基于块级别对比学习的声码器指纹识别方法、系统及设备
- 国知局
- 2024-06-21 11:51:26
本发明属于信息安全,涉及一种声码器指纹识别方法、系统及设备,特别涉及一种基于块级别对比学习的声码器指纹识别方法、系统及设备,用于针对语音深度伪造的检测和分析。
背景技术:
1、目前基于深度神经网络的语音伪造技术对公共舆论的可信度和真实性构成了严峻的挑战。无论是人类用户还是自动说话人验证(asv)系统都面临着高风险的安全威胁[文献1]。因此,伪造语音检测技术的发展是至关重要的。
2、目前,许多机构正在加大力度开发可靠的语音伪造检测系统。典型的语音欺伪造检测系统通常包括前端特征提取器和后端分类器。特征提取器通常通过从原始波形中提取手工设计的声学特征,包括恒定q倒谱系数(cqccs)、线性频率倒谱系数(lfccs)和mel尺度短时傅里叶变换(mstft),在音频反欺骗任务的背景下已经证明了它们的效用。后端分类器通常通过提取的特征来判断音频是伪造的还是真实的。轻量级卷积神经网络(lcnn)[文献2]、残差网络(resnet)[文献3]、rawnet2[文献4]和图注意力网络(gat)[文献5]等架构在检测伪造音频方面表现出了卓越的性能。
3、尽管许多研究已经关注于语音伪造检测的问题,但对于语音伪造算法的溯源追踪分析的研究相对有限。在许多实际场景中,不仅要确定语音的真实性,还要识别用于生成它的模型或算法[文献6]。如图1所示,在语音伪造过程中,声码器模块是一个关键组件,在将声学参数转换为语音波形的过程中可能留下独特的指纹,它可以用于追踪伪造音频的来源。
4、yan等人[文献7]已经研究了声码器指纹,并开发了一个检测系统,用于追踪从八种不同声码器生成的伪造语音的来源。然而,该方法仅在封闭集设置下进行了简单评估,并且在跨数据集和语音压缩场景中其性能显著下降。
5、参考文献
6、[1]wu z,evans n,kinnunen t,et al.spoofing and countermeasures forspeaker verification:a survey[j].speech communication,2015,66:130-153.
7、[2]xiang wu,ran he,zhenan sun,and tieniu tan,“a light cnn for deepface representation with noisy labels,”ieee transactions on informationforensics and security,vol.13,no.11,pp.2884-2896,2018.
8、[3]kaiming he,xiangyu zhang,shaoqing ren,and jian sun,“deep residuallearning for image recognition,”in proceedings of the ieee conference oncomputer vision and pattern recognition,2016,pp.770-778.
9、[4]hemlatatak,jose patino,massimiliano todisco,andreas nautsch,nicholas evans,and anthony larcher,“end-to-end anti-spoofing with rawnet2,”inicassp 2021-2021 ieee international conference on acoustics,speech and signalprocessing(icassp).ieee,2021,pp.6369-6373.
10、[5]hemlatatak,jee-weon jung,jose patino,massimiliano todisco,andnicholas evans,“graph attention networks for anti-spoofing,”arxiv preprintarxiv:2104.03654,2021.
11、[6]tinglong zhu,xingming wang,xiaoyi qin,and ming li,“source tracing:detecting voice spoofing,”in 2022 asiapacific signal and informationprocessing association annual summit and conference(apsipa asc).ieee,2022,pp.216-220.
12、[7]xinrui yan,jiangyan yi,jianhua tao,chenglong wang,haoxin ma,taowang,shiming wang,and ruibo fu,“an initial investigation for detectingvocoder fingerprints of fake audio,”in proceedings of the 1st internationalworkshop on deepfake detection for audio multimedia,2022,pp.61-68.
