一种基于语音信号的全自动腺样体和扁桃体肥大识别系统
- 国知局
- 2024-06-21 11:53:07
本发明属于腺样体和扁桃体肥大筛查,具体涉及一种全自动腺样体和扁桃体肥大识别系统。
背景技术:
1、腺样体(也被称为咽扁桃体)是位于鼻腔后方的淋巴组织;扁桃体(医学中通常指代腭扁桃体)位于舌腭弓和咽腭弓之间的扁桃体窝中[1]。腺样体肥大是指咽扁桃体的病理性增大;扁桃体肥大是指腭扁桃体的病理性增大。腺样体和扁桃体肥大在儿童中普遍存在,腺样体和扁桃体肥大是导致儿童患有阻塞性睡眠呼吸暂停(obstructive sleep apnea,osa)最常见的原因[2]。腺样体和扁桃体肥大不仅会引起患儿鼻塞、睡觉打鼾、张口呼吸、颌面发育畸形等,还可能造成患儿生长发育停滞。因此,早诊断、早治疗极为重要。
2、临床上可以使用多种方法来诊断腺样体和扁桃体的肥大程度,目前使用最广泛的方法是鼻咽侧位片和鼻内镜检查[3]。鼻咽侧位片通过腺样体鼻咽比值,即a/n,其中a为腺样体的绝对大小,n为鼻咽间隙的大小。具体来说,可将腺样体分为正常(a/n≤0.60)、轻度肥大(0.60<a/n≤0.70)、中度肥大(0.70<a/n≤0.80)和重度肥大(a/n>0.80)[4]。鼻内镜检查可以很直观的看到腺样体和扁桃体,配合专业医师的临床诊断可以比较有效的判断出腺样体和扁桃体的肥大程度。虽然头颅侧位片和鼻内镜检查可以比较有效的诊断腺样体和扁桃体的肥大程度,但是它们都存在比较明显的缺点。例如,为了得到准确的a/n值,放射科医生需要在头颅侧位上标记坐标点,这个过程耗时且繁琐。鼻内镜检查依赖于医生的主观判断,缺乏客观指标。此外,临床上也可以使用三维影像(比如cbct)来进行腺样体和扁桃体肥大的诊断。在三维影像,除了可以计算a/n值外,还可以通过测算气道容积、最小截面积来评估腺样体、扁桃体肥大程度。但是该技术与鼻内镜支持的腺样体肥大评估参考标准没有很好的相关性,且其测量方法和评判标准尚不成熟。
3、由于扁桃体和腺样体都位于声道内,它们通过阻碍声音产生的空气空间来改变声音的质量,且有研究证明了患者在进行腺样体和扁桃体切除手术前后,其声学特征差异具有统计学意义[5]。研究表明,腺样体和扁桃体肥大患者相对于正常人的语音信号可能存在异常,然而是否可以根据语音信号实现腺样体和扁桃体肥大的辅助诊断仍有待探索。
技术实现思路
1、针对上述现有技术的不足,本发明的目的在于提出一种精确、可靠、无创的全自动腺样体和扁桃体肥大识别系统。
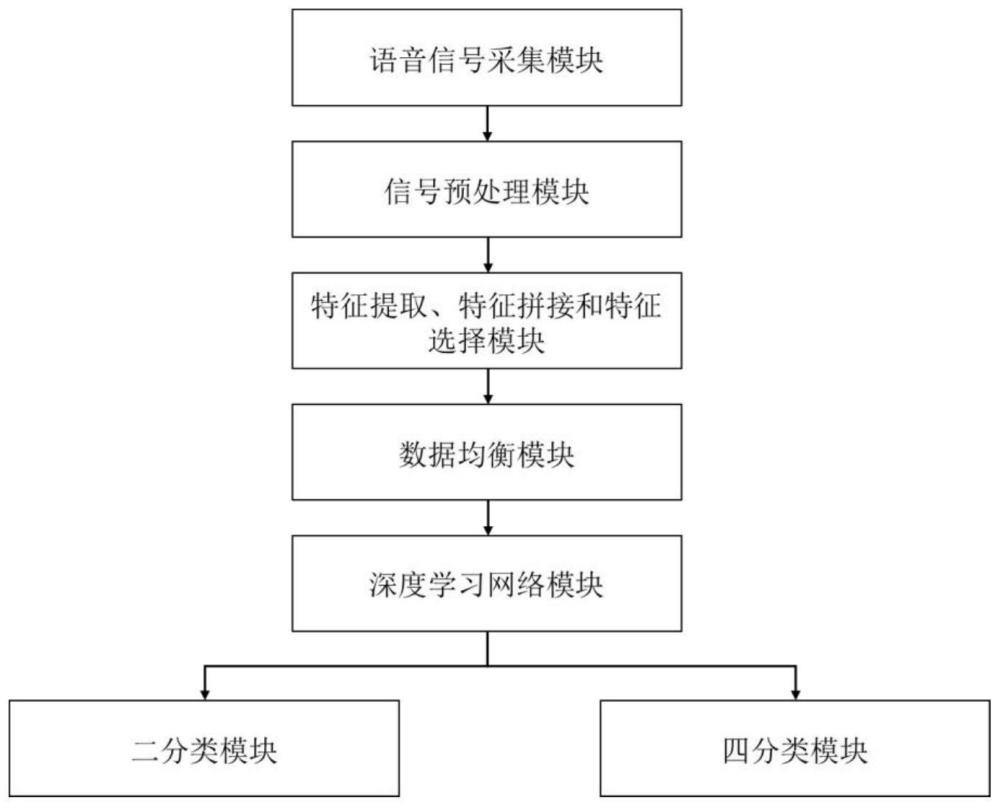
2、本发明提供的全自动腺样体和扁桃体肥大识别系统,通过对采集到的语音信号进行预处理、特征提取、特征拼接与选择,最后送入深度学习网络进行腺样体和扁桃体肥大患者识别及腺样体和扁桃体肥大程度判别。
