一种基于Transformer的个性化藏语语音合成方法及系统
- 国知局
- 2024-06-21 11:52:04
本发明涉及语音合成,更具体的说是涉及一种基于transformer的个性化藏语语音合成方法及系统。
背景技术:
1、个性化语音合成是指根据特定用户的声音特征、语调、发音等因素,学习该说话人声音的特点并进行语音合成,近年来的需求在逐步提升。但由于人类自然语音的表现力非常丰富,在说话人音色和韵律上变化很大,导致建模有难度,目前仍处于研究和发展的初期阶段,面临多个挑战。
2、目前,个性化语音合成技术可以分为基于自适应的个性化语音合成和基于说话人特征嵌入的个性化语音合成两大类。基于自适应的语音合成技术希望通过大量语料学习一个通用的中性语音合成系统,然后再通过较少量的待合成说话人语音对网络进行调整,这样的方法合成出来的效果较好,但是一般需要几十分钟高质量的待合成说话人语料。而基于说话人特征嵌入的个性化语音合成技术则不需要待合成人大量的高质量语料,只需要通过少量给定的说话人语音提取出说话人特征嵌入到语音合成的藏语语音合成模型中即可,同时,基于说话人特征嵌入的个性化语音合成方法对音质的要求不高。
3、然而,现有的个性化语音合成技术大多应用于英语、汉语等语料丰富的语言中,基于说话人嵌入的方法通过联合训练的reference encoder获取说话人表征,然后将其嵌入到语音合成的声学模型中,构造一种端到端个性化语音合成模型。典型的referenceencoder有gst(global style token)、vae(variational autoencoder)等。其中,gst在没有任何韵律标签的情况下进行训练,挖掘出大量的表达风格。内部架构本身产生了可解释的软“标签”,可用于执行各种风格控制和转移任务,从而实现个性化语音合成的任务。
4、但是,藏语语音合成主要集中于端到端神经网络语音合成声学模型的研究上,关于藏语个性化语音合成的研究尚为空白。
5、因此,如何提供一种基于transformer的个性化藏语语音合成方法及系统,将gst(global style token)中的reference encoder引入端到端的transformer语音合成模型中,将情感、韵律等方面的学习加入到模型训练的特征提取中,从而实现个性化的藏语语音合成,是本领域技术人员亟需解决的问题。
技术实现思路
1、有鉴于此,本发明提供了一种基于transformer的个性化藏语语音合成方法及系统,用以解决上述现有技术中存在的技术问题。
2、为了实现上述目的,本发明提供如下技术方案:
3、一种基于transformer的个性化藏语语音合成方法,包括以下步骤:
4、获取不同藏语文本,并将所述藏语文本分别转写成拉丁字母,得到拉丁字母文本集;
5、获取不同的音频数据,分别通过给定的说话人语音提取出说话人特征,得到语音梅尔频谱图集;
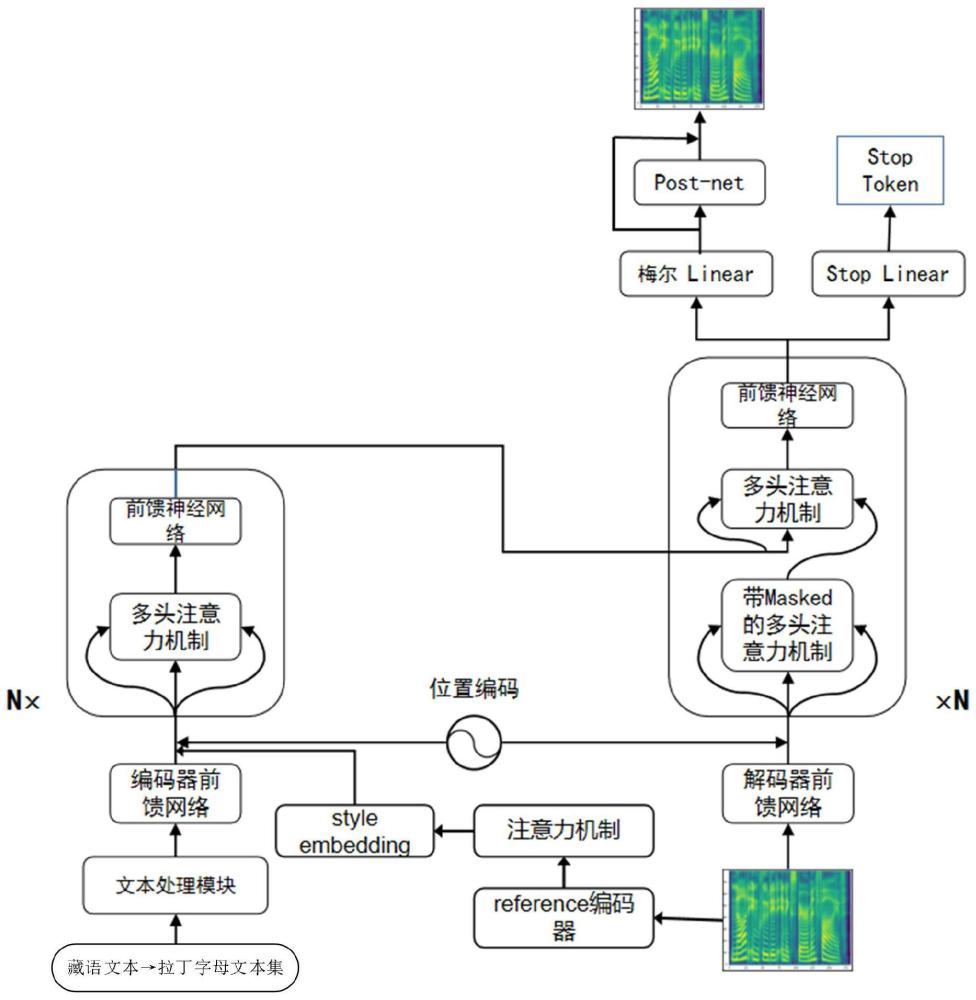
6、将gst中的reference encoder和注意力机制模块引入transformer模型,构建藏语语音合成模型,将所述拉丁字母文本集以及所述语音梅尔频谱图集输入到所述藏语语音合成模型进行训练,得到训练好的藏语语音合成模型;
