一种基于音视频特征融合的课堂粗粒度声音事件检测方法
- 国知局
- 2024-06-21 11:51:30
本发明属于智慧课堂,更具体地,涉及一种基于音视频特征融合的课堂粗粒度声音事件检测方法。
背景技术:
1、课堂活动检测一直是一个热门话题,不断有专家学者在此方面进行研究,通过分析课堂中学生以及教师行为,课后针对内容进行相应调整,可以同时提升老师的教学技能和学生的学习效率。
2、要实现课堂活动检测,高质量、细致的课堂活动记录是必不可少的,这就需要判别是否有人在说话,且说话人的身份是什么,同时记录下课堂上老师、学生各自话语的起止时间,总的来说,也就是进行一种用于课堂的粗粒度的声音事件检测。可是除非专人记录课堂上发生的一切,或者同时让老师和学生都各自佩戴上独立的收声设备,否则课堂中老师和学生各自单独的活动记录是非常难以获取的,但这二者显然都无法实现,往往所能提供的只有一至两个收声设备,里面包含了课堂情景下所有声音的混合。
3、部分研究提供了基于音频的课堂声音事件检测,当遇采集音频质量较差,课堂环境更加复杂时,或者教师的声音可能与某些学生的声音非常接近等情况,都会影响课堂声音事件检测的精度。同时在一些情境下,如师生交流问题时,老师和学生说话切换速度极快,这对于仅基于音频的课堂声音事件检测带来了极大的挑战,往往不能很好的检测到事件切换点,从而做出一些错误划分。
技术实现思路
1、针对现有技术的缺陷和改进需求,本发明提供了一种基于音视频特征融合的课堂粗粒度声音事件检测方法,其目的在于提高课堂的粗粒度的声音事件检测精度。
2、为实现上述目的,按照本发明的一个方面,提供了一种基于音视频特征融合的课堂粗粒度声音事件检测方法,包括:
3、获取课堂中所产生的视频数据和音频数据;
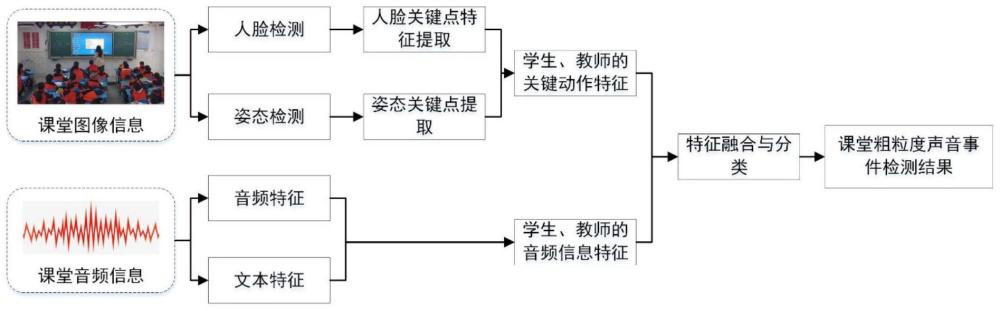
4、采用已构建的视频信息处理模型,对视频数据逐帧进行人脸检测,提取每帧中所有嘴部的状态信息;对视频数据逐帧进行人体姿态检测,提取每帧中所有人的姿态信息;按照时间序列对所述所有嘴部的状态信息和所述所有人的姿态信息进行拼接,作为视频动作特征;
5、采用已构建的音频信息处理模型,对音频数据逐帧提取音频特征,同时将音频数据转换为文本,对文本逐帧提取文本特征;按照时间序列对所述音频特征和所述文本特征进行拼接,作为音频信息特征;
6、基于所述视频动作特征以及所述音频信息特征,采用已构建的基于注意力机制的特征融合与分类模型,输出每帧说话角色的检测分类结果,从而得到课堂粗粒度声音事件检测结果,每个粗粒度声音事件包括事件起止时间及其对应的说话角色,说话角色分为老师、学生和混合三类。
7、进一步,所述视频信息处理模型中用于提取每帧中所有嘴部的状态信息的部分是通过基于mtcnn算法进行训练构建得到。
8、进一步,每个嘴部的状态信息是由左右嘴角及上下嘴唇四个关键点所构成的状态信息。
9、进一步,当识别到口罩时,对应嘴部的状态信息采用口罩信息进行标识。
10、进一步,所述视频信息处理模型中用于提取每帧中所有人的姿态信息的部分是通过基于alphapose算法进行训练构建得到。
11、进一步,所述视频数据包括教师视频数据和学生视频数据;
12、则按照时间序列对基于所述教师视频数据所得到的视频动作特征和基于学生视频数据所得到的视频动作特征进行拼接,作为总的视频动作特征,用于和所述音频信息特征输入所述特征融合与分类模型。
13、进一步,基于所述教师视频数据所提取的教师的姿态信息是由头部、颈部、左右肩、左右手肘、左右手、左右脚踝、左右膝、左右胯骨和躯干15个关键点的所构成的姿态信息;
14、基于所述学生视频数据所提取的学生的姿态信息是由头部、颈部、左右肩、左右手肘和左右手八个关键点所构成的姿态信息。
15、进一步,所述音频特征为梅尔倒谱系数。
16、进一步,按照时间序列对所述音频特征和所述文本特征进行拼接的方式为:
17、将所述音频特征和所述文本特征分别输入到cnn特征提取网络中,对特征提取后的结果按时间序列对齐后进行拼接,再输入至rnn网络,得到结合上下文信息的音频信息特征。
