一种基于发音指导的语音识别文本纠错方法
- 国知局
- 2024-06-21 11:52:11
本发明涉及一种基于发音指导的语音识别文本纠错方法,属于语音识别后处理领域。
背景技术:
0、技术背景
1、语音识别纠错对提升自动语音识别(asr)系统的识别准确率有着重要作用。asr系统将语音在转录成文本时,受不同说话人口音、周围环境等因素的影响,导致转录文本中会出现错误,常出现同音字、近音字等的识别错误,而语音识别文本纠错被视为提高识别准确性和可读性的关键技术。
2、与机器翻译相类似,主流的纠错模型通常被视为一种序列到序列的任务,其中各种asr识别错误的原始句子被视为源输入,输出是相应纠正后的句子。然而,基于序列到序列的方法经常遇到过度纠正的问题,即模型往往会错误地修改正确的识别结果,或是生成的校正结果与原本的发音或语义不符,造成歧义现象。
3、此外,asr系统的词错误率通常较低(通常低于10%),表明输入到纠错模型的句子与输出解雇偶具有相当大的重叠,且asr识别错误主要是同音替换错误,伴随着小部分插入和删除错误。因此,确保序列到序列纠错模型生成的文本不仅能够保留语义,更符合发音相似性是至关重要的。最近的研究提出了序列到编辑方法,结合了序列标记和序列生成任务,该类方案设计了一个错误检测器,用于预测纠正操作(即保留、删除、替换或插入),以引导和限制纠正器在纠正过程中的行为。此外,基于编辑距离的方案设计了一个长度预测器,用于弥合输入序列和目标序列之间的长度不匹配,预测的长度指示了编辑操作发生的位置。序列到编辑的方法为纠正模型提供了额外的监督信号,使其能够更精细地控制纠正操作。然而,预测器的准确性严重影响了纠正性能,仅使用序列的一部分作为解码器的输入容易破坏原始句子的结构,并导致语义信息的丢失。
4、另一方面,也有研究关注将语音知识整合到错误校正模型中。从混淆集中生成纠正候选项,通过选择性地屏蔽与原始词相比没有类似发音或形状的候选项。但通过手工注释生成的混淆集在覆盖范围上存在局限性,仅过滤掉混淆集中不存在的字符可能会无意中忽略正确的候选项。前述方法将语音信息视为外部知识而非直接对纠正模型中的语音特征进行建模,这些方法在利用被纠正词的固有语音特征方面并不十分有效。
技术实现思路
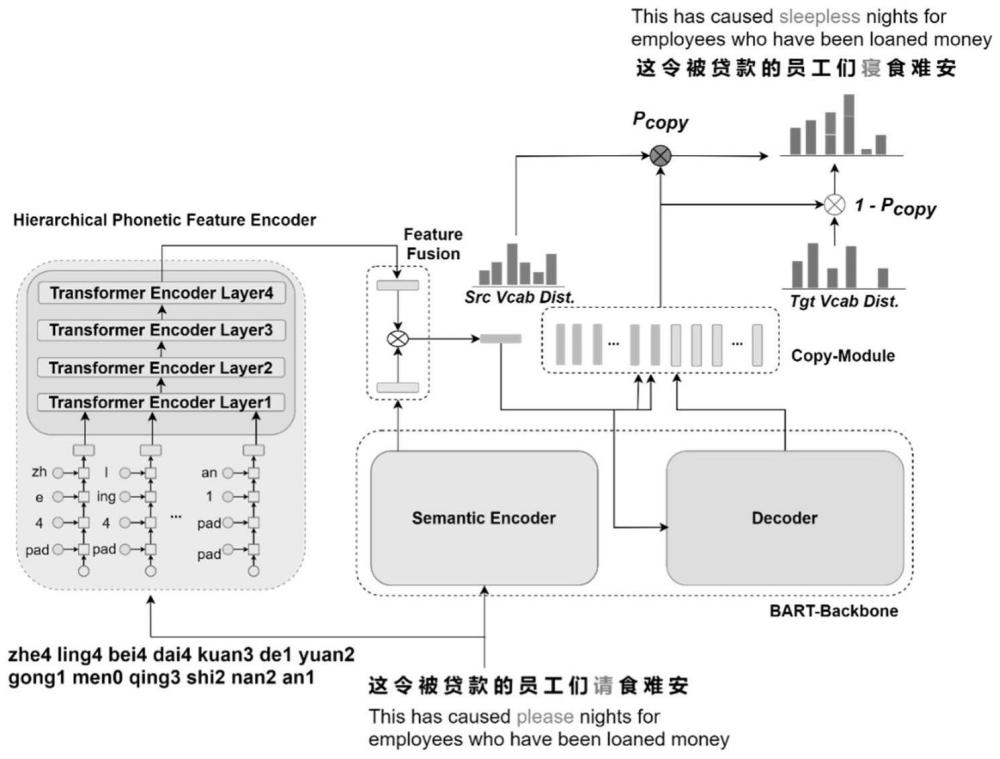
1、本发明要解决的技术问题是:本发明提供一种基于发音指导的语音识别文本纠错方法,对bart预训练模型的编解码器架构进行优化,充分利用bart在重构带噪或受损句子方面强大的修复能力,在bart预训练模型的基础上部加入了多粒度音韵特征编码器,分别在音节级别和句子级别提取拼音字母;加入发音指导的复制校正决策模块以控制模型是否从源句子中复制正确字符或生成新字符,从而引导模型生成符合发音和语义约束的正确候选词,从而缓解过度纠错的问题。
2、本发明的技术方案是:一种基于发音指导的语音识别文本纠错方法,所述方法包括如下:
3、step1、通过构建的多粒度发音特征编码模块从拼音序列中提取音节级和句子级的发音特征;
4、step2、发音和语义表征融合模块通过门控单元与bart编码器的最后一层隐藏状态进行融合,并将发音和语义表征融合特征输入至bart解码器和复制校正决策模块;
5、step3、复制校正决策模块以发音和语义表征融合特征以及来自bart解码器最后一层隐藏状态作为输入,通过多头注意力计算某个字符是否应当复制或校正的概率分布,最终根据概率分布对语音识别文本中的每个字符进行保持或校正。
6、进一步地,所述step1中包括:
7、所述多粒度发音特征编码模块由单向gru和四层双向transformer编码器组成;多粒度发音特征编码模块为捕捉不同声母、韵母和声调之间的发音异同,通过单层单向gru和四层双向transformer模块从拼音序列中分别提取音节级和句子级的发音特征;对于中文字符ci,其拼音序列表示为其中qi是ci的拼音序列长度,音节级的编码表示为:
8、
9、其中,emb(pi,j)是第j个拼音字母的嵌入,和分别表示来自gru网络的第j个和第j-1个隐藏状态;