7、将一段待合成的语音及文本作为训练好的藏语语音合成模型的输入,输出合成的语音梅尔谱。
8、可选的,获取不同藏语文本,并将所述藏语文本分别转写成拉丁字母,得到拉丁字母文本集,包括:
9、采用威利转写将藏语文本中的每个藏文字母和拉丁字母一一对应,按照藏语文本的书写顺序排列拉丁字母,其中,去掉藏语文本中的结束符,并用空格替换字分隔符,得到拉丁字母文本集。
10、可选的,所述藏语语音合成模型包括:
11、编码器模块、解码器模块、reference编码器、位置编码和post-net网络层;
12、其中,将所述拉丁字母文本集传递给所述编码器模块,通过所述编码器模块进行卷积、批处理、归一化、relu激活以及dropout操作,最终的relu激活后由所述位置编码保持中心一致性,得到一个文本嵌入text embedding;
13、同时,输入的语音梅尔频谱图集经过所述reference编码器,通过所述reference编码器提取说话人的个性特征,通过与文本嵌入text embedding加和实现说话人特征嵌入;
14、同时,输入的语音梅尔频谱图集传递给所述解码器模块,经过所述解码器模块得到带有新语音特征的梅尔谱,再经过所述post-net网络层得到带有说话人特征嵌入的个性化藏语语音梅尔谱。
15、可选的,所述编码器模块包括:编码器前馈网络和第一自注意力机制运算块;
16、所述编码器前馈网络的输入是拉丁字母文本集,所述编码器前馈网络包括:三层卷积层,归一化层、relu激活层以及一个dropout层;
17、所述第一自注意力机制运算块包括6层相同的第一子模块堆叠,每个第一子模块的结构相同,均包括多头自注意力层和前馈神经网络层。
18、可选的,所述解码器模块包括解码器前馈网络和第二自注意力机制运算块;
19、所述解码器前馈网络的输入是语音梅尔频谱图集,所述解码器前馈网络包括两层全连接神经网络,其中,第一层网络以relu为激活函数做非线性运算,第二层没有激活函数;
20、所述第二自注意力机制运算块包括6层相同的第二子模块堆叠,每个第二子模块的结构相同,均包括多头自注意力层、前馈神经网络层以及带masked标记的多头注意力层。
21、可选的,所述reference编码器包括:卷积神经网络cnn和门控循环神经网络gru,所述卷积神经网络包括二维卷积层;
22、其中,将语音梅尔频谱图集传递给具有3×3卷积核、2×2步长、batch归一化和relu激活函数的6个二维卷积层,分别为6个卷积层使用32、32、64、64、128和128个输出通道,得到的输出张量是3维,然后传入到单层128单元单向gru中,将不同长度音频信号的韵律压缩为固定长度向量,生成参考嵌入referenceembedding。
23、可选的,所述位置编码的计算表达式为:
24、
25、
26、式中,pos是时间步长索引,2i和2i+1是通道数,dmodel是每一帧的矢量大小。
27、可选的,所述第一自注意力机制运算块和所述第二自注意力机制运算块学习参考嵌入referenceembedding和随机初始化嵌入库中每个令牌之间的相似度,其中,每组嵌入embedding用令牌嵌入tokenembeddings表示,在所有训练序列中共享,输出一组组合权重,表示每个风格标记对参考嵌入reference embedding的贡献,所述组合权重用风格嵌入style embeddings表示,并传递给所述模块编码器。
