一种用于控制车辆功能单元的方法、设备和计算机程序产品与流程
- 国知局
- 2024-06-21 11:53:10
本发明涉及一种从用户语音的声音信号序列中确定多部分关键词的方法和设备。
背景技术:
1、us2018/0342237 a1中公布了一种识别关键词的方法,在该方法中,在一种设备上接收音素序列并确定关键词。只要确定了关键词,声音信号序列就会发送至一台外部服务器上。下一步,该外部服务器会接收该声音信号序列生成的文本,并检查该文本是否与关键词匹配。
技术实现思路
1、本发明的目的是提供一种可供选择的识别方法和设备,特别是用于识别由两部分组成的关键词。
2、该目的可通过一种具有权利要求1所述特征的方法和一种根据权利要求8的设备实现。从属权利要求定义了本发明的优先实施例和有利实施例。
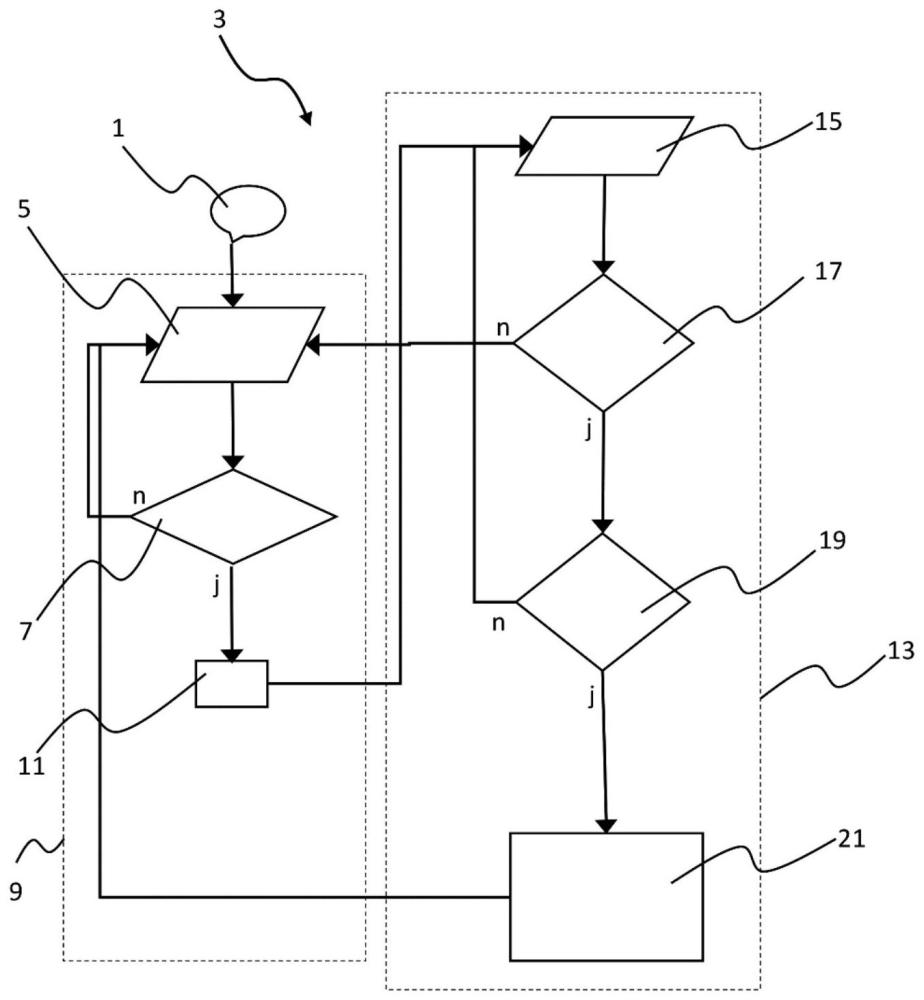
3、根据本发明的方法,在第一步、或者说第一搜索阶段,将检查所接收到的声音信号序列是否存在关键词的第一部分。其中,用户发出的声音流被转换成声音信号流,即声音信号序列,该声音信号序列会与对比信号序列进行比较。
4、只有当识别出关键词的第一部分时,才会在下一步、即第二搜索阶段,检查该声音信号序列是否存在关键词的第二部分,只有当第二部分也被识别出来时,语音控制系统才会被激活。因此,在识别由两部分组成的关键词时,首先要在声音信号序列中搜索关键词的第一部分(也称为区分词),一旦识别出这一部分,就只在一定的时间和数据量范围内搜索关键词的第二部分(也称为主体词)。激活语音控制系统包括一个操作;例如,在识别关键词后,会触发一项车辆功能或者开启一个对话,其中,会通过娱乐系统询问用户想要激活哪些服务、功能,或者想要了解哪些信息。因此,执行操作也意味着从语音控制系统向其他控制系统发送指令,以操作车辆功能。通过分两步识别关键词,可以减少由于在与激活意图不同的语境中使用关键词、或者关键词的部分内容导致的经常出现的错误识别。识别关键词的第一部分和第二部分总是有一定的错误率。如果必须分开对这两个部分各自进行识别,那么这个错误率会比将关键词作为整体进行识别时低得多。例如,如果关键词第一部分的错误率为0.2,关键词第二部分的错误率为0.1,那么总错误率就是0.02。相比之下,将关键词作为整体进行识别的错误率就要高得多,例如0.1。因此,分阶段对关键词的各个部分进行识别比对整个关键词进行识别的错误率要低。
5、在一个改进的实施例中,只要声音信号序列与第一个和第二个已存储的对比信号序列的相似值高于预定阈值,那么关键词的第一部分和第二部分就会被确认为已识别。该相似值可使用现有技术中已知的字符串距离算法来确定,例如最小编辑距离。
6、在另一个实施例中,输入的声音信号序列中连续、相同的声音信号会被视作单个声音。由此带来的好处是,可以使一个单词中单个发音(例如,元音)不同的发音持续时间得到平衡,并减少对关键词的错误识别。
7、在本发明的一个改良例中,在识别出关键词第一部分之后的一段预设时间之后,将会停止对第二部分的检查,而继续进行对第一部分的搜索。确定这段时间时,应确保即使是说得很慢的关键词第二部分也不会因为超过预定时间而被取消。这样做的好处是,如果用户在念完关键词的第一部分后停顿了一下,随后不小心念出了与关键词第二部分相对应的单词,那么就可以避免将该单词解释为关键词,并避免意外激活语音控制系统。通过该取消操作,就可以去识别新说出的多部分关键词。
8、根据本发明的另一个附加的或替代的实施例,输入的声音信号将在存储器中持续缓冲,其中,自关键词的第一部分被识别出起,就确定了储存在缓冲器中的声音信号数量。如果存储的声音信号数量达到预设的限度(即上限),例如只要关键词的第一部分从设计为环形缓冲器的存储缓冲器中移出,那么就会停止对关键词第二部分的搜索,并重新开始对第一部分的搜索。只要第一部分再次被识别,那么就会再次对存储的声音信号数量进行计算,直至达到上限。