技术实现思路
1、为了解决上述技术问题,本发明提出了一种基于块级别对比学习的声码器指纹识别方法、系统及设备,基于一种新的声码器架构归因方案vfd-net(声码器指纹检测网络),该方法利用块级别对比学习来增强提取的声码器指纹的全局一致性,旨在将伪造音频的来源归因到特定的声码器架构,即使声码器已经进行了微调或通过其他数据重新训练。
2、本发明的方法所采用的技术方案是:一种基于块级别对比学习的声码器指纹识别方法,包括以下步骤:
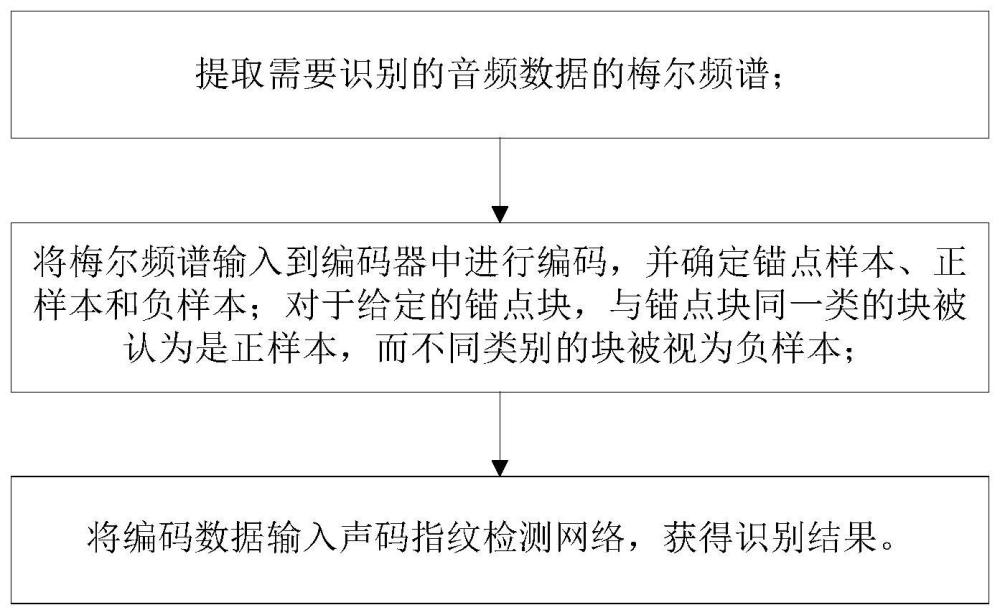
3、步骤1:提取需要识别的音频数据的梅尔频谱;
4、步骤2:将梅尔频谱输入到编码器中进行编码,并确定锚点样本、正样本和负样本;对于给定的锚点块,与锚点块同一类的块被认为是正样本,而不同类别的块被视为负样本;
5、步骤3:将编码数据输入声码器指纹检测网络,获得识别结果;
6、所述声码器指纹检测网络包括顺序连接的输入层、残差块、全局平均池化层和全连接层;
7、所述输入层,用于接受输入的块级别编码数据;
8、所述残差块,包括串联设置的4个残差块,每个残差块包含两个分支,其中一个分支是恒等映射分支,另一个分支是经过一系列卷积和激活函数的非线性变换分支,这两个分支的结果相加,形成了残差块的输出;在每个残差块中,残差连接通过跳跃连接实现,将输入直接加到卷积层输出上。
9、作为优选,步骤2中,所述编码器包含一系列的卷积层、激活函数层和最大池化层,用于提取细粒度特征。
10、作为优选,步骤3中,所述声码器指纹检测网络,是训练好的网络;训练过程包括以下子步骤:
11、步骤3.1:从训练数据集中随机选择一个batch的音频样本,这里batch为预设值;
12、步骤3.2:利用librosa python库读取音频样本,并将其截断补长至固定大小采样点,以保证所有训练样本具有相同的长度;
13、步骤3.3:提取音频样本的对数梅尔频谱,将其切分成n×n的块,并从中随机选取m块;其中,n、m为预设值;
14、步骤3.4:将这些块输入到编码器中进行块级别编码,并确定锚点样本、正样本和负样本;对于给定的锚点块,与锚点块同一类的块被认为是正样本,而不同类别的块被视为负样本;
15、步骤3.5:将编码数据输入所述声码器指纹检测网络,进行网络训练;
16、在训练过程中分别计算对比损失和交叉熵损失,并通过自动加权机制计算总损失;训练开始前设定一个最大训练批次,当验证集的准确率达到最高时,此时保存得到最好的分类模型;而当验证集的准确率不发生变化并超过一定批次或达到最大训练批次时,停止训练。
17、作为优选,步骤3.5中,所述对比损失l1为:
18、
19、其中,i∈i表示随机训练块的索引,p(i)表示对应于块i的所有正样本的索引集,而|p(i)|表示正样本的数量;集合a(i)包括了块i的所有正负对;块i的特征向量用zi表示,而za表示的是集合a(i)中块的特征向量;向量zp和zn分别对应于正样本和负样本的特征向量;τ是一个标量温度参数;
20、交叉熵损失l2为:
21、
22、其中,n是每个batch中的样本数量,yi是实际标签,表示第i个样本的真实类别,取值为0或1,是模型的预测输出,表示第i个样本属于类别1的概率。
23、总损失l为:
24、l=α·l1+β·l2;
25、其中,α和β为两个非负权重。
26、本发明的系统所采用的技术方案是:一种基于块级别对比学习的声码器指纹识别系统,包括以下模块:
27、梅尔频谱提取模块,用于提取需要识别的音频数据的梅尔频谱;