3、本发明提供的全自动腺样体和扁桃体肥大识别系统,是基于中文语音信号的,具体包括以下模块:语音信号采集模块,信号预处理模块,特征提取、特征拼接和特征选择模块,数据均衡模块,深度学习网络模块,二分类模块,四分类模块;其中:
4、所述语音信号采集模块,用于采集受试者的中文语音信号,语音信号的设计包括可能表现腺样体和扁桃体肥大患者声学异常的语音范式,具体包括5个中文元音(a,e,i,u,ü)和2个中文鼻音(mi,ni),每个元音和鼻音都包含4种声调(阴平,阳平,上声,去声)的发音(如中文元音a的四种音调分别为:ā,á,ǎ,à),共28个中文语音信号,整个录音过程都是由汉语专业人员陪同指导下进行;
5、所述信号预处理模块,用于对语音信号采集模块所采集到的语音信号进行前置处理,包括对原始语音信号进行静音消除、预加重、分帧、加窗等处理;从而得到更加平稳的信号;
6、所述特征提取、特征拼接和特征选择模块,用于对信号预处理模块所处理的语音信号进行相关声学参数特征提取,再对各个语音提取的特征进行拼接,最后对拼接后的特征采用单变量选择法进行特征选择以获得最优特征;
7、所述数据均衡模块,采用数据均衡算法对特征提取、特征拼接和特征选择模块所得到的样本进行数据生成,合成新样本;
8、所述深度学习网络模块,用于对数据均衡模块所得到的所有样本进行更深层次的特征挖掘,以得到更精准的结果;
9、所述二分类模块,用于对深度学习网络模块的输出进行腺样体和扁桃体肥大的二分类;
10、所述四分类模块,用于对深度学习网络模块的输出进行腺样体和扁桃体肥大的四分类。
11、本发明中,所述语音信号采集模块中,包括avid mbox外接声卡和“斐风”计算机辅助语言调查分析软件,用于采集5个中文元音信号和2个中文鼻音信号。
12、本发明中,所述特征提取、特征拼接和特征选择模块中,提取的特征包括6个时域特征(如短时能量、均方根能量、短时过零率等),28个频域特征(如频谱质心、频谱通量、各阶梅尔倒谱系数差分均值、各阶梅尔倒谱系数标准差等),12个韵律特征(如基频、基频的均值、第一共振峰、第二共振峰、第三共振峰的最小值、标准差等),即对每个语音信号共提取46个特征;在提取特征之后,对所有元音和鼻音信号的特征进行拼接,使其成为一个包含1288个特征的一维向量,然后再利用单变量特征选择法从这1288个特征中选取对腺样体和扁桃体肥大程度贡献值最高、能表证绝大多数信息的前200个特征,使其成为一个包括200个最优特征的一维向量。
13、本发明中,所述数据均衡模块中,采用adasyn算法[6],该算法能自适应地评估数据集中的不平衡程度,通过在现有少数类样本之间进行插值生成合成样本,从而缓解数据分布不平衡的问题。
14、本发明中,所述深度学习网络模块中,包括3层全连接层,5层卷积层,5层非线性激活层,5层池化层。