9、这样做的好处是,由此可以避免在有意甚至是无意地说出关键词的第一部分之后,根据已经由用户随口说出的话和环境噪音导致的、储存入缓冲储存器的声音,将一个随机说出的、与关键词第二部分相对应的单词错误地识别为属于关键词的第一部分,并导致意外的激活。
10、在一个更好的改良例中,在预设的时间结束后,或在存储的声音信号数量达到上限后,将立即停止对关键词第二部分的搜索,这取决于首先达到了哪项标准。这两种取消标准的应用可以使该方法自由地适应说话者的习惯,从而实现对关键词的最佳识别。
11、根据本发明的另一个实施例,关键词的第二部分总是在最新的关键词第一部分之后确定。在第二搜索阶段,关键词的第二部分将在最新的关键词第一部分之后在环形缓冲器中进行搜索。最新的关键词第一部分是指环形缓冲器中与当前时间最接近的第一部分。如果环形缓冲器中存储的声音信号数量已达到上限,以及/或者计时器到期(即,预设时间已过),则将继续检查关键词的第一部分。否则,系统将停留在搜索关键词第二部分之后的阶段,并在当前环形缓冲器中重新开始搜索最新的关键词第一部分之后的第二部分。换言之,如果在搜索第二部分的过程中识别出了第一部分,定时器将被重置,并且/或者环形缓冲器中存储的声音信号数量将重新累计直至上限,然后从最后找到的第一部分开始,在下一个步骤中再次搜索关键词的第二部分。通过重置计时器和/或已存储声音信号的计数数量,取消搜索关键词第二部分(该第二部分与最近的第一部分有关)的概率会显著降低,即在语音输入过程中取消搜索关键词第二部分的可能性会显著降低。
12、如果在搜索后又先找到了关键词的第一部分,则重复该方法,即再次重置计时器,最好是重新计数要存储在环形缓冲器中的声音信号,并进一步搜索关键词的第二部分。重复实施该方法,直到识别出关键词第一部分之后的关键词第二部分,或者计时器计时结束,并且/或者环形缓冲器中存储的声音信号数量达到预设的上限。在第一搜索阶段,搜索关键词的第一部分;在第二搜索阶段,同时搜索关键词的第一部分和第二部分。
13、这样做的好处是,如果用户在说出关键词的第一部分后取消或暂停,并在不久后重复输入由两部分组成的关键词,那么这种情况下就能提高多部分关键词的识别率。
14、根据该方法的另一个实施例,会对输入的声音信号序列进行梳理,具体方法是在声音信号上设置一个连续的观察窗口期,并且只将处于观察窗口期内的、数量超过预设频率阈值的声音信号用于检查。其中,这些窗口期大于由控制单元循环检测的声音信号。例如,会对所有10毫秒的声音信号进行循环检测,也就是说,在识别质量完好的理想情况下,每个持续一定时间的声音都会一个接一个地反复存储在缓冲器中。其中,该观察窗口期可以是50毫秒。现在要确定的是,在观察窗口期中确定的信号是稳定的还是剧烈波动的。如果该信号是稳定的,即在观察窗口期中识别到的相同声音信号的数量超过了预设的频率阈值,那么可以认为对该声音信号的识别是可靠的。如果达不到该频率阈值,那么观察窗口期中的信号就会由于识别质量不高而被舍弃。这样做的好处是,减少了关键词第一部分和第二部分的识别错误。
15、根据本发明所述的设备包含用于接收声音信号序列的装置,其中
16、-这些装置会检查该声音信号序列是否存在关键词的第一部分,并且只有第一部分被识别时
17、-这些装置会检查声音信号序列中是否存在关键词的第二部分,并且只有第二部分被识别时
18、-这些装置会激活语音控制系统。
19、根据本发明所述的设备能够对多部分关键词进行识别。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24269.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表