最快,最自然的通信方式,这促使研究人员将语音视为一种快速有效的人机交互方式。语音情绪识别从说话者的语音中提取说话人的情绪状态,它是交互式智能系统的重要组成部分。语音情感识别一般是由三部分组成,包括语音信号采集、情感特征提取以及情感识别。
3、语音信号中包含了多方面的信息,对这些信息进行进一步加工处理可以用于许多研究,包括自动语音识别、说话人识别等。现有的语音情绪识别研究能够做到从同一段语音中提取多种声学特征,但却没有考虑到不同的声学特征侧重点不尽相同,单一的使用某种特征作为研究对象无法做到充分利用音频信号中的信息,这样也会使得情绪识别准确率不能明显提升。
技术实现思路
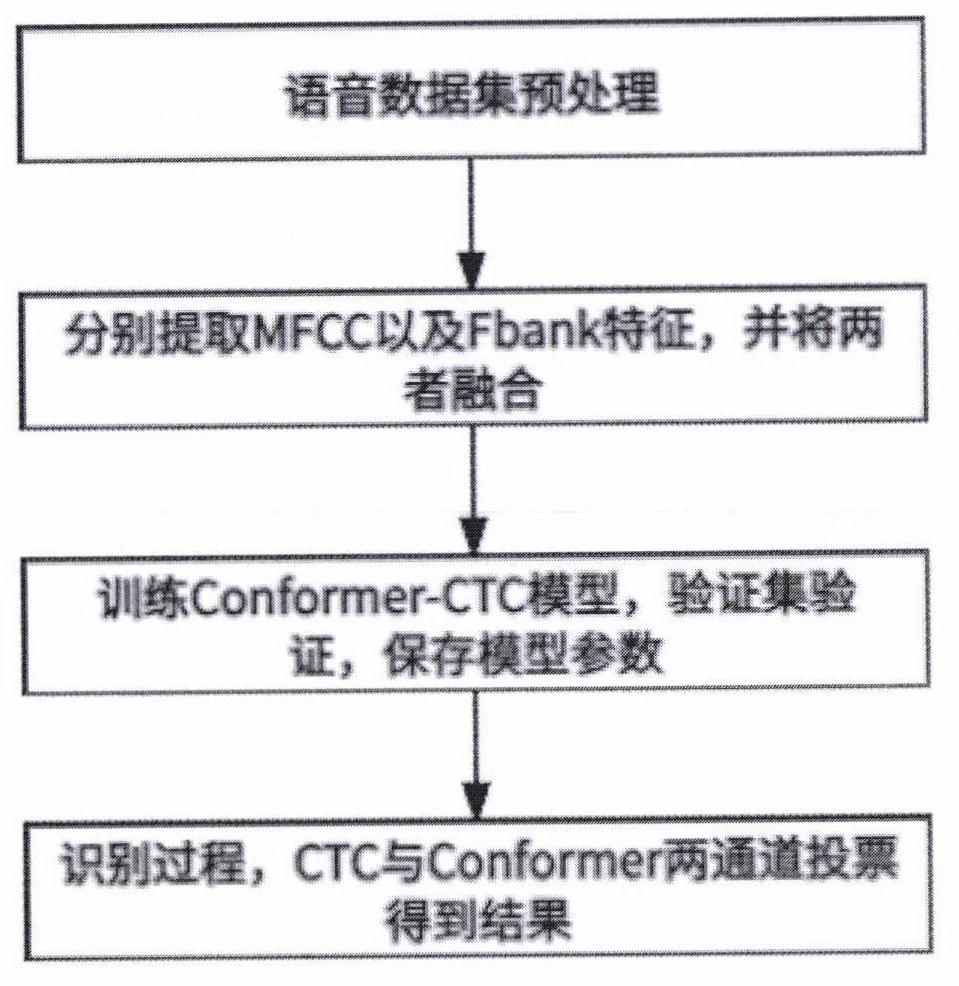
1、针对现有技术的缺点,本发明提供了一种基于ctc-conformer的语音情绪识别方法,将ctc硬对齐特性以及conformer中多头注意力机制的软对齐特性相结合,以提高育婴包含情绪的识别准确率,同时在提取语音特征的过程中将mfcc与fbank相融合,增强语音特征的全面性。该方法使用conformer enconder作为shared enconder,confomer模型包含前馈神经、卷积以及多头注意力机制多重网络,使得特征更容易被学习,更容易被优化。在通过使用预处理的数据集训练模型后,在识别时,通过ctc得到结果a,通过conformer得到结果b,两者进行投票处理得到最终结果。该方法包含以下步骤:
2、步骤1)对语音情绪数据集进行预处理。
3、步骤2)提取语音特征fbank以及mfcc并进行融合。
4、步骤3)构建模型,结合ctc硬对齐特性以及conformer软对齐特性,传入融合特征进行模型的训练。
5、步骤4)识别阶段,传入音频通过提取特征并进行融合后,传入模型,经ctc得到结果a,经conformer得到结果b,进行投票处理后得到最终结果。
6、进一步地,步骤1)具体为:
7、步骤101)选择交互式情感二元运动捕捉数据库(iemocap)作为实验所用数据集,该数据集包含6类情绪:neutral,happiness,sadness,anger,frustrated,excited。
8、步骤102)划分数据集,分别将80%的数据用于训练,20%的数据用于验证。
9、步骤103)当将iemocap的语音统一到相同长度,这里统一到2秒,即把一条语音切分成2秒一段,重叠1.6秒;不足2秒的语音用0补充。
10、进一步地,步骤2)语音特征融合方法具体为:
11、步骤201)对统一长度的语音数据,进行语音的特征提取,包括预加重、分帧、加窗、傅里叶变换等操作。
12、步骤202)语音数据在进行加窗之后进行傅里叶变换,通过mel滤波器组(取12维)得到fbank特征。
13、步骤203)在fabnk的特征上增加一个离散余弦变换得到mfcc特征(取40维),最后将mfcc嵌入到fbank中进行融合。
14、进一步地,步骤3)具体为:
15、步骤301)采用pytorch作为深度学习框架进行模型的搭建和训练。
16、步骤302)将conformer enconer作为shared eneonder,包含前馈,多头注意力、卷积等多层网络。
17、步骤303)conformer中的多头注意力机制,多头注意力中头的数量为8个,计算公式如下:
18、headi=attention(qi,ki,vi),i=1,...,h
19、multi(q,k,v)=concat(head1,...,headh)wo
20、其中h代表的是head的数量,q、k和v则是mfccs特征经过位置编码和投影后得到参数,以及是第i个head对应于q、k和v的训练参数,之后得到了每个head对应的qi、ki以及vi,headi为第i个head经过自注意力计算后的值,wo为参数矩阵,multi(q,k,v)代表h个head对应的多头注意力的值。