28、可选的,所述藏语语音合成模型使用多头自注意力机制计算注意力权重,得到元素之间的相关性,包括:
29、s100:设拉丁字母文本集里的一段文本序列为x,将序列x的每一个词所对应的向量进行初步的嵌入embedding,得到向量ai;
30、s200:通过所述第一自注意力机制运算块和所述第二自注意力机制运算块中的线性网络层,使用三个矩阵分别与向量ai相乘,所述三个矩阵为一个输入特征矩阵和两个权重特征矩阵,得到对应的查询向量q、键向量k、值向量v;
31、s300:用查询向量q与转置后的k计算向量点积;
32、s400:经过所述第一自注意力机制运算块和所述第二自注意力机制运算块中的softmax层,得到0-1之间的注意力权重值;
33、s500:所述注意力权重值与值向量v相乘,得到每一个自注意力层的权重值;
34、s600:按照s100-s500将原始的输入序列进行多组的自注意力处理,每个注意力生成不同网络参数值的查询向量q、键向量k、值向量v,每个注意力头的输出进行拼接,并映射到固定维度向量空间;
35、其中,自注意力机制权重的计算公式为:
36、
37、式中,dk表示维度。
38、一种基于transformer的个性化藏语语音合成系统,包括:
39、文本处理模块:获取不同藏语文本,并将所述藏语文本分别转写成拉丁字母,得到拉丁字母文本集;
40、音频处理模块:获取不同的音频数据,分别通过给定的说话人语音提取出说话人特征,得到语音梅尔频谱图集;
41、模型训练模块:将gst中的reference encoder和注意力机制模块引入transformer模型,构建藏语语音合成模型,将所述拉丁字母文本集以及所述语音梅尔频谱图集输入到所述藏语语音合成模型进行训练,得到训练好的藏语语音合成模型;
42、语音合成模块:将一段待合成的语音及文本作为训练好的藏语语音合成模型的输入,输出合成的语音梅尔谱。
43、经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于transformer的个性化藏语语音合成方法及系统,将gst(global style token)中的reference encoder和style token网络加入到transformer模型架构中,将情感、韵律等方面的学习加入到模型训练的特征提取中,得到了一种功能较完备,效果较好的端到端个性化藏语语音合成模型。在合成过程中,基于训练好的藏语语音合成模型,输入藏语拉丁字母文本以及个性化目标语音,输出一段自然度较高、与目标语音相似度较高、与输入藏语文本匹配度较高的个性化藏语语音。最后通过评估印证了本发明模型在个性化藏语语音合成上的优秀表现。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24103.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表