28、编码模块,用于将梅尔频谱输入到编码器中进行编码,并确定锚点样本、正样本和负样本;对于给定的锚点块,与锚点块同一类的块被认为是正样本,而不同类别的块被视为负样本;
29、识别模块,用于将编码数据输入声码器指纹检测网络,获得识别结果;
30、所述声码器指纹检测网络包括顺序连接的输入层、残差块、全局平均池化层和全连接层;
31、所述输入层,用于接受输入的块级别编码数据;
32、所述残差块,包括串联设置的4个残差块,每个残差块包含两个分支,其中一个分支是恒等映射分支,另一个分支是经过一系列卷积和激活函数的非线性变换分支,这两个分支的结果相加,形成了残差块的输出;在每个残差块中,残差连接通过跳跃连接实现,将输入直接加到卷积层输出上。
33、作为优选,所述编码器包含一系列的卷积层、激活函数层和最大池化层,用于提取细粒度特征。
34、作为优选,所述声码器指纹检测网络,是训练好的网络;
35、训练过程包括以下子模块:
36、模块2.1,用于从训练数据集中随机选择一个batch的音频样本,这里batch为预设值;
37、模块2.2,用于利用librosa python库读取音频样本,并将其截断补长至固定大小采样点,以保证所有训练样本具有相同的长度;
38、模块2.3,用于提取音频样本的对数梅尔频谱,将其切分成n×n的块,并从中随机选取m块;其中,n、m为预设值;
39、模块2.4,用于将这些块输入到编码器中进行块级别编码,并确定锚点样本、正样本和负样本;对于给定的锚点块,与锚点块同一类的块被认为是正样本,而不同类别的块被视为负样本;
40、模块2.5,用于将编码数据输入所述声码器指纹检测网络,进行网络训练;
41、在训练过程中分别计算对比损失和交叉熵损失,并通过自动加权机制计算总损失;训练开始前设定一个最大训练批次,当验证集的准确率达到最高时,此时保存得到最好的分类模型;而当验证集的准确率不发生变化并超过一定批次或达到最大训练批次时,停止训练。
42、作为优选,所述对比损失l1为:
43、
44、其中,i∈i表示随机训练块的索引,p(i)表示对应于块i的所有正样本的索引集,而|p(i)|表示正样本的数量;集合a(i)包括了块i的所有正负对;块i的特征向量用zi表示,而za表示的是集合a(i)中块的特征向量;向量zp和zn分别对应于正样本和负样本的特征向量;τ是一个标量温度参数;
45、交叉熵损失l2为:
46、
47、其中,n是每个batch中的样本数量,yi是实际标签,表示第i个样本的真实类别,取值为0或1,是模型的预测输出,表示第i个样本属于类别1的概率。
48、总损失l为:
49、l=α·l1+β·l2;
50、其中,α和β为两个非负权重。
51、本发明的设备所采用的技术方案是:一种基于块级别对比学习的声码器指纹识别设备,包括:
52、一个或多个处理器;
53、存储装置,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现所述的基于块级别对比学习的声码器指纹识别方法。
54、本发明提出了一种基于块级别对比学习的声码器指纹识别方法、系统及设备,基于一种新的声码器架构归因方案vfd-net(声码器指纹检测网络),利用块级别对比学习来增强提取的声码器指纹的全局一致性,在跨数据集和aac压缩场景下有较高的准确率,具有良好的泛化性和鲁棒性,并可以进一步应用于部分伪造语音检测。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24021.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。