语音识别方法、装置、设备及存储介质与流程
- 国知局
- 2024-06-21 11:53:24
本申请涉及语音处理,更具体地说,涉及一种语音识别方法、装置、设备及存储介质。
背景技术:
1、自动语音识别(automatic speech recognition,asr)是一种将语音转换为文本的技术,在语音输入法、字幕生成、口语测评等场景中有广泛的应用。但目前的语音识别方法的抗噪能力差,仅在在安静环境中的识别率较高,在嘈杂环境中的识别率较低。因此,如何提高语音识别的抗噪能力成为亟待解决的技术问题。
技术实现思路
1、有鉴于此,本申请提供了一种语音识别方法、装置、设备及存储介质,以提高语音识别的抗噪能力。
2、为了实现上述目的,现提出的方案如下:
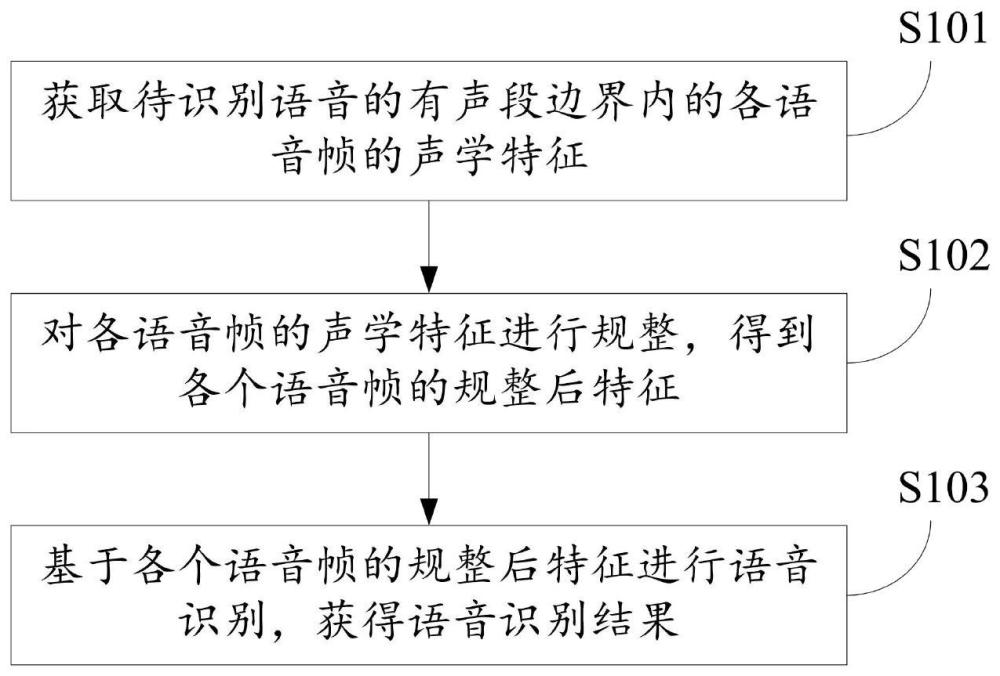
3、一种语音识别方法,包括:
4、获取待识别语音的有声段边界内的各语音帧的声学特征;
5、对所述各语音帧的声学特征进行规整,得到各个语音帧的规整后特征;其中,任一语音帧的规整后特征由所述任一语音帧的静态特征、所述任一语音帧的静态特征的一阶差分信息和二阶差分信息构成;
6、基于各个语音帧的规整后特征进行语音识别,获得语音识别结果。
7、上述方法,可选的,所述待识别语音的有声段边界通过如下方式确定:
8、对所述待识别语音进行第一次边界检测,得到初始有声段边界;
9、对所述待识别语音在所述初始有声段边界内的各个语音帧的声学特征进行规整,得到所述初始有声段边界内的各个语音帧的初次规整后特征;其中,任一初次规整后特征由所述任一初次规整后特征对应的语音帧的静态特征、所述任一初次规整后特征对应的语音帧的静态特征的一阶差分信息和二阶差分信息构成;
10、基于所述初始有声段边界内的各个语音帧的初次规整后特征对所述待识别语音进行第二次边界检测,得到所述待识别语音的有声段边界。
11、上述方法,可选的,所述第二次边界检测与所述第一次边界检测为不同类型的边界检测。
12、上述方法,可选的,所述对所述各语音帧的声学特征进行规整,得到各个语音帧的规整后特征,包括:
13、对所述各语音帧的静态特征进行倒谱均值规整,得到各语音帧的归一化静态特征;
14、对于每个语音帧,基于以该语音帧为中心的连续的多个语音帧的归一化静态特征,计算该语音帧的一阶差分信息和二阶差分信息;
15、将该语音帧的归一化静态特征、一阶差分信息和二阶差分信息拼接,得到该语音帧的规整后特征。
16、上述方法,可选的,所述基于各个语音帧的规整后特征进行语音识别,包括:
17、基于端到端语音识别模型对所述各个语音帧的规整后特征进行处理,得到所述待识别语音的多个可能的识别结果,以及各个可能的识别结果的置信度;
18、将置信度最高的可能的识别结果确定为语音识别结果。
19、上述方法,可选的,所述基于各个语音帧的规整后特征进行语音识别,包括:
20、基于端到端语音识别模型对所述各个语音帧的规整后特征进行处理,得到所述待识别语音的多个可能的识别结果;
