OWS耳机的语音增强方法、系统、耳机及存储介质与流程
- 国知局
- 2024-06-21 11:53:14
本发明涉及语音增强,尤其涉及一种ows耳机的语音增强方法、系统、耳机及存储介质。
背景技术:
1、在通信时,噪声和回声将严重影响通信语音的清晰度和可懂度,并且,当噪声高到一定程度时,不但通信无法进行,而且会对人的听力和身心健康产生伤害。因此,为了保证用户佩戴耳机时的通话质量,ows耳机中往往会利用语音增强技术对近端远端进行语音数据的处理和优化。
2、现如今,由于难以准确地估计和建模噪声特性、对语音分布假设的不准确性、无法获取所有样本数据以及算法复杂度较高等因素,常常导致语音增强后的语音信号失真度较高。
3、因此,在进行语音增强时,如何降低语音信号的失真度,是本领域技术人员尚待解决的技术问题。
技术实现思路
1、本发明提出一种oes耳机的语音增强方法、系统、耳机及存储介质,旨在降低语音信号的失真度。
2、为实现上述目的,本发明提出一种ows耳机的语音增强方法,所述ows耳机的语音增强方法应用于ows耳机,所述ows耳机的前腔出音嘴设置于与用户耳道对应的位置,所述ows耳机的后腔出音嘴设置于耳挂下方,所述ows耳机的主麦克风设置于话务杆内,所述ows耳机的次麦克风设置于耳机侧面;
3、所述ows耳机的语音增强方法包括:
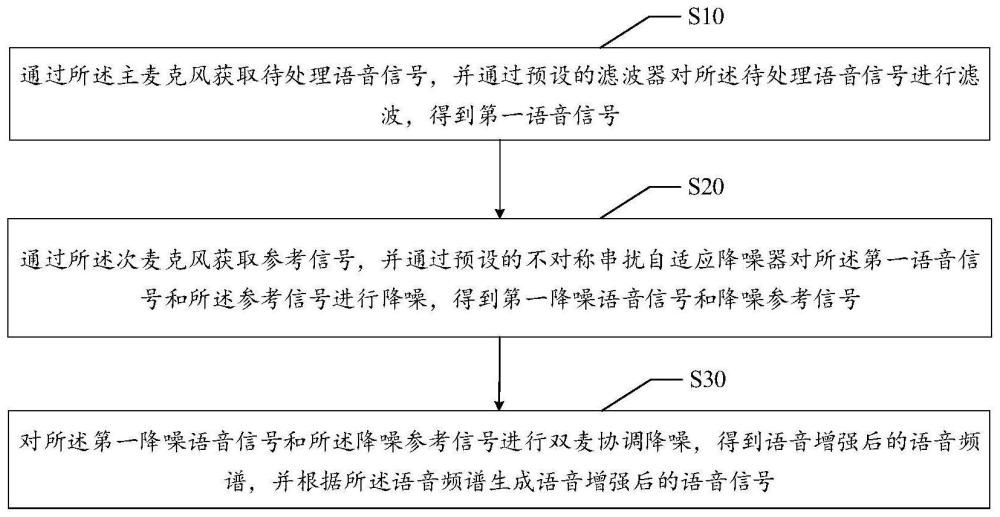
4、通过所述主麦克风获取待处理语音信号,并通过预设的滤波器对所述待处理语音信号进行滤波,得到第一语音信号;
5、通过所述次麦克风获取参考信号,并通过预设的不对称串扰自适应降噪器对所述第一语音信号和所述参考信号进行降噪,得到第一降噪语音信号和降噪参考信号;
6、对所述第一降噪语音信号和所述降噪参考信号进行双麦协调降噪,得到语音增强后的语音频谱,并根据所述语音频谱生成语音增强后的语音信号。
7、可选地,在所述通过预设的滤波器对所述待处理语音信号进行滤波,得到第一语音信号的步骤之前,所述方法还包括:
8、获取预设的滤波器的系数更新模型,其中,所述系数更新模型包括目标滤波器系数与步长因子、当前滤波器系数的映射关系;
9、基于当前实际滤波器系数、实际步长因子、所述映射关系,计算实际目标滤波器系数,并按照所述实际目标滤波器系数对所述滤波器的系数进行更新。
10、可选地,在所述对所述第一降噪语音信号和所述降噪参考信号进行双麦协调降噪,得到语音增强后的语音频谱的步骤之前,所述方法还包括:
11、对所述第一降噪语音信号进行加窗、快速傅里叶变换处理,并对所述降噪参考信号进行加窗、快速傅里叶变换处理。
12、可选地,双麦协调降噪包括:时间差异计算、噪声估计和频域滤波,所述对所述第一降噪语音信号和所述降噪参考信号进行双麦协调降噪,得到语音增强后的语音频谱的步骤,包括:
13、确定所述第一降噪语音信号的第一交叉功率谱密度、确定所述降噪参考信号的第二交叉功率谱密度和确定所述第一降噪语音信号和所述降噪参考信号的第三交叉功率谱密度;
14、对所述第一交叉功率谱密度和所述第二交叉功率谱密度进行时间差异计算,得到时间差异值;
15、根据所述时间差异值和所述第三交叉功率谱密度进行噪声估计,得到噪声密度;
16、将所述第一交叉功率谱密度、所述第二交叉功率谱密度、所述第三交叉功率谱密度、所述噪声密度输入预设的滤波器模型中,得到频域滤波器;
17、根据所述频域滤波器对所述第一降噪语音信号进行滤波,得到语音增强后的语音频谱。
18、可选地,所述根据所述语音频谱生成语音增强后的语音信号的步骤,包括:
