使用一个或更多个神经网络从音频合成视频的制作方法
- 国知局
- 2024-06-21 11:53:28
至少一个实施例涉及用于执行和促进人工智能的处理资源。例如,至少一个实施例涉及用于根据本文描述的各种新颖技术来训练神经网络的处理器或计算系统。
背景技术:
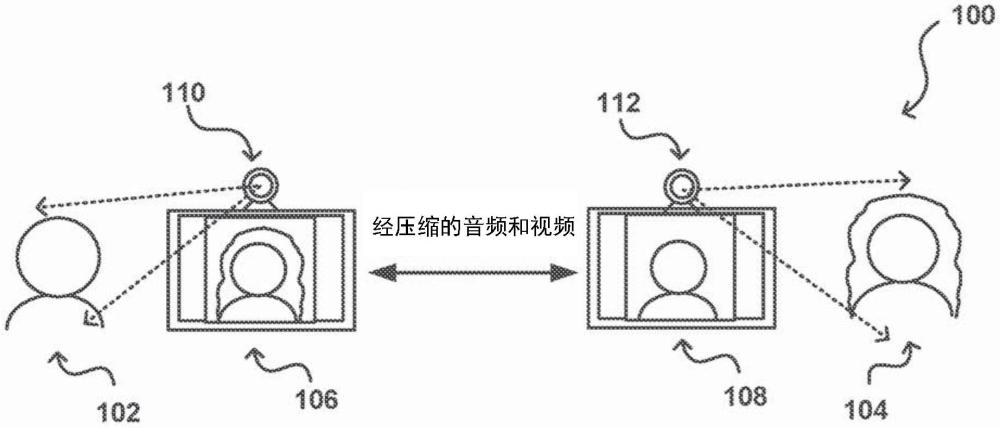
1、存在越来越多的需要传输大量数据的应用和服务。作为示例,诸如视频会议之类的应用要求在视频会议的参与者之间传输实况音频和视频数据。遗憾的是,诸如不良网络连接或低带宽之类的问题可能导致丢帧或者其他方式的不良视频质量。常规方法利用诸如h.264之类的视频压缩技术来减少需要传输的数据量,但此类方法具有各种限制且仍可能导致不良质量的视频呈现。
技术实现思路
技术特征:1.一种处理器,包括:
2.如权利要求1所述的处理器,其中所述第一视频信息包括一个或更多个三维角色模型说出所述语音信息的对应部分的表示。
3.如权利要求2所述的处理器,其中所述第二视频信息包括所述一个或更多个用户说出由所述第一视频信息中的所述一个或更多个三维角色模型表示的所述语音信息的所述对应部分的表示。
4.如权利要求2所述的处理器,其中所述第二神经网络被训练为将所述第一视频信息中表示的所述一个或更多个三维角色模型与所述一个或更多个图像中表示的所述一个或更多个用户之间的关键点进行关联。
5.如权利要求1所述的处理器,其中所述一个或更多个电路进一步用于使用第三神经网络以从文本合成所述语音信息。
6.如权利要求1所述的处理器,其中所述第二神经网络用于生成表示从所述语音信息确定的言语的情绪或模式的量的视频。
7.一种系统,包括:
8.如权利要求7所述的系统,其中所述第一视频信息包括一个或更多个三维角色模型说出所述语音信息的对应部分的表示。
9.如权利要求8所述的系统,其中所述第二视频信息包括所述一个或更多个用户说出由所述第一视频信息中的所述一个或更多个三维角色模型表示的所述语音信息的所述对应部分的表示。
10.如权利要求8所述的系统,其中所述第二神经网络被训练为将所述第一视频信息中表示的所述一个或更多个三维角色模型与所述一个或更多个图像中表示的所述一个或更多个用户之间的关键点进行关联。
11.如权利要求7所述的系统,其中所述一个或更多个处理器进一步用于使用第三神经网络以从文本合成所述语音信息。
12.如权利要求7所述的系统,其中所述第二神经网络用于生成表示从所述语音信息确定的言语的情绪或模式的量的视频。
13.一种方法,包括:
14.如权利要求13所述的方法,其中所述第一视频信息包括一个或更多个三维角色模型说出所述语音信息的对应部分的表示。
15.如权利要求14所述的方法,其中所述第二视频信息包括所述一个或更多个用户说出由所述第一视频信息中的所述一个或更多个三维角色模型表示的所述语音信息的所述对应部分的表示。
16.如权利要求14所述的方法,其中所述第二神经网络被训练为将所述第一视频信息中表示的所述一个或更多个三维角色模型与所述一个或更多个图像中表示的所述一个或更多个用户之间的关键点进行关联。
17.如权利要求13所述的方法,进一步包括:
18.如权利要求13所述的方法,其中所述第二神经网络用于生成表示从所述语音信息确定的言语的情绪或模式的量的视频。
19.一种机器可读介质,具有存储在其上的一组指令,所述一组指令在由一个或更多个处理器执行时,使所述一个或更多个处理器至少:
20.如权利要求19所述的机器可读介质,其中所述第一视频信息包括一个或更多个三维角色模型说出所述语音信息的对应部分的表示。
21.如权利要求20所述的机器可读介质,其中所述第二视频信息包括所述一个或更多个用户说出由所述第一视频信息中的所述一个或更多个三维角色模型表示的所述语音信息的所述对应部分的表示。
22.如权利要求20所述的机器可读介质,其中所述第二神经网络被训练为将所述第一视频信息中表示的所述一个或更多个三维角色模型与所述一个或更多个图像中表示的所述一个或更多个用户之间的关键点进行关联。
23.如权利要求19所述的机器可读介质,其中所述指令在被执行时,进一步使所述一个或更多个处理器使用第三神经网络以从文本合成所述语音信息。
24.如权利要求19所述的机器可读介质,其中所述第二神经网络用于生成表示从所述语音信息确定的言语的情绪或模式的量的视频。
25.一种视频生成系统,包括:
26.如权利要求25所述的视频生成系统,其中所述第一视频信息包括一个或更多个三维角色模型说出所述语音信息的对应部分的表示。
27.如权利要求26所述的视频生成系统,其中所述第二视频信息包括所述一个或更多个用户说出由所述第一视频信息中的所述一个或更多个三维角色模型表示的所述语音信息的所述对应部分的表示。
28.如权利要求26所述的视频生成系统,其中所述第二神经网络被训练为将所述第一视频信息中表示的所述一个或更多个三维角色模型与所述一个或更多个图像中表示的所述一个或更多个用户之间的关键点进行关联。
29.如权利要求25所述的视频生成系统,其中所述一个或更多个处理器进一步用于使用第三神经网络以从文本合成所述语音信息。
30.如权利要求25所述的视频生成系统,其中所述第二神经网络用于生成表示从所述语音信息确定的言语的情绪或模式的量的视频。
技术总结提出了用于生成媒体内容的装置、系统和技术。在至少一个实施例中,第一神经网络用于至少部分地基于与一个或更多个用户相对应的语音信息来生成第一视频信息,并且第二神经网络用于至少部分地基于第一视频信息以及与一个或更多个用户相对应的一个或更多个图像来生成与一个或更多个用户相对应的第二视频信息。技术研发人员:刘洺堉,长野光希,薛暎澔,J·R·巴列·戈梅斯·达科斯塔,J·徐,王鼎钧,A·马尔雅,S·哈米斯,平巍,R·巴德拉尼,K·J·施,B·卡坦扎罗,袁钰辉,J·考茨受保护的技术使用者:辉达公司技术研发日:技术公布日:2024/5/27本文地址:https://www.jishuxx.com/zhuanli/20240618/24300.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表