一种基于滤波器组、数据增强和ResNet50的环境声音分类方法
- 国知局
- 2024-06-21 11:51:43
本发明涉及声音识别,尤其涉及一种基于滤波器组、数据增强和resnet50的环境声音分类方法。
背景技术:
1、环境声音在我们生活中无处不在。无论是城市的喧嚣、工厂的机械轰鸣,还是大自然的鸟鸣虫鸣,每一种声音都承载着特定的信息和背景。这些声音不仅是我们日常生活的一部分,也反映了周围环境的状态和变化。
2、随着城市化和工业化的加速发展,环境中的声音也变得越来越复杂,因此对环境声音进行准确分类和识别显得尤为重要。这种基于滤波器组、数据增强和resnet50的环境声音分类方法,提供了一种高效精准的解决方案。通过对声音数据进行深度学习和特征提取,能够快速、准确地识别不同类型的声音,为环境监测、安防预警、健康诊断等领域提供了强大的支持。
3、近年来,随着工业的发展,声音研究人员提出了一系列的环境声音分类算法,中国专利“cn110047512a一种环境声音分类方法、系统及相关装置”提出了一种基于深度学习的混合网络结构的声音分类方法。此专利对目标区域内的环境声音进行采集,得到音频文件,再提取出环境声音对应的物理特性数据,并将此数据输入预设混合分类预测模型,输出分类结果。其中,预设混合分类预测模型的网络结构是由深度卷积神经网络模型的网络结构和light gbm模型的网络结构组合而成。该方法中预设混合分类预测模型的网络结构是由深度卷积神经网络模型的网络结构和light gbm模型的网络结构组合而成,即该预设混合分类预测模型综合了深度卷积神经网络模型和light gbm模型的优点,增强了鲁棒性,能够提高环境声音分类的准确率。
4、传统的声音识别算法大多使用声音波形作为特征进行分类,使用的特征较少,结构单一。还有一些声音识别算法使用高斯混合模型、隐马尔可夫模型等,虽然对环境声音分类有一定作用,但是其对声音本身的建模较少,导致分类效果不好。例如中国专利“cn110047512a一种环境声音分类方法、系统及相关装置”中仅对频谱图中的物理特性数据进行建模,也没有对这些数据进行进一步处理和数据增强操作,因此模型的准确率较低,不能达到实际应用的准确率要求。
技术实现思路
1、针对现有技术的不足,本发明提供一种基于滤波器组、数据增强和resnet50的环境声音分类方法,对声音特征进行充分建模,考虑较多的声音特征,解决以前的方法仅考虑声音的波形这种物理特征的缺陷。此外,本方法利用声音的特性进行合理的数据增强,降低较小的数据集对分类模型的影响,解决传统方法分类准确率较低的问题。
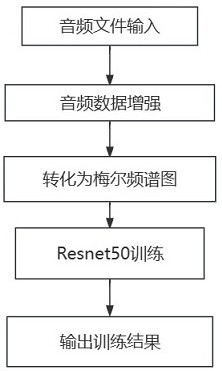
2、一种基于滤波器组、数据增强和resnet50的环境声音分类方法,包括以下步骤:
3、步骤1:针对要进行分类的环境声音,构建环境声音数据集,并将环境声音数据集中的环境声音数据进行音频增强。
4、步骤1.1:采集环境声音构建环境声音数据集。
5、步骤1.2:将环境声音数据集中的环境声音数据进行音频增强,获得音频增强后的音频文件。
6、步骤2:利用梅尔滤波器组将音频增强后的音频文件转化为梅尔频谱图。
7、步骤2.1:在pycharm软件当中,向当前配置的conda虚拟环境当中,导入库函数;这些库函数用于音频信号处理、创建图表以及操作系统中执行文件和目录库函数。
8、步骤2.2:将音频文件导入至pycharm的文件目录当中:设置采样率,然后进行音频数据的导入。
9、步骤2.3:使用梅尔滤波器组将音频数据生成梅尔频谱图。
10、步骤2.4:设置图像尺寸。
11、步骤2.5:将梅尔频谱图的单位进行转换,进行数据增强后的梅尔频谱图像绘制。