19、对所述语音频谱进行逆快速傅里叶变换,得到时域信号,并对所述时域信号进行加窗、重叠长度分析,以得到语音增强后的语音信号。
20、可选地,所述根据所述语音频谱生成语音增强后的语音信号的步骤,包括:
21、对所述语音信号进行基音检测,得到所述语音信号的基音频率,并计算所述基音频率的过零率;
22、在检测到所述过零率大于或者等于预设阈值时,则对所述语音信号进行补偿,以增强语音信号。
23、可选地,所述对所述语音信号进行补偿的步骤,包括:
24、通过预设的权值滤波器对所述语音信号的所述基音频率的倍频进行同相位谐波补偿;
25、获取所述语音信号的平均幅度,并通过与所述平均幅度对应预设的补偿滤波器对所述语音信号进行幅度补偿。
26、此外,本发明还提出一种ows耳机的语音增强系统,所述ows耳机的语音增强系统应用于ows耳机,所述ows耳机的前腔出音嘴设置于与用户耳道对应的位置,所述ows耳机的后腔出音嘴设置于耳挂下方,所述ows耳机的主麦克风设置于话务杆内,所述ows耳机的次麦克风设置于耳机侧面;
27、所述ows耳机的语音增强系统包括:
28、回声消除模块,用于通过所述主麦克风获取待处理语音信号,并通过预设的滤波器对所述待处理语音信号进行滤波,得到第一语音信号;
29、能量均衡模块,用于通过所述次麦克风获取参考信号,并通过预设的不对称串扰自适应降噪器对所述第一语音信号和所述参考信号进行降噪,得到第一降噪语音信号和降噪参考信号;
30、双麦协调降噪模块,用于对所述第一降噪语音信号和所述降噪参考信号进行双麦协调降噪,得到语音增强后的语音频谱,并根据所述语音频谱生成语音增强后的语音信号。
31、此外,本发明还提出一种ows耳机,所述ows耳机包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的ows耳机的语音增强程序,所述ows耳机的语音增强程序被所述处理器执行时实现如上所述的ows耳机的语音增强方法的步骤。
32、此外,本发明还提出一种存储介质,所述存储介质上存储有ows耳机的语音增强程序,所述ows耳机的语音增强程序被处理器执行时实现如上所述的ows耳机的语音增强方法的步骤。
33、在本发明实施例中,所述ows耳机的前腔出音嘴设置于与用户耳道对应的位置,所述ows耳机的后腔出音嘴设置于耳挂下方,所述ows耳机的主麦克风设置于话务杆内,所述ows耳机的次麦克风设置于耳机侧面。本发明通过所述主麦克风获取待处理语音信号,并通过预设的滤波器对所述待处理语音信号进行滤波,得到第一语音信号,能够在通过前腔出音嘴设置于耳道相对的位置,后腔出音嘴设置于耳挂下方位置以去除低频信号的回声基础上,通过滤波器对待处理语音信号的中高频信号进行回声消除;然后通过所述次麦克风获取参考信号,并通过预设的不对称串扰自适应降噪器对所述第一语音信号和所述参考信号进行降噪,得到第一降噪语音信号和降噪参考信号,能够将主麦克风采集的信号与次麦克风采集的信号的能量进行平衡,以提高降噪精度;然后对所述第一降噪语音信号和所述降噪参考信号进行双麦协调降噪,得到语音增强后的语音频谱,并根据所述语音频谱生成语音增强后的语音信号,能够基于主次麦克风的空间位置差异和语音与噪声的相关性假设进行高精度降噪,可以更精确地分离和抑制噪声,从而降低语音信号的失真度。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24278.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表