18、本发明还提供一种计算机可读存储介质,所述计算机可读存储介质存储的计算机程序,其中,在所述计算机程序被处理器运行时控制所述存储介质所在设备执行如上所述的一种基于音视频特征融合的课堂粗粒度声音事件检测方法。
19、总体而言,通过本发明所构思的以上技术方案,能够取得以下有益效果:
20、(1)本发明根据实际课堂环境产出的多种模态的数据,包括音频和视频,其中还提出将音频转为文本,进行文本特征提取,相当于提出采用三种模态的数据进行结合,进行课堂粗粒度声音事件检测方法。具体的,通过对课堂音频和视频信息进行特征提取及分析,使用了音频特征、文本特征和视频动作特征三种特征,采用这种多模态的融合的方式进行课堂粗粒度声音事件检测,有效避免了仅音频模态下当遇到音频质量较差、课堂环境复杂、教师的声音可能与某些学生的声音非常接近造成分割结果较差的问题,提高课堂粗粒度声音事件检测精度。
21、(2)本发明提出视频数据包括教师视频数据和学生视频数据,分别清楚的采集涉及教师动作的视频数据和涉及学生动作的视频数据,便于提高粗粒度声音事件检测精度。
技术特征:1.一种基于音视频特征融合的课堂粗粒度声音事件检测方法,其特征在于,包括:
2.根据权利要求1所述的课堂粗粒度声音事件检测方法,其特征在于,所述视频信息处理模型中用于提取每帧中所有嘴部的状态信息的部分是通过基于mtcnn算法进行训练构建得到。
3.根据权利要求1或2所述的课堂粗粒度声音事件检测方法,其特征在于,每个嘴部的状态信息是由左右嘴角及上下嘴唇四个关键点所构成的状态信息。
4.根据权利要求1或2所述的课堂粗粒度声音事件检测方法,其特征在于,当识别到口罩时,对应嘴部的状态信息采用口罩信息进行标识。
5.根据权利要求1所述的课堂粗粒度声音事件检测方法,其特征在于,所述视频信息处理模型中用于提取每帧中所有人的姿态信息的部分是通过基于alphapose算法进行训练构建得到。
6.根据权利要求1至5任一项所述的课堂粗粒度声音事件检测方法,其特征在于,所述视频数据包括教师视频数据和学生视频数据;
7.根据权利要求6所述的课堂粗粒度声音事件检测方法,其特征在于,基于所述教师视频数据所提取的教师的姿态信息是由头部、颈部、左右肩、左右手肘、左右手、左右脚踝、左右膝、左右胯骨和躯干15个关键点的所构成的姿态信息;
8.根据权利要求1所述的课堂粗粒度声音事件检测方法,其特征在于,所述音频特征为梅尔倒谱系数。
9.根据权利要求1所述的课堂粗粒度声音事件检测方法,其特征在于,按照时间序列对所述音频特征和所述文本特征进行拼接的方式为:
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储的计算机程序,其中,在所述计算机程序被处理器运行时控制所述存储介质所在设备执行如权利要求1至9一项所述的一种基于音视频特征融合的课堂粗粒度声音事件检测方法。
技术总结本发明属于智慧课堂技术领域,具体涉及一种基于音视频特征融合的课堂粗粒度声音事件检测方法,包括:采用视频信息处理模型,对视频数据逐帧进行人脸检测,提取每帧中所有嘴部状态信息;对视频数据逐帧进行人体姿态检测,提取每帧中所有人姿态信息;按照时间序列对所有嘴部状态信息和所有人姿态信息拼接,作为视频动作特征;采用音频信息处理模型,对音频数据逐帧提取音频特征,将音频数据转换为文本以逐帧提取文本特征;按照时间序列对音频特征和文本特征进行拼接,作为音频信息特征;基于视频动作特征和音频信息特征,采用特征融合与分类模型,输出每帧说话角色的检测分类结果,得到粗粒度声音事件检测结果。本发明能提高课堂声音事件检测精度。技术研发人员:许炜,崔玉蕾,周为受保护的技术使用者:华中科技大学技术研发日:技术公布日:2024/5/12本文地址:https://www.jishuxx.com/zhuanli/20240618/24030.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表