一种自动化的音频处理及修复的数据预处理方法及系统与流程
- 国知局
- 2024-06-21 11:53:07
本发明涉及智能语音,特别涉及一种自动化的音频处理及修复的数据预处理方法。
背景技术:
1、在智能语音技术飞速发展的当下,关于语音技术的各种应用层出不穷,而相当多语音技术的效果都以高质量的音频为基础。例如,在虚拟数智人火爆的当下,针对声音复刻vrs(voice reproduce service)技术,虽然许多厂商都提出了只需要几十秒的数据采集,就能复刻用户的声音,但是对于要求较高的声音复刻,仍然是要求几十乃至几百句音频才能较好地还原用户的音色。能否如实地还原用户的声音,录音质量是最关键的因素。
2、由于用户不是专业的录音人员,在长时间录音过程中,疲惫、懈怠等原因都可能导致用户出现口误念错字词的情况。虽然部分用户会自主地重新开始整句录制,来保证音频的连贯性,但仍有用户会仅重新读口误的部分,然后继续录制下去,例如原句为“今天的天气很炎热”,被用户录制成:“今天的天气额天气很炎热”。
3、传统的处理方法是需要工作人员后续进行人工处理,将不当的部分裁剪掉,视情况重新录制对应的音频插入原来的被裁剪的位置,并通过专业软件修复音频至听起来自然、连贯的状态。这种传统方法的缺点在于,专业人员人工核实、重新录制音频、处理音频耗时耗力,通过人工的方式去检查用户是否有口误的情况并进行音频处理及修复,难以满足现在日渐增长的各种语音技术的需求。
4、所以,亟需一种能够自动化根据音频及音频转写出的文本信息来联合判断口误部分,并且进行音频处理、通过深度学习模型修复处理后的音频的方法,实现输入用户音频即可得到高质量的修复后的音频,使得音频无需再进行人工核实、录音人员重新录制音频、人工处理和修复,极大减少应用智能语音技术前数据预处理部分的成本。
技术实现思路
1、针对现有技术存在的不足,本发明提供一种自动化的音频处理及修复的数据预处理方法及系统,可以实现自动化的对每个待处理音频使用最佳处理方式进行处理、拼接、修复,得到修复后的音频。
2、第一方面,本发明提供一种自动化的音频处理及修复的数据预处理方法,包括以下步骤:
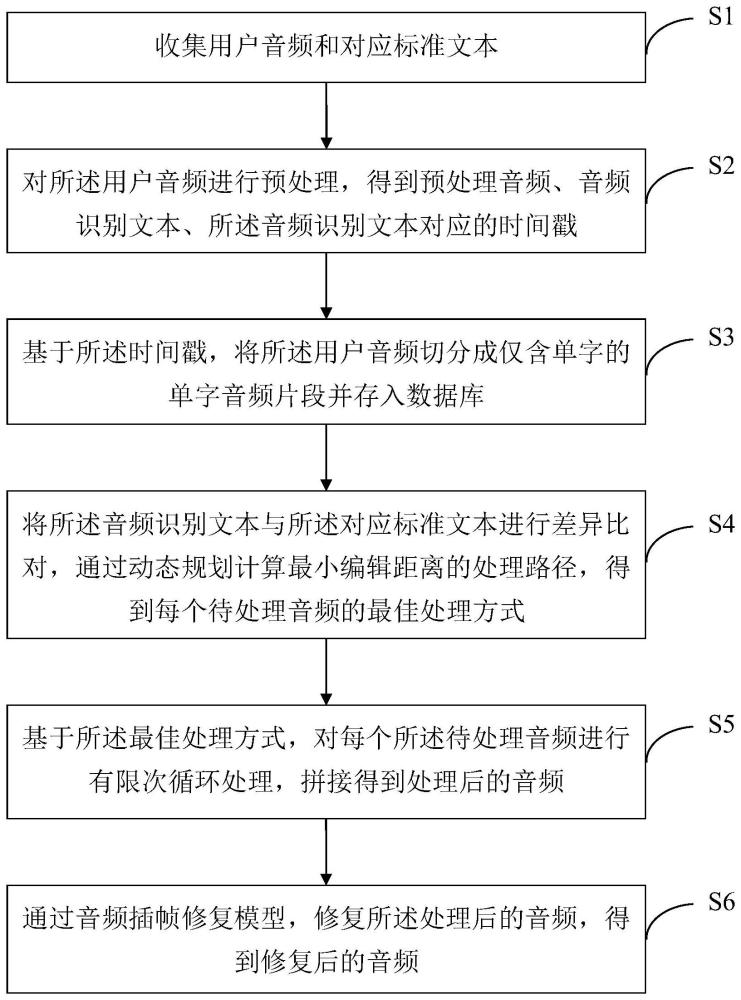
3、收集用户音频和对应标准文本;
4、对所述用户音频进行预处理,得到预处理音频、音频识别文本、所述音频识别文本对应的时间戳;
5、基于所述时间戳,将所述用户音频切分成仅含单字的单字音频片段并存入数据库;
6、将所述音频识别文本与所述对应标准文本进行差异比对,通过动态规划计算最小编辑距离的处理路径,得到每个待处理音频的最佳处理方式;
7、基于所述最佳处理方式,对每个所述待处理音频进行有限次循环处理,拼接得到处理后的音频;
8、通过音频插帧修复模型,修复所述处理后的音频,得到修复后的音频。
9、作为本发明的进一步改进,所述预处理音频可以由降噪、音量归一化得到;
10、所述音频识别文本由所述预处理音频通过语音识别模型得到;