10、句子级编码采用四层双向transformer块,将gru最后一个隐藏状态输出作为每个汉字的输入,并将位置嵌入作为输入,得到发音上下文表示为音标表示长度等于输入序列。
11、进一步地,所述step2中包括:发音和语义表征融合模块将从bart编码器输出的最后一层隐藏状态表征为语义,其中x是输入序列,emb(x)和pe(x)分别表示字符和位置嵌入函数;表示为:
12、hs=bartenc(emb(x)+pe(x))
13、为了融合发音和语义表示,设计了一个门控单元,让模型决定每个字符应该采用多少发音特征或语义特征;阈值大小由一个线性层计算,并通过sigmoid函数进行归一化:
14、
15、融合的特征更新表示为:
16、
17、为发音上下文表示为中的元素,i=1到n,在获得了增强的发音特征之后,将其送至bart解码器,同时也送至复制校正决策模块,以确定是否应将源输入句子中的字符复制到目标输出。
18、进一步地,所述step3包括如下:
19、最后一层解码器的隐藏状态是根据先前步骤step2以及得融合特征从解码器输出的,其中在解码步骤t处的输出dt被表示为:
20、
21、然后,通过以下方式计算目标词汇中所有标记的分布:
22、
23、概率分布pcopy表示是从源标记复制还是从生成的标记中获取,是通过多头注意力计算的,其中,dt是查询,hfuse是键和值;
24、
25、其中,ct是被关注的向量,αt是注意力权重,复制概率通过对ct和解码器隐藏状态dt的连接进行线性变换,然后使用sigmoid函数进行计算;
26、
27、在这里,是一个标量,用于加权复制概率,而1-pcopy则用于加权生成概率,解码器在步骤t的最终输出被表述为:
28、
29、最后,模型通过每个步骤t的目标真实标记yt的平均负对数似然进行优化:
30、
31、本发明的有益效果是:
32、本发明通过提供一种基于发音指导语音识别文本纠错方法,采用对受损句子有强大修复能力的bart为基础架构;构建多粒度发音特征编码器,指导复制校正决策模块和bart解码器识别错误出现的位置,以进行准确的校正;利用发音和语义表征融合模块,判断是从原句中复制还是生成新的字符。与现有的asr纠错方法相比,该发明在aishell-1测试集上实现了18%的改进,在magicdata上改进更加显著(44%)。表明该发明有较高的纠错精度,可有效缓解基于序列到序列的语音识别纠错模型中存在的过度纠错的问题。
技术特征:1.一种基于发音指导的语音识别文本纠错方法,其特征在于:所述方法包括如下:
2.根据权利要求1所述的基于发音指导的语音识别文本纠错方法,其特征在于:所述step1中包括:
3.根据权利要求1所述,一种基于发音指导的语音识别纠错模型,其特征在于:所述step2中包括:发音和语义表征融合模块将从bart编码器输出的最后一层隐藏状态表征为语义,其中x是输入序列,emb(x)和pe(x)分别表示字符和位置嵌入函数;表示为:
4.根据权利要求3所述的一种基于发音指导的语音识别纠错模型,其特征在于:所述step3包括如下:
技术总结本发明涉及基于发音指导的语音识别文本纠错方法;多粒度发音特征编码模块由单向GRU和四层Transformer编码器组成,从拼音序列中提取发音特征;发音和语义表征融合模块通过门控单元与BART编码器的最后一层隐藏状态进行融合,并将融合特征输入至BART解码器和复制校正决策模块;复制校正决策以发音和语义融合特征以及来自BART解码器最后一层隐藏状态作为输入,通过多头注意力计算某个字符是否应当复制或校正的概率分布,最终根据概率分布对语音识别文本中的每个字符进行保持或校正。本发明能有效降低语音识别词错率,有效缓解传统序列到序列纠错模型中存在的过度校正问题,提供更灵活的语音识别词错误检测和校正解决方案。技术研发人员:董凌,余正涛,高盛祥受保护的技术使用者:昆明理工大学技术研发日:技术公布日:2024/5/16本文地址:https://www.jishuxx.com/zhuanli/20240618/24120.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。