一种英语口语智能评估方法及系统
- 国知局
- 2024-06-21 11:53:02
本发明属于英语口语评估,具体是指一种英语口语智能评估方法及系统。
背景技术:
1、随着互联网技术和教育信息化的飞速发展,网上的英语口语资料越来越多,因此,需要一种英语口语智能评估方法及系统对英语口语资料的质量进行评估,从而为学习者选择出用于学习的高质量的英语口语资料。
2、但现有的英语口语智能评估方法及系统依然存在诸多缺陷:
3、1、在进行英语口语评估的过程中,现有方式通常仅对语音数据进行评估,却不涉及文本数据,从而导致现有的评估方式不能对英语口语的全部信息进行评估,使得评估结果的准确性较差。
4、2、在提取语音特征时,现有方式提取的语音特征过于单一,从而对评估过程带来不利影响。
技术实现思路
1、针对上述情况,为克服现有技术的缺陷,本发明提供了一种英语口语智能评估方法及系统,针对现有的评估方式不能对英语口语的全部信息进行评估,从而使得评估结果的准确性较差的技术问题,本方案同时对文本特征和语音特征进行提取,并创造性地将提取到的英语口语的文本数据的特征表示和英语口语的语音数据的特征表示应用于评估过程,在此过程中,通过英语口语的多模态融合评估模型对英语口语进行评估,能够充分考虑到文本数据和语音数据之间的关联性,从而得到更加准确和全面的评估结果,解决了现有的评估方式不能对英语口语的全部信息进行评估,从而使得评估结果的准确性较差的技术问题;在提取文本特征时,本方案通过cbow方法训练word2vec模型,并通过word2vec模型提取英语口语的文本数据的特征表示,在此过程中,本方案在词向量更新时创造性地引入分层softmax方法对上下文词汇的词向量进行更新,得到上下文词汇的词向量更新后的值,通过上述操作,使得文本特征的提取过程的速度更快,性能更好,且有效地提高了文本特征的提取过程的准确性;针对现有方式提取的语音特征过于单一,从而对评估过程带来不利影响的技术问题,本方案从多角度对语音数据进行特征提取,得到韵律特征和mfcc倒频谱特征,并将韵律特征和mfcc倒频谱特征作为英语口语的语音数据的特征表示,从而用于评估过程,解决了现有方式提取的语音特征过于单一,从而对评估过程带来不利影响的技术问题。
2、本发明采取的技术方案如下:本发明提供的一种英语口语智能评估方法,包括:
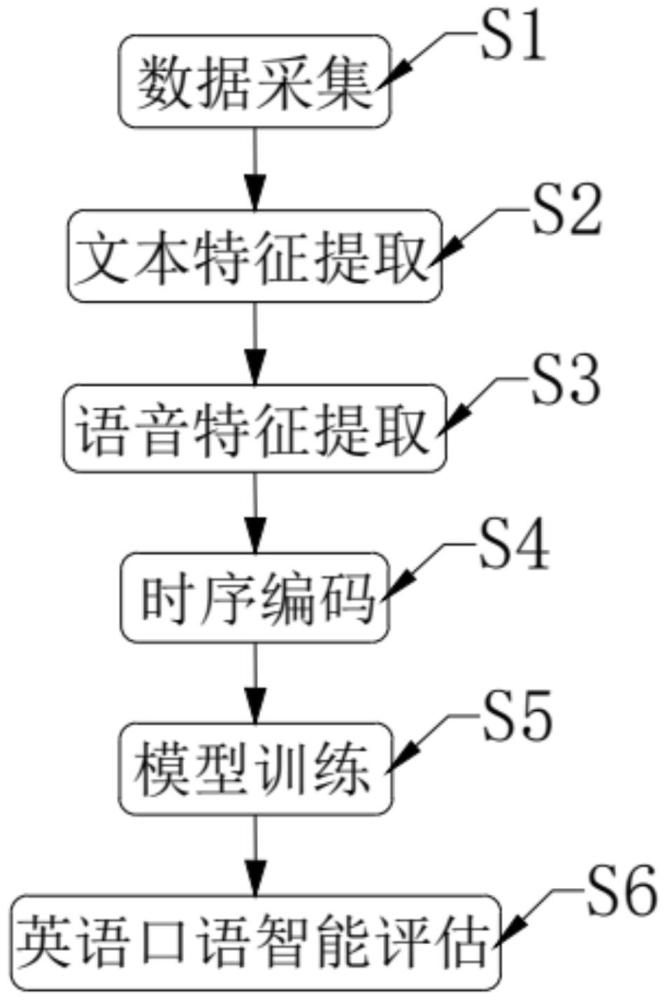
3、步骤s1:数据采集,具体为,收集英语口语的文本数据和英语口语的语音数据,并确保英语口语的文本数据和英语口语的语音数据的配对关系正确,构建英语口语数据集;
4、步骤s2:文本特征提取,具体为,通过cbow方法训练word2vec模型,并通过word2vec模型提取英语口语的文本数据的特征表示;
5、步骤s3:语音特征提取,具体为,对英语口语的语音数据进行特征提取,得到韵律特征和mfcc倒频谱特征,并将韵律特征和mfcc倒频谱特征作为英语口语的语音数据的特征表示;
6、步骤s4:时序编码,具体为,分别将英语口语的文本数据的特征表示和英语口语的语音数据的特征表示输入至两个独立的gru神经网络中,得到文本数据的最终隐藏状态和语音数据的最终隐藏状态,所述文本数据的最终隐藏状态为英语口语的文本数据的向量编码,所述语音数据的最终隐藏状态为英语口语的语音数据的向量编码;
7、步骤s5:模型训练,具体为,构建并训练英语口语的多模态融合评估模型,得到训练后的英语口语的多模态融合评估模型;
8、步骤s6:英语口语智能评估,具体为,根据训练后的英语口语的多模态融合评估模型对英语口语进行评估,得到英语口语评估结果。
9、作为本方案的进一步改进,在步骤s2中,所述文本特征提取的步骤,包括:
