用于罕见词语音辨识的大规模语言模型数据选择的制作方法
- 国知局
- 2024-06-21 11:53:09
本公开涉及用于罕见词语音辨识的大规模语言模型数据选择。
背景技术:
1、自动语音辨识(asr)系统已经从每个模型具有专用目的的多个模型演化到使用单个神经网络将音频波形(即,输入序列)直接映射到输出句子(即,输出序列)的集成模型。这种集成已经产生了序列到序列的方式,当给定音频特征序列时,该方式生成词(或字素)序列。通过集成结构,模型的所有组件可以作为单个端到端(e2e)神经网络被联合训练。这里,端到端模型是指其架构完全由神经网络构建的模型。完全神经网络无需外部和/或手动设计的组件(例如,有限状态传感器、词典或文本规范化模块)即可运行。另外,在训练e2e模型时,这些模型通常不需要从决策树引导或从单独的系统进行时间对齐。这些端到端自动语音辨识(asr)系统取得了巨大进步,在包括单词错误率(wer)在内的几个常见基准测试上超越了传统asr系统。e2e asr模型的架构很大程度上是应用相关的。例如,许多涉及用户交互的应用(诸如语音搜索或设备上听写)要求模型以流式传输方式执行辨识。其他应用(如离线视频字幕)不需要模型进行流式传输,并且能够利用未来的上下文来提高性能。附加地,现有的e2e模型在辨识训练期间未见过的罕见词方面经历很高失败率。通过在大规模训练数据集上训练外部语言模型来改进罕见词辨识。
技术实现思路
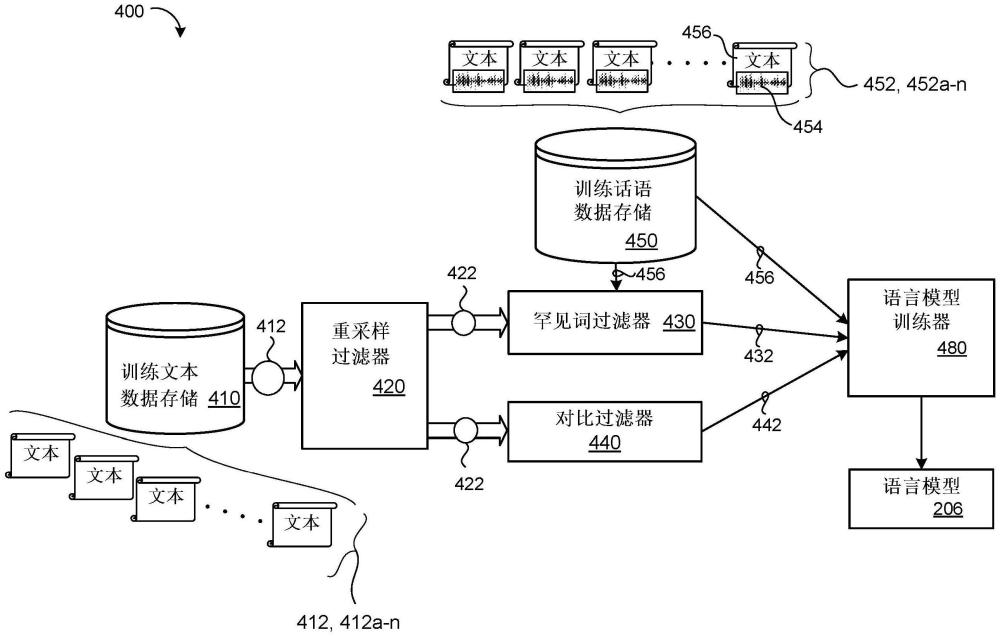
1、本公开的一个方面提供了一种训练用于罕见词语音辨识的语言模型的计算机实现的方法。当在数据处理硬件上执行时,该计算机实现的方法使得数据处理硬件执行操作,该操作包括:获得训练文本样本的集合;以及,获得用于训练自动语音辨识(asr)模型的训练话语的集合。多个训练话语中的每个训练话语包括对应于话语的音频数据和该话语的对应转录。这些操作还包括:对训练文本样本的集合应用罕见词过滤,以识别罕见词训练文本样本的子集,该子集包括未出现在来自训练话语的集合的转录中或者出现在来自训练话语的集合的转录中少于阈值次数的词。该操作还包括在来自训练话语的集合的转录和所识别的罕见词训练文本样本的子集上训练外部语言模型。
2、本公开的实施方式可以包括以下可选特征中的一个或多个。在一些实施方式中,获得训练文本样本的集合包括:接收训练文本样本语料库;对训练文本样本语料库执行重采样函数以识别训练文本样本语料库中出现的高频文本样本;以及,通过从训练文本样本语料库中去除所识别的高频文本样本来获得训练文本样本的集合。在一些示例中,重采样函数包括简单功率重采样函数、强制功率重采样函数或软对数重采样函数之一。
3、在一些实施方式中,该操作还包括:对训练文本样本的集合应用对比过滤以识别与关联于训练话语的集合的目标域匹配的目标域训练文本样本的子集。这里,在来自训练话语的集合的转录和所识别的罕见词训练文本样本的子集上训练外部语言模型还包括在与所述目标域匹配的所识别的目标域训练文本样本的子集上训练外部语言模型。在一些示例中,外部语言模型包括外部神经语言模型。在这些示例中,外部神经语言模型可以包括conformer层或transformer层的堆叠。