21、步骤304)一边使用ctc进行解码,使语音特征与标签一一对应,可以理解为硬对齐,其ctc loss计算公式如下:
22、
23、其中alian(l|x)表示表示所有将长度为s的序列对齐到长度为t的输入序列的方式,p(π|x)表示经网络输出语音数据每种情绪的概率。
24、步骤305)一边使用conformer deconder进行解码,通过conformer的多头注意力机制分配权重,实现软对齐,使用pytorch中的交叉熵损失函数来计算conformer的损失。其公式如下所示:
25、
26、步骤306)在每个epoch中,将训练好的权重文件及其对应的损失值保存下来。在训练过程中及时发现模型训练的效果,并选择损失值最低的权重文件作为最佳模型。这个步骤可以有效地提高模型的准确率和泛化能力。
27、步骤307)使用20%的数据验证集准确率来评估分类器的性能。准确率是指模型预测正确的样本数(真阳性和真阴性)占样本总数的比例。准确率越高,表示模型的分类性能越好。其公式如下所示:
28、
29、其中,tp、tn、fp和fn分别表示真阳性、真阴性、假阳性和假阴性。
30、进一步地,所述步骤4)具体为:
31、步骤401)待识别语音数据经过步骤1进行预处理获得若干条较短的语音片段,并将这些语音片段作为待识别的音频数据样本。
32、步骤402)按照步骤3从上述的音频数据样本中提取2种特征,并将两种特征进行融合
33、步骤403)融合后的语音特征传入网络,经过ctc解码器得到结果a,经过conformer解码器得到结果b,其中结果a与b为两通道分别预测的各语音情绪的概率,最后将结果a与结果b进行投票处理得到最终识别结果。
34、有益效果
35、(1)本发明是一种基于ctc-conformer的语音情绪识别方法,首先在特征提取环节,我们提取40维的fbnak特征,并在fbank的基础上进行离散余弦变换提取12维的mfcc特征,最后将两种融合拓宽特征的全面性。
36、(2)本发明利用ctc算法的硬对齐特性以及conformer中多头注意力机制的软对齐特性进行结合,互补以提高模型的性能。
技术特征:1.一种基于ctc-conformer的语音情绪识别方法,融合语音特征并将ctc软对齐以及conformer软对齐特征结合,其特征是包括以下步骤:
2.根据权利要求1所述的一种基于ctc-conformer的语音情绪识别方法,其特征在于,所述步骤1中语音情绪数据集的处理步骤具体如下:
3.根据权利要求1所述的一种基于ctc-conformer的语音情绪识别方法,其特征在于,所述步骤2中语音特征融合方法具体如下:
4.根据权利要求1所述的一种基于ctc-conformer的语音情绪识别方法,其特征在于,所述步骤3模型的构建、训练参数及分类性能评估指标如下:
5.根据权利要求1所述的一种基于ctc-conformer的语音情绪识别方法,其特征在于,所述步骤4识别阶段,具体步骤如下:
技术总结本发明属于自然语言处理领域,具体是一种基于CTC‑Conformer的语音情绪识别方法。通过结合CTC的硬对齐特性以及Conformer软对齐特性来提高语音情绪的识别准确率。并且在特征提取环节加入语音特征融合技术增强了识别特征的全面性。该方法包含语音数据的预处理,其中包含预加重、分帧、快速傅里叶变换的操作,再者将提取的MFCC以及Fbank特征进行融合。搭建模型将Conformer Encnder作为Shared Enconder,CTC以及Conformer Deconder分别解码进行训练,最后识别阶段将两通道CTC结果以及Conformer Deconder结果进行投票处理得出最终的识别结果。技术研发人员:王翔,武晓光受保护的技术使用者:南京工业大学技术研发日:技术公布日:2024/5/6本文地址:https://www.jishuxx.com/zhuanli/20240618/23699.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。