一种嘈杂环境下鲁棒的声纹消杂和识别系统及装置的制作方法
- 国知局
- 2024-06-21 11:52:49
本发明涉及语音信号处理,具体而言,涉及一种嘈杂环境下鲁棒的声纹消杂和识别系统及装置。
背景技术:
1、在实际生活中,因为人的发声器官实际上存在着大小、形态及功能上的差异。发声控制器官包括声带、软颚、舌头、牙齿、唇等;发声共鸣器包括咽腔、口腔、鼻腔。这些器官的微小差异都会导致发声气流的改变,造成音质、音色的差别,从而导致每个人说话都有自己的特点,同时,一般人成年后,人的说话特点会是长期相对稳定不变,可以说每个人有自己独无二的声纹信息,像指纹一样可以用来代表自己的身份。随着移动互联网的兴起,多数银行与用户的直接接触大大减少,随着大量业务线上化的普及,线上化、智能化、不得接触办理业务也暴露出更多的业务办理风险。身份冒用、盗用也层出不穷,给广大不能前往网点办理相关业务的人民群众带来不少的损失:冒名办理贷款或开通资金往来业务、盗用他人人脸等信息诈骗、小朋友以完成作业名义通过人脸识别转走余额用于购买游戏装备等。因此利用用户自身生物特征来确定其合法身份的方法开始得到主管部门和基层群的广泛关注,声纹识别技术就是生物识别技术中的一种,如何将声纹识别技术高效合理的应用于金融业务服务具有重要的意义。
2、声纹识别在背景环境比较安静时,声纹识别的准确率相对较高,但是实际使用的过程中,用户可能会处于比较嘈杂的环境,背景有干扰人声或者各种噪声等,这样声纹识别的准确率会大大下降,因此我们提出了一种嘈杂环境下鲁棒的声纹消杂和识别系统及装置。
技术实现思路
1、本申请提供了一种嘈杂环境下鲁棒的声纹消杂和识别系统及装置,以解决上述背景中提出的问题。
2、或者,
3、为了解决上述技术问题或者至少部分地解决上述技术问题。
4、为实现上述目的,第一方面,本发明实施例提供了一种嘈杂环境下鲁棒的声纹消杂系统,包括:
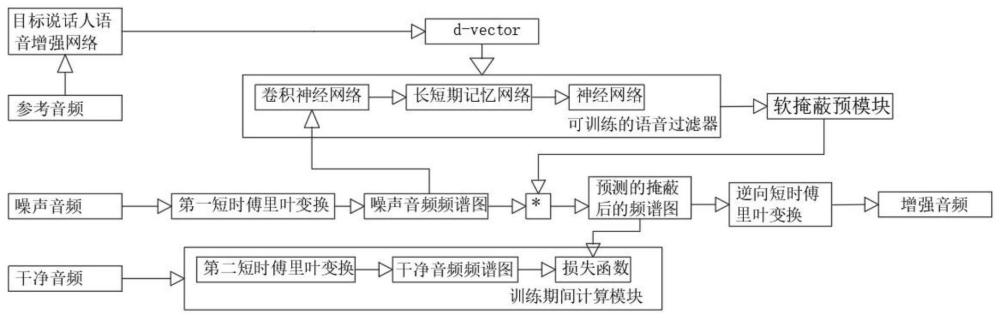
5、d-vector模块和噪声音频频谱图,所述d-vector模块输入端连接输入目标说话人语音增强网络,
6、所述噪声音频频谱图输入端输入经第一短时傅里叶变换处理的噪声音频,
7、且所述d-vector模块和所述噪声音频频谱图输出端连接可训练的语音过滤器,所述可训练的语音过滤器输出的语音通过软掩蔽预模块和逆向短时傅里叶变换处理后得到增强音频;
8、所述软掩蔽预模块处理后得到预测的掩蔽后的频谱图,所述预测的掩蔽后的频谱图还连接训练期间计算模块。
9、可选地,所述可训练的语音过滤器包括卷积神经网络、长短期记忆网络和神经网络,所述卷积神经网络、长短期记忆网络和神经网络依次相连。
10、可选地,所述目标说话人语音增强网络输入参考音频。
11、可选地,所述训练期间计算模块包括第二短时傅里叶变换、干净音频频谱图和损失函数,所述第二短时傅里叶变换、干净音频频谱图和损失函数依次相互连接,所述第二短时傅里叶变换输入端输入干净音频。
12、可选地,所述可训练的语音过滤器中的训练数据由50万组语音构成,且每组语音是由3条语音组成,分别是参考音频、噪声音频和干净音频,所述噪声音频是在干净音频的基础上加上干扰人声和噪声获得,所述参考音频和干净音频来自同一个声源。
13、第二方面,本发明实施例提供了一种嘈杂环境下鲁棒的声纹识别系统,包括:
14、用于采集增强音频的音频采集模块和处理音频的动态神经系统,
15、所述声纹识别处理步骤如下:
16、步骤一、所述音频采集模块采集增强音频信号,并提取增强音频信号的音频特征;