10、步骤s21:定义正负样本标签,具体为,遍历英语口语的文本数据中的所有词汇,将英语口语的文本数据中的一个词汇设置为目标词汇,将除目标词汇之外的词汇设置为上下文词汇,根据目标词汇和上下文词汇对正负样本标签进行定义,所用公式如下:
11、;
12、式中,表示上下文词汇,表示目标词汇,表示正负样本标签,当上下文词汇等于目标词汇时,正负样本标签为1,否则为0;
13、步骤s22:计算最大化正样本获得的概率,所用公式如下:
14、;
15、式中,表示目标词汇,表示最大化正样本获得的概率,表示正样本集合,即包含目标词汇的集合,表示负样本集合,即与目标词汇不相关的词汇集合,∏表示连乘运算符号,表示集合的并操作符号,表示从正样本集合和负样本集合中的选择的词汇n,表示给定目标词汇的上下文情境时的特定单词u出现的条件概率;
16、所述给定目标词汇的上下文情境时的特定单词u出现的条件概率的计算公式为:
17、;
18、式中,表示给定目标词汇的上下文情境时的特定单词u出现的条件概率,表示sigmoid函数,t表示矩阵转置,表示目标词汇,u表示特定词汇,表示特定词汇u的词向量的权重,表示目标词汇的上下文词汇的词向量的平均值的转置,表示正负样本标签,当时,正负样本标签为1,否则为0,表示上一个目标词汇的词向量的权重;
19、步骤s23:计算目标函数,所用公式如下:
20、;
21、式中,表示目标函数,表示自然对数函数,表示目标词汇,c表示上下文窗口,∑表示求和符号,表示目标词汇在上下文窗口c内,表示从正样本集合和负样本集合中的选择的目标词汇,表示正负样本标签,当时,正负样本标签为1,否则为0,表示sigmoid函数,t表示矩阵转置,表示特定词汇u的词向量的权重,表示目标词汇的上下文词汇的词向量的平均值的转置;
22、步骤s24:计算目标函数的偏导数一,所用公式如下:
23、;
24、式中,表示目标函数的偏导数一,即目标函数关于参数的偏导数,其中,表示给定目标词汇和上下文词汇时的目标函数,表示特定词汇u的词向量的权重,表示正负样本标签,当时,正负样本标签为1,否则为0,表示sigmoid函数,t表示矩阵转置,表示特定词汇u的词向量的权重,表示目标词汇的上下文词汇的词向量的平均值的转置,表示目标词汇的上下文词汇的词向量的平均值;
25、步骤s25:更新参数,具体为,对参数进行更新,所用公式如下:
26、;
27、式中,表示特定词汇u的词向量的权重,表示参数更新后的值,表示学习率,表示正负样本标签,当时,正负样本标签为1,否则为0,表示sigmoid函数,t表示矩阵转置,表示特定词汇u的词向量的权重,表示目标词汇的上下文词汇的词向量的平均值的转置,表示目标词汇的上下文词汇的词向量的平均值;
28、步骤s26:计算目标函数的偏导数二,所用公式如下:
29、;
30、式中,表示目标函数的偏导数二,即目标函数关于参数的偏导数,其中,表示给定目标词汇和上下文词汇时的目标函数,表示目标词汇的上下文词汇的词向量的平均值,表示正负样本标签,当时,正负样本标签为1,否则为0,表示sigmoid函数,t表示矩阵转置,表示特定词汇u的词向量的权重,表示目标词汇的上下文词汇的词向量的平均值的转置;
31、步骤s27:词向量更新,具体为,根据目标函数的偏导数二,并通过引入分层softmax方法对上下文词汇的词向量进行更新,所用公式如下:
32、,;
33、式中,表示上下文词汇的词向量,表示上下文词汇的词向量更新后的值,表示赋值符号,表示学习率,∑表示求和符号,表示目标函数的偏导数二,即目标函数关于参数的偏导数,其中,表示给定目标词汇和上下文词汇时的目标函数,表示目标词汇的上下文词汇的词向量的平均值,表示从正样本集合和负样本集合中的选择的特定词汇u,表示目标词汇的上下文窗口,表示上下文词汇属于目标词汇的上下文窗口;