11、所述时间戳由所述预处理音频和所述音频识别文本通过语音文本对齐工具得到。
12、作为本发明的进一步改进,所述数据库以{单字音频,对应字,对应拼音}的数据格式对所述单字音频片段进行存储。
13、作为本发明的进一步改进,所述最小编辑距离的处理路径为将所述音频识别文本转换成所述对应标准文本的次数最少的插入、删除、替换操作序列;
14、所述待处理音频的最佳处理方式为基于所述最小编辑距离的处理路径,根据所述最小编辑距离的处理路径在所述时间戳中的对应时间段,对所述待处理音频进行所述对应时间段的插入、删除、替换操作。
15、作为本发明的进一步改进,基于所述最佳处理方式,对每个所述待处理音频进行有限次循环处理包括:
16、在所述待处理音频的处理方式为删除文字的情况下,根据所述时间戳删除对应时间段的所述单字音频片段。
17、作为本发明的进一步改进,基于所述最佳处理方式,对每个所述待处理音频进行有限次循环处理包括:
18、在所述待处理音频的处理方式为插入或替换文字的情况下,在所述数据库中检索和待插入或待替换文字相同的字或相同拼音的字,根据所述数据库检索情况对所述待处理音频进行处理。
19、作为本发明的进一步改进,根据所述数据库检索情况对所述待处理音频进行处理包括:
20、在所述数据库中有所述相同的字或所述相同拼音的字的情况下,将所述相同的字或所述相同拼音的字对应时间段的所述单字音频片段提取出来,根据所述时间戳插入或替换至所述待处理音频中。
21、作为本发明的进一步改进,根据所述数据库检索情况对所述待处理音频进行处理包括:
22、在所述数据库中没有所述相同的字或所述相同拼音的字的情况下,基于所述用户音频和对应的所述音频识别文本,训练用户音色的变声器vc;
23、根据用户性别选取同性别标准音声语音合成模型,生成对应字的音频;
24、将所述对应字的音频输入到所述变声器vc中,得到变声处理后的对应字的音频,根据所述时间戳插入或替换至所述待处理音频中。
25、作为本发明的进一步改进,修复所述处理后的音频的方法包括:
26、将所述处理后的音频输入预先训练的音频插帧修复模型中,对所述处理后的音频的被处理部分生成自然的衔接部分,形成修复后的音频。
27、第二方面,本发明提供一种自动化的音频处理及修复的数据预处理系统,包括:
28、数据收集模块,用于收集用户音频和对应标准文本;
29、数据预处理模块,用于对所述用户音频进行预处理,得到预处理音频、音频识别文本、所述音频识别文本对应的时间戳;
30、数据库构建模块,用于基于所述时间戳,将所述用户音频切分成仅含单字的单字音频片段并存入数据库;
31、最佳处理方式规划模块,用于将所述音频识别文本与所述对应标准文本进行差异比对,通过动态规划计算最小编辑距离的处理路径,得到每个待处理音频的最佳处理方式;
32、音频处理模块,用于基于所述最佳处理方式,对每个所述待处理音频进行有限次循环处理,拼接得到处理后的音频;