17、步骤二、所述音频特征经过动态神经系统处理,得到帧形式存在的声纹;
18、步骤三、所述帧形式存在的声纹经过统计汇总处理,得到均值数据和方差数据;
19、步骤四、均值数据和方差数据经过至少两层动态神经系统处理,得到声纹向量。
20、可选地,所述动态神经系统设有多个。
21、第三方面,本发明的实施例还提供了一种嘈杂环境下鲁棒的声纹消杂和识别装置,包括上述的嘈杂环境下鲁棒的声纹消杂系统和嘈杂环境下鲁棒的声纹识别系统;
22、所述嘈杂环境下鲁棒的声纹消杂系统处理后得到的增强音频输入嘈杂环境下鲁棒的声纹识别系统进行处理分辨得到声纹向量。
23、本发明的有益效果为:
24、通过设备的整体结构,创造性的提出了先进行语音增强,消除背景的各种噪声和干扰人声,然后再通过基于深度学习的声纹识别系统进行声纹识别,大大提高了声纹识别在背景嘈杂时的系统鲁棒性,且大大提高声纹在嘈杂环境的声纹识别准确率。
技术特征:1.一种嘈杂环境下鲁棒的声纹消杂系统,其特征在于,包括:
2.根据权利要求1所述的一种嘈杂环境下鲁棒的声纹消杂系统,其特征在于:所述可训练的语音过滤器包括卷积神经网络、长短期记忆网络和神经网络,所述卷积神经网络、长短期记忆网络和神经网络依次相连。
3.根据权利要求1所述的一种嘈杂环境下鲁棒的声纹消杂系统,其特征在于:所述目标说话人语音增强网络输入参考音频。
4.根据权利要求1所述的一种嘈杂环境下鲁棒的声纹消杂系统,其特征在于:所述训练期间计算模块包括第二短时傅里叶变换、干净音频频谱图和损失函数,所述第二短时傅里叶变换、干净音频频谱图和损失函数依次相互连接,所述第二短时傅里叶变换输入端输入干净音频。
5.根据权利要求1所述的一种嘈杂环境下鲁棒的声纹消杂系统,其特征在于:所述可训练的语音过滤器中的训练数据由50万组语音构成,且每组语音是由3条语音组成,分别是参考音频、噪声音频和干净音频,所述噪声音频是在干净音频的基础上加上干扰人声和噪声获得,所述参考音频和干净音频来自同一个声源。
6.一种嘈杂环境下鲁棒的声纹识别系统,其特征在于,包括:
7.根据权利要求6所述的一种嘈杂环境下鲁棒的声纹识别系统,其特征在于:所述动态神经系统设有多个。
8.一种嘈杂环境下鲁棒的声纹消杂和识别装置,包括权利要求1-7任一项所述的嘈杂环境下鲁棒的声纹消杂系统和嘈杂环境下鲁棒的声纹识别系统;
技术总结本发明涉及语音信号处理技术领域,具体而言,涉及一种嘈杂环境下鲁棒的声纹消杂系统,包括:d‑vector模块和噪声音频频谱图,所述d‑vector模块输入端连接输入目标说话人语音增强网络,所述噪声音频频谱图输入端输入经第一短时傅里叶变换处理的噪声音频,且所述d‑vector模块和所述噪声音频频谱图输出端连接可训练的语音过滤器,所述可训练的语音过滤器输出的语音通过软掩蔽预模块和逆向短时傅里叶变换处理后得到增强音频。通过设备的整体结构,创造性的提出了先进行语音增强,消除背景的各种噪声和干扰人声,然后再通过基于深度学习的声纹识别系统进行声纹识别,大大提高了声纹识别在背景嘈杂时的系统鲁棒性,且大大提高声纹在嘈杂环境的声纹识别准确率。技术研发人员:蒋世豪受保护的技术使用者:杭州屋屋科技有限公司技术研发日:技术公布日:2024/5/19本文地址:https://www.jishuxx.com/zhuanli/20240618/24211.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表