4、在一些实施方式中,该操作还包括将所训练的外部语言模型与asr模型集成。所训练的外部语言模型被配置为对由所训练的asr模型预测的可能语音辨识假设上的概率分布重新评分。在这些实施方式中,asr模型包括第一编码器、第二编码器和解码器。该第一编码器被配置为接收声学帧序列作为输入,并且在多个输出步中的每一个处生成声学帧序列中的对应声学帧的第一高阶特征表示。该第二编码器被配置为接收由第一编码器在多个输出步中的每一个处生成的第一高阶特征表示作为输入,并且在多个输出步中的每一个处生成对应的第一高阶特征帧的第二高阶特征表示。解码器被配置为接收由第二编码器在多个输出步中的每一个处生成的第二高阶特征表示作为输入,并且在多个时间步中的每个时间步处生成在可能语音辨识假设上的第一概率分布。
5、在这些实施方式中,解码器还可以被配置为接收由第一编码器在多个输出步中的每一个处生成的第一高阶特征表示作为输入,并且在多个时间步中的每个时间步处生成在可能语音辨识假设上的第二概率分布。附加地,解码器可以包括预测网络和联合网络。当asr模型以流式传输模式操作时,预测网络被配置为接收由预测网络在多个输出步中的每一个处生成的平均嵌入以及由第一编码器在多个输出步中的每个输出步处生成的第一高阶特征表示作为输入,以及在多个输出步中的每个输出步处生成在可能语音辨识假设上的第二概率分布。替代地,当asr模型以非流式传输模式操作时,预测网络被配置为接收由预测网络在多个输出步中的每一个处生成的平均嵌入以及由第二编码器在多个输出步中的每个输出步处生成的第二高阶特征表示作为输入,并且生成在可能语音辨识假设上的第一概率分布。
6、附加地或替代地,第一编码器可以包括因果编码器,该因果编码器包括conformer层的初始堆叠。这里,第二编码器可以包括非因果编码器,该非因果编码器包括覆盖在conformer层的初始堆叠上的conformer层的最终堆叠。可以使用混合自回归换能器分解来训练asr模型的第一编码器和第二编码器,以促进基于纯文本数据训练的外部语言模型的集成,纯文本数据包括来自训练话语的集合的转录和所识别的罕见词训练文本样本的子集。
7、本公开的另一方面提供了一种用于训练用于罕见词语音辨识的语言模型的系统。该系统包括数据处理硬件和与数据处理硬件通信的存储器硬件。存储器硬件存储指令,该指令当在数据处理硬件上执行时,使得数据处理硬件执行包括下述操作的操作:获得训练文本样本的集合;以及,获得用于训练自动语音辨识(asr)模型的训练话语的集合。多个训练话语中的每个训练话语包括对应于话语的音频数据以及话语的对应转录。该操作还包括:对训练文本样本的集合应用罕见词过滤以识别罕见词训练文本样本的子集,该子集包括未出现在来自训练话语的集合的转录中或者出现在来自训练话语的集合的转录中少于阈值次数的词。这些操作还包括:在来自训练话语的集合的转录和所识别的罕见词训练文本样本子集上训练外部语言模型。
8、这一方面可以包括以下可选特征中的一个或多个。在一些实施方式中,获取训练文本样本的集合包括:接收训练文本样本语料库;对训练文本样本语料库执行重采样函数以识别训练文本样本语料库中出现的高频文本样本;以及,通过从训练文本样本语料库中去除所识别的高频文本样本来获取训练文本样本的集合。在一些示例中,重采样函数包括简单功率重采样函数、强制功率重采样函数或软对数重采样函数之一。