12、步骤3:将梅尔频谱图输入到改进的resnet50模型当中进行训练。
13、步骤3.1:使用卷积神经网络resnet50模型作为主干网络模型,对resnet50模型进行初始化,函数返回值为预训练的resnet50模型。
14、步骤3.2:对resnet50模型进行改进;将resnet50模型中的全连接层,使其输出为一个50维的向量,对于resnet50模型的第一个卷积层conv1的结构,使用conv2d的卷积方式,修改输入通道数为1,然后将resnet50模型中的步长kernel_size、步幅stride、填充padding分别调整为3、1、1。
15、步骤3.3:对改进的resnet50模型进行训练。
16、进行训练时,改进的resnet50模型的输入为数据增强后的梅尔频谱图,使用的优化器adam,设置初始学习率以及训练轮次,设置了交叉熵损失函数作为模型训练的损失函数,并通过weight_decay正则化技术,在损失函数中添加一个正则化项来防止过拟合。
17、步骤4:使用训练好的模型进行环境声音分类。
18、步骤4.1:对训练好的模型进行保存与导入。
19、步骤4.2对待处理的环境声音进行预处理,并生成梅尔频谱图。
20、步骤4.3 使用训练好的模型对梅尔频谱图进行分类,输出声音类别实现环境声音的分类。
21、采用上述技术方案所产生的有益效果在于:
22、本发明提供一种基于滤波器组、数据增强和resnet50的环境声音分类方法,具备以下有益效果。
23、(1)本环境声音分类方法将声音信号处理为梅尔频谱图,将声音信号图像化输入到改进的resnet50模型当中,成功将声音识别问题转化为图像识别问题。由于本方法基于深度学习技术,会对声音特征进行充分建模,考虑了较多的声音特征,所以我们解决了以前的方法仅考虑声音的波形这种物理特征的缺陷。
24、(2)传统的数据增强技术例如旋转、裁剪、随机噪点等忽略了声音本身的特性,不适用于此时对声音数据的增强。我们针对声音的特性进行时间偏移、音高变换和静音剪裁等操作,充分考虑了声音的特性。此种环境声音分类方法利用声音的特性进行合理的数据增强,降低了较小的数据集对分类模型的影响,解决了传统方法分类准确率比较低的问题。
25、(3)除此之外,与现有的环境声音分类方法相比,此方法采用改进的resnet50模型,相比于采用transformer等复杂网络模型的分类方法,该方法的准确率相当的同时保证了模型的轻便性。
技术特征:1.一种基于滤波器组、数据增强和resnet50的环境声音分类方法,其特征在于,包括以下步骤:
技术总结本发明提供一种基于滤波器组、数据增强和ResNet50的环境声音分类方法,涉及声音识别技术领域,本发明首先针对要进行分类的环境声音,构建环境声音数据集,并将环境声音数据集中的环境声音数据进行音频增强,然后利用梅尔滤波器组将音频增强后的音频文件转化为梅尔频谱图,将梅尔频谱图输入到改进的ResNet50模型当中进行训练;最后使用训练好的模型进行环境声音分类;本方法对声音特征进行充分建模,考虑较多的声音特征,解决以前的方法仅考虑声音的波形这种物理特征的缺陷。此外,本方法利用声音的特性进行合理的数据增强,降低较小的数据集对分类模型的影响,解决传统方法分类准确率较低的问题。技术研发人员:郭军,孟子莘,邵翔,师墨涵,梁雪琪,杨霄,于清泽,高洺策受保护的技术使用者:东北大学技术研发日:技术公布日:2024/5/12本文地址:https://www.jishuxx.com/zhuanli/20240618/24049.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。