33、音频修复模块,用于通过音频插帧修复模型,修复所述处理后的音频,得到修复后的音频。
34、与现有技术相比,本发明的有益效果在于:
35、由于本发明使用的方法及模型均可自动化进行,实现输入用户音频即可得到高质量的修复后的音频,使得音频无需再进行人工核实、录音人员重新录制音频、人工处理和修复,极大减少应用智能语音技术前数据预处理部分的人力劳动成本与时间成本,具有重要的实用价值和广阔的应用前景。
技术特征:1.一种自动化的音频处理及修复的数据预处理方法,其特征在于,包括以下步骤:
2.如权利要求1所述的自动化的音频处理及修复的数据预处理方法,其特征在于,所述预处理音频可以由降噪、音量归一化得到;
3.如权利要求1所述的自动化的音频处理及修复的数据预处理方法,其特征在于,所述数据库以{单字音频,对应字,对应拼音}的数据格式对所述单字音频片段进行存储。
4.如权利要求1所述的自动化的音频处理及修复的数据预处理方法,其特征在于,所述最小编辑距离的处理路径为将所述音频识别文本转换成所述对应标准文本的次数最少的插入、删除、替换操作序列;
5.如权利要求1所述的自动化的音频处理及修复的数据预处理方法,其特征在于,基于所述最佳处理方式,对每个所述待处理音频进行有限次循环处理包括:
6.如权利要求5所述的自动化的音频处理及修复的数据预处理方法,其特征在于,基于所述最佳处理方式,对每个所述待处理音频进行有限次循环处理包括:
7.如权利要求6所述的自动化的音频处理及修复的数据预处理方法,其特征在于,根据所述数据库检索情况对所述待处理音频进行处理包括:
8.如权利要求7所述的自动化的音频处理及修复的数据预处理方法,其特征在于,根据所述数据库检索情况对所述待处理音频进行处理包括:
9.如权利要求1所述的自动化的音频处理及修复的数据预处理方法,其特征在于,修复所述处理后的音频的方法包括:
10.一种如权利要求1-9中的任一项所述的自动化的音频处理及修复的数据预处理系统,其特征在于,包括:
技术总结本发明提供一种自动化的音频处理及修复的数据预处理方法及系统,其中方法包括:收集用户音频和对应标准文本;对所述用户音频进行预处理,得到预处理音频、音频识别文本、所述音频识别文本对应的时间戳;将所述用户音频切分成仅含单字的单字音频片段并存入数据库;将所述音频识别文本与所述对应标准文本进行差异比对,通过动态规划计算最小编辑距离的处理路径,得到每个待处理音频的最佳处理方式;对每个所述待处理音频进行有限次循环处理,拼接得到处理后的音频;修复所述处理后的音频,得到修复后的音频。本发明能够极大地减少人力劳动成本与时间成本。技术研发人员:周邦健,沈伟林受保护的技术使用者:华院计算技术(上海)股份有限公司技术研发日:技术公布日:2024/5/27本文地址:https://www.jishuxx.com/zhuanli/20240618/24261.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。