34、步骤s28:输出特征表示,具体为,将上下文词汇的词向量更新后的值作为英语口语的文本数据的特征表示。
35、作为本方案的进一步改进,在步骤s3中,所述语音特征提取的步骤,包括:
36、步骤s31:语音数据预处理,具体为,依次对英语口语的语音数据进行预加重处理、分帧处理和加窗处理,得到预处理后的英语口语的语音数据;
37、步骤s32:韵律特征提取,具体为,从预处理后的英语口语的语音数据中提取韵律特征;
38、步骤s33:mfcc倒频谱特征提取,具体为,从预处理后的英语口语的语音数据中提取mfcc倒频谱特征;
39、在步骤s31中,所述语音数据预处理的步骤,包括:
40、步骤s311:预加重处理,具体为,对英语口语的语音数据进行预加重处理,以增加英语口语的语音数据的高频部分,并减小英语口语的语音数据的低频部分;
41、步骤s312:分帧处理,具体为,将英语口语的语音数据分成短时段的语音数据,得到每个帧的语音数据;
42、步骤s313:加窗处理,具体为,通过窗函数对每个帧的语音数据进行加窗处理,得到每个帧的加窗后的语音数据;所述窗函数包括汉明窗和汉宁窗;
43、在步骤s32中,所述韵律特征提取的步骤,包括:
44、步骤s321:计算能量,具体为,对每个帧的加窗后的语音数据进行平方运算,得到每个帧的语音数据的能量;
45、步骤s322:计算过零率,具体为,计算每个帧的语音数据的过零率;
46、步骤s323:计算基音周期,具体为,通过自相关函数计算每个帧的语音数据的基音周期;
47、在步骤s33中,所述mfcc倒频谱特征提取的步骤,包括:
48、步骤s331:频谱信息提取,具体为,对预处理后的英语口语的语音数据进行离散傅里叶变换,得到频谱信息;
49、步骤s332:能量谱转换,具体为,将频谱信息通过梅尔滤波器组转换为能量谱;
50、步骤s333:对数压缩,具体为,对能量谱进行对数压缩操作;
51、步骤s334:离散余弦变换,具体为,对对数压缩后的能量谱进行离散余弦变换,得到mfcc系数。
52、作为本方案的进一步改进,在步骤s5中,所述模型训练的步骤,包括:
53、步骤s51:计算文本数据的向量编码的关注权重,所用公式如下:
54、;
55、式中,表示文本数据的向量编码的关注权重,表示softmax激活函数,表示英语口语的文本数据的向量编码,表示英语口语的语音数据的向量编码,表示矩阵乘法运算符;
56、步骤s52:计算文本注意力向量编码,所用公式如下:
57、;
58、式中,ate表示文本注意力向量编码,表示第i个文本数据的向量编码的关注权重,te表示英语口语的文本数据的向量编码,i表示文本数据的向量编码的关注权重的索引,t表示文本数据的向量编码的关注权重的数量,∑表示求和符号;
59、步骤s53:计算多模态融合输出结果,所用公式如下:
60、;
61、式中,fe表示多模态融合输出结果,ate表示文本注意力向量编码,ae表示英语口语的语音数据的向量编码,表示对英语口语的语音数据的向量编码ae和文本注意力向量编码ate进行拼接操作;
62、步骤s54:计算多模态融合损失,所用公式如下:
63、;
64、式中,表示多模态融合损失,∑表示求和符号,i表示样本的索引,表示第i个样本的真实标签,表示英语口语的多模态融合评估模型对第i个样本的多模态融合输出结果,表示的自然对数;
65、步骤s55:反向传播,具体为,根据多模态融合损失计算英语口语的多模态融合评估模型参数的梯度,并根据英语口语的多模态融合评估模型参数的梯度对英语口语的多模态融合评估模型的权重和偏置进行更新;
66、步骤s56:参数优化,具体为,通过梯度下降算法更新英语口语的多模态融合评估模型的参数,以最小化多模态融合损失;
