一种基于频谱特征迁移学习的老年人语音增强方法与流程
- 国知局
- 2024-06-21 11:51:35
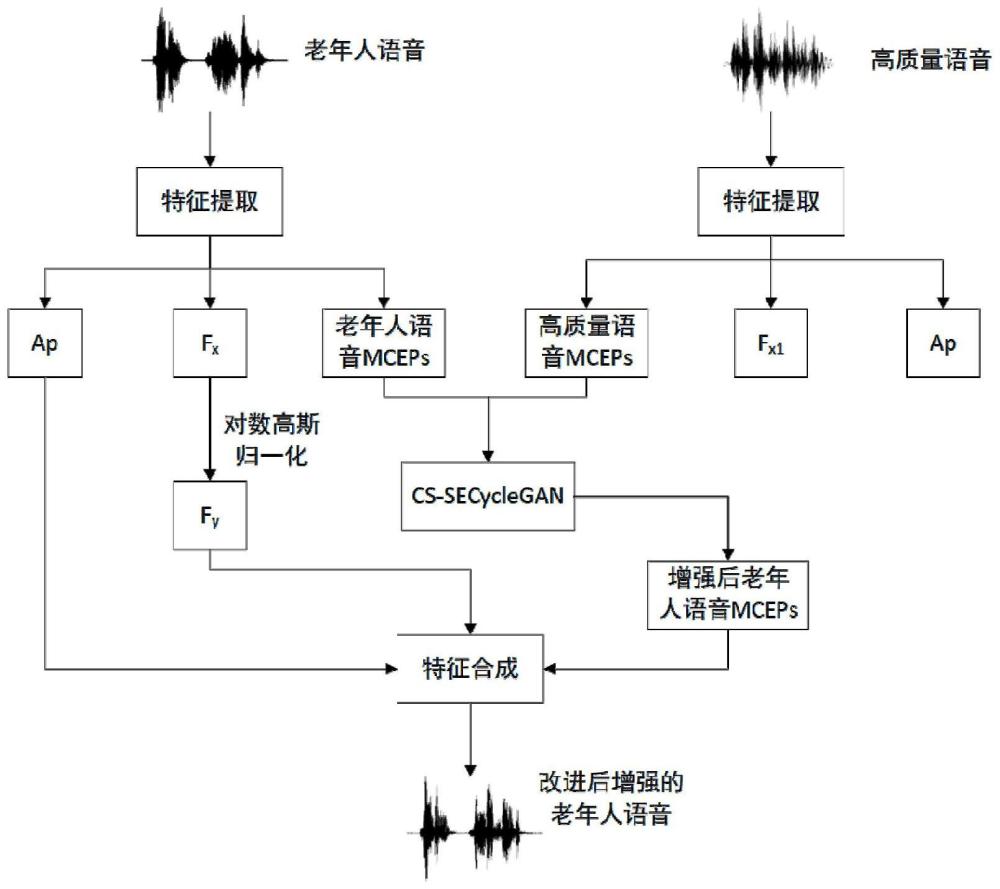
本发明属于陪伴机器人领域,具体说是一种基于频谱特征迁移学习的老年人语音增强方法。
背景技术:
1、目前已有的语音增强技术有谱减法、维纳滤波法和基于深度学习网络的方法。谱减法通过估计信号和噪声的频谱,从语音信号的频谱中减去估计的噪声频谱来实现噪声抑制。但是随着发现的噪声种类越来越多,谱减法在语音增强后会产生“音乐噪声”,影响增强效果;维纳滤波法的基本原理是通过适当的滤波器来最小化信号和噪声的均方误差。但维纳滤波法只适用于平稳信号,对于复杂的信号效果不好。基于深度学习的语音增强方法多种,针对不同的数据应用不同的模型,目前cnn、rnn、gan等模型都可以应用到语音增强领域。
2、在gan系列模型中,segan网络模型用最小二乘损失函数代替交叉熵损失函数,解决了传统gan网络难以收敛和存在梯度消失的问题,并且提升了算法速度,通过这种无监督训练使得segan网络能够通过对抗训练学习生成更为真实、自然的语音,并且这种端到端的模型简化了整个语音增强系统,模型具有较强的泛化能力。但经过segan处理后的语音仍然存在明显的残余噪声和失真问题,对于非均匀噪声的处理效果不好,在低信噪比条件下,segan的性能可能会受到一定的限制。在极端噪声环境中,一些细节信息可能无法有效地恢复,对于老年人语音虽然改善了语音不清的情况,但会存在一些残余噪音,对于环境噪音处理效果一般,影响在养老院场景中陪护机器人对老年人语音的识别。
技术实现思路
1、本发明目的是提供一种基于频谱特征迁移学习的老年人语音增强方法。本发明用于老年陪护机器人中,通过改变老年人语音的频谱特征,对老年人语音质量进行增强,提高机器人对老年人语音的识别准确率,实现老年人与陪护机器人的高质量人机交互。
2、本发明为实现上述目的所采用的技术方案是:一种基于频谱特征迁移学习的老年人语音增强方法,包括以下步骤:
3、将源数据集和目标数据集分别进行特征提取,各得到基频、频谱包络和非周期信号;分别对基频进行对数高斯归一化,得到归一化后的基频;分别对频谱包络进行压缩得到源数据集mceps和目标数据集mceps;
4、将源数据集mceps和目标数据集mceps输入到cs-secyclegan网络中进行增强操作,生成增强后的源数据集mceps和目标数据集mceps;
5、将增强后的源数据集mceps与对源数据集特征提取得到的非周期信号、归一化后的基频进行特征合成,得到增强后的源语音。
6、所述将源数据集mceps和目标数据集mceps输入到cs-secyclegan网络中进行增强操作,包括以下步骤:
7、正向生成器gx→y输入源数据集,生成增强后的目标数据集mceps,使相应的判别器承认生成的语音与目标数据集相同;
8、反向生成器gy→x用于输入目标数据集,生成增强后的源数据集mceps,使相应的判别器承认生成的语音与源数据集相同。
9、所述正向生成器gx→y和反向生成器gy→x中:
10、上采样采用亚像素卷积层将低分辨率的特征映射到高分辨率,以提高语音信号的质量;其中,激活函数采用门控线性单元,通过线性部分对输入进行线性变换、门控部分对输入进行门控操作,以进行并行处理时序数据。
11、所述源语音判别器dx和目标语音判别器dy中:
12、在每个下采样模块的卷积层后面添加一个cbam模块;cbam模块中,通道注意力的输入和经过通道注意力机制后的输出进行合并,输入至空间注意力机制中;所述空间注意力机制的输入和经过空间注意力机制后的输出进行合并,得到特征作为cbam模块的输出;
13、激活函数采用门控线性单元,通过线性部分对输入进行线性变换、门控部分对输入进行门控操作,以进行并行处理时序数据。