15、本发明中,所述二分类模块中,包括1层全连接层和1层softmax层,softmax层输出的是腺样体和扁桃体是否肥大的概率,分类的等级包括:腺样体和扁桃体正常(a/n≤0.60),腺样体和扁桃体肥大(a/n>0.60),该模块实现了对受试者是否患有腺样体和扁桃体肥大的识别。
16、本发明中,所述四分类模块中,包括1层全连接层和1层softmax层,softmax层输出的是腺样体和扁桃体肥大程度的概率,分类的等级包括:腺样体和扁桃体正常(a/n≤0.60),腺样体和扁桃体轻度肥大(0.60<a/n≤0.70),腺样体和扁桃体中度肥大(0.70<a/n≤0.80),腺样体和扁桃体重度肥大(a/n>0.8),该模块实现了对受试者患有腺样体和扁桃体肥大程度的识别。
17、本发明中,所述二分类模块和四分类模块中,都采用准确率、精确率、召回率及f1分数这四个指标来评估模型的性能。其中f1分数同时考虑了精确率和召回率,被认为是模型精确率和召回率的加权平均,它的最大值是1,最小值是0,值越大意味着模型的性能越好。
18、本发明针对腺样体和扁桃体肥大的高发病率低诊断率、疾病风险因素高,而诊断腺样体和扁桃体肥大的临床方法鼻咽侧位片和鼻内镜检查时间成本过高的缺陷,本发明通过对不同声调下的中文语音信号提取特征,并将所有声调下的特征进行拼接和选择,拼接和选择后的特征送至时下先进的深度学习网络进行进一步的特征提取和训练,实现了一种精确的、可靠的、无创的全自动腺样体和扁桃体肥大识别系统,该系统可以实现对患者的腺样体和扁桃体肥大程度的诊断,并且基于诊断结果评估患者就诊需求的优先级,从而加快重症病例的诊断和治疗。
19、和现有技术相比,本发明的有益效果在于:
20、(1)本发明使用了更加丰富、更加多元的语音信号,包括5个中文元音信号和2个鼻音信号,且每个语音信号都包含4声中文声调;
21、(2)本发明针对每个语音信号,提取了丰富的特征:提取了时域特征(如短时能量、均方根能量、短时过零率等)、频域特征(如频谱质心、频谱通量、各阶梅尔倒谱系数差分均值等)、韵律特征(如基频、基频的均值、中位数、基频的最值、基频扰动均值、第一共振峰、第二共振峰、第三共振峰的最小值、标准差等);
22、(3)本发明采用特征选择算法对所提特征进行最优特征筛选,特征筛选的结果可以用来评判哪种中文发音更有利于腺样体和扁桃体肥大的诊断,采用数据均衡算法使得样本种类达到均衡,采用深度学习网络挖掘更深层次的特征和得到更加精确的结果;
23、(4)本发明基于语音信号的腺样体和扁桃体肥大识别无需在医院进行,只需采集相关语音信号便可独立完成,可用于个人健康检测。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24260.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表