9、在一些实施方式中,该操作还包括:对训练文本样本的集合应用对比过滤以识别与关联于训练话语的集合的目标域匹配的目标域训练文本样本的子集。这里,在来自训练话语的集合的转录和所识别的罕见词训练文本样本的子集上训练外部语言模型还包括在与目标域匹配的所识别的目标域训练文本样本的子集上训练外部语言模型。在一些示例中,外部语言模型包括外部神经语言模型。在这些示例中,外部神经语言模型可以包括conformer层或transformer层的堆叠。
10、在一些实施方式中,该操作还包括所训练的外部语言模型与asr模型集成。所训练的外部语言模型被配置为对由所训练的asr模型预测的可能语音辨识假设上的概率分布重新评分。在这些实施方式中,asr模型包括第一编码器、第二编码器和解码器。第一编码器被配置为接收声学帧序列作为输入,并且在多个输出步中的每一个处生成声学帧序列中的对应声学帧的第一高阶特征表示。第二编码器被配置为接收由第一编码器在多个输出步中的每一个处生成的第一高阶特征表示作为输入,并且在多个输出步中的每一个处生成对应的第一高阶特征帧的第二高阶特征表示。解码器被配置为接收由第二编码器在多个输出步中的每一个处生成的第二高阶特征表示作为输入,并且在多个时间步中的每个时间步处生成在可能语音辨识假设上的第一概率分布。
11、在这些实施方式中,解码器还可以被配置为接收由第一编码器在多个输出步中的每一个处生成的第一高阶特征表示作为输入,并且在多个时间步中的每个时间步处生成在可能语音辨识假设上的第二概率分布。附加地,解码器可以包括预测网络和联合网络。当asr模型以流式传输模式操作时,预测网络被配置为接收由预测网络在多个输出步中的每一个处生成的平均嵌入以及由第一编码器在多个输出步中的每个输出步处生成的第一高阶特征表示作为输入,以及在多个输出步中的每个输出步处生成在可能语音辨识假设上的第二概率分布。替代地,当asr模型以非流式传输模式下操作时,预测网络被配置为接收由预测网络在多个输出步中的每一个处生成的平均嵌入以及由第二编码器在多个输出步中的每个输出步处生成的第二高阶特征表示作为输入,并且生成在可能语音辨识假设上的第一概率分布。
12、附加地或替代地,第一编码器可以包括因果编码器,该因果编码器包括conformer层的初始堆叠。这里,第二编码器可以包括非因果编码器,该非因果编码器包括覆盖在conformer层的初始堆叠上的conformer层的最终堆叠。可以使用混合自回归换能器分解来训练asr模型的第一编码器和第二编码器,以促进在纯文本数据上训练的外部语言模型的集成,该纯文本数据包括来自训练话语的集合的转录和所识别的罕见词训练文本样本的子集。
13、本公开的一个或多个实施方式的细节在附图和下面的描述中阐述。其他方面、特征和优点将从描述和附图以及权利要求中变得显而易见。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24267.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表