14、所述特征提取,包括以下步骤:
15、dio模块提取输入源数据集中的基频;
16、cheaptrick模块输入基频、源数据集波形提取频谱包络;
17、platinum模块输入基频、频谱包络和源数据集波形提取非周期信号。
18、一种基于频谱特征迁移学习的老年人语音增强系统,包括:
19、特征提取单元,用于将源数据集和目标数据集分别进行特征提取,各得到基频、频谱包络和非周期信号;分别对基频进行对数高斯归一化,得到归一化后的基频;分别对频谱包络进行压缩得到源数据集mceps和目标数据集mceps;
20、cs-secyclegan增强单元,用于将源数据集mceps和目标数据集mceps输入到cs-secyclegan网络中进行增强操作,生成增强后的源数据集mceps和目标数据集mceps;
21、特征合成单元,用于将增强后的源数据集mceps与对源数据集特征提取得到的非周期信号、归一化后的基频进行特征合成,得到增强后的源语音。
22、所述cs-secyclegan网络包括两个生成器和两个判别器,其中:
23、正向生成器gx→y用于输入源数据集,生成增强后的目标数据集mceps,使相应的判别器承认生成的语音与目标数据集相同;
24、反向生成器gy→x用于输入目标数据集,生成增强后的源数据集mceps,使相应的判别器承认生成的语音与源数据集相同。
25、所述源语音生成器gx和目标语音生成器gy,包括顺次连接的下采样模块构成的下采样部分、6个残差块、由上采样模块构成的上采样部分;
26、激活函数采用门控线性单元;
27、在上采样部分,第一个上采样模块卷积层后加入cbam结构,在所有卷积层后加入亚像素卷积层;
28、在下采样部分,第一个下采样模块卷积层后加入cbam结构;
29、在每个残差块第一个卷积层后面加入cbam结构。
30、所述源语音判别器dx和目标语音判别器dy,包括顺次连接的若干下采样模块;在每个下采样模块的卷积层后面添加一个cbam模块;激活函数采用门控线性单元。
31、所述cbam结构包括通道注意力和空间注意力机制;所述通道注意力的输入和经过通道注意力机制后的输出进行合并,输入至至空间注意力机制中;所述空间注意力机制的输入和经过空间注意力机制后的输出进行合并,得到特征作为cbam模块的输出。
32、本发明具有以下有益效果及优点:
33、1、本发明改进了传统网络,引入cbam网络结构,使模型更加适合老年人语音,解决了传统模型存在的残余噪声问题。并且生成的语音质量更加自然、清晰,更好的实现了对老年人语音的增强。
34、2、本发明不仅解决了老年人语音由于自身生理因素造成的语音质量不清晰问题,还解决了由于外部环境噪声对语音质量的影响。使得老年人语音清晰度提高,老年人与机器人交互通信系统得以优化。
35、3、本发明基于cs-secyclegan模型,将语音信号分解为基频、频谱包络和非周期特征三种语音信号,基频信号进行对数高斯归一化处理,频谱包络通过cs-secyclegan模型进行转换,然后将处理后的基频和频谱包络以及非周期特征信号重新合成语音信号,实现对老年人语音的增强;
36、4、cs-secyclegan模型生成器中下采样加入门限单元glu,上采样卷积层后面加了一个亚像素卷积层,亚像素卷积层能够将低分辨率的特征映射到高分辨率,可以帮助模型更好的捕捉音频的细节和结构;
37、5、cs-secyclegan模型判别器中加入了注意力机制模块cbam,有助于生成更高质量、自然的语音。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24038.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表