67、步骤s57:迭代训练,具体为,重复执行步骤s51~步骤s56,直至达到预先设置的迭代次数或达到收敛条件,得到训练后的英语口语的多模态融合评估模型。
68、本发明提供的一种英语口语智能评估系统,包括数据采集模块、文本特征提取模块、语音特征提取模块、时序编码模块、模型训练模块和英语口语智能评估模块;
69、所述数据采集模块,用于数据采集,具体为,收集英语口语的文本数据和英语口语的语音数据,并确保英语口语的文本数据和英语口语的语音数据的配对关系正确,构建英语口语数据集,并将英语口语数据集发送至文本特征提取模块和语音特征提取模块;
70、所述文本特征提取模块,用于文本特征提取,具体为,通过cbow方法训练word2vec模型,并通过word2vec模型提取英语口语的文本数据的特征表示,并将英语口语的文本数据的特征表示发送至时序编码模块;
71、所述语音特征提取模块,用于语音特征提取,具体为,对英语口语的语音数据进行特征提取,得到韵律特征和mfcc倒频谱特征,并将韵律特征和mfcc倒频谱特征作为英语口语的语音数据的特征表示,并将英语口语的语音数据的特征表示发送至时序编码模块;
72、所述时序编码模块,用于时序编码,具体为,分别将英语口语的文本数据的特征表示和英语口语的语音数据的特征表示输入至两个独立的gru神经网络中,得到文本数据的最终隐藏状态和语音数据的最终隐藏状态,所述文本数据的最终隐藏状态为英语口语的文本数据的向量编码,所述语音数据的最终隐藏状态为英语口语的语音数据的向量编码,并将发送至模型训练模块;
73、所述模型训练模块,用于模型训练,具体为,构建并训练英语口语的多模态融合评估模型,得到训练后的英语口语的多模态融合评估模型,并将训练后的英语口语的多模态融合评估模型发送至英语口语智能评估模块;
74、所述英语口语智能评估模块,用于英语口语智能评估,具体为,根据训练后的英语口语的多模态融合评估模型对英语口语进行评估,得到英语口语评估结果。
75、采用上述方案本发明取得的有益效果如下:
76、(1)针对现有的评估方式不能对英语口语的全部信息进行评估,从而使得评估结果的准确性较差的技术问题,本方案同时对文本特征和语音特征进行提取,并创造性地将提取到的英语口语的文本数据的特征表示和英语口语的语音数据的特征表示应用于评估过程,在此过程中,通过英语口语的多模态融合评估模型对英语口语进行评估,能够充分考虑到文本数据和语音数据之间的关联性,从而得到更加准确和全面的评估结果,解决了现有的评估方式不能对英语口语的全部信息进行评估,从而使得评估结果的准确性较差的技术问题。
77、(2)在提取文本特征时,本方案通过cbow方法训练word2vec模型,并通过word2vec模型提取英语口语的文本数据的特征表示,在此过程中,本方案在词向量更新时创造性地引入分层softmax方法对上下文词汇的词向量进行更新,得到上下文词汇的词向量更新后的值,通过上述操作,使得文本特征的提取过程的速度更快,性能更好,且有效地提高了文本特征的提取过程的准确性。
78、(3)针对现有方式提取的语音特征过于单一,从而对评估过程带来不利影响的技术问题,本方案从多角度对语音数据进行特征提取,得到韵律特征和mfcc倒频谱特征,并将韵律特征和mfcc倒频谱特征作为英语口语的语音数据的特征表示,从而用于评估过程,解决了现有方式提取的语音特征过于单一,从而对评估过程带来不利影响的技术问题。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24246.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表