21、利用语言模型计算各个可能的识别结果的评分;
22、将评分最高的可能的识别结果确定为置信度最高的识别结果。
23、上述方法,可选的,所述语言模型基于目标文本训练得到;所述待识别语音为朗读者朗读所述目标文本时的语音。
24、一种语音识别装置,包括:
25、获取模块,用于获取待识别语音的有声段边界内的各语音帧的声学特征;
26、规整模块,用于对所述各语音帧的声学特征进行规整,得到各个语音帧的规整后特征;其中,任一语音帧的规整后特征由所述任一语音帧的静态特征、所述任一语音帧的静态特征的一阶差分信息和二阶差分信息构成;
27、识别模块,用于基于各个语音帧的规整后特征进行语音识别,获得语音识别结果。
28、一种语音识别设备,包括存储器和处理器;
29、所述存储器,用于存储程序;
30、所述处理器,用于执行所述程序,实现如上任一项所述的语音识别方法的各个步骤。
31、一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现如上任一项所述的语音识别方法的各个步骤。
32、从上述的技术方案可以看出,本申请实施例提供的语音识别方法、装置、设备及存储介质,获取待识别语音的有声段边界内的各语音帧的声学特征后,对各语音帧的声学特征进行规整,得到各个语音帧的规整后特征;其中,任一语音帧的规整后特征由该任一语音帧的静态特征、该任一语音帧的静态特征的一阶差分信息和二阶差分信息构成;基于各个语音帧的规整后特征进行语音识别,获得语音识别结果。本申请通过有声段边界内的各语音帧的声学特征中的静态特征部分对有声段边界内的各语音帧的声学特征进行规整,进而利用有声段边界内各语音帧的规整后的声学特征进行语音识别,提高了语音识别的抗噪能力。
技术特征:1.一种语音识别方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述待识别语音的有声段边界通过如下方式确定:
3.根据权利要求2所述的方法,其特征在于,所述第二次边界检测与所述第一次边界检测为不同类型的边界检测。
4.根据权利要求1所述的方法,其特征在于,所述对所述各语音帧的声学特征进行规整,得到各个语音帧的规整后特征,包括:
5.根据权利要求1所述的方法,其特征在于,所述基于各个语音帧的规整后特征进行语音识别,包括:
6.根据权利要求1所述的方法,其特征在于,所述基于各个语音帧的规整后特征进行语音识别,包括:
7.根据权利要求6所述的方法,其特征在于,所述语言模型基于目标文本训练得到;所述待识别语音为朗读者朗读所述目标文本时的语音。
8.一种语音识别装置,其特征在于,包括:
9.一种语音识别设备,其特征在于,包括存储器和处理器;
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时,实现如权利要求1-7中任一项所述的语音识别方法的各个步骤。
技术总结本申请实施例公开了一种语音识别方法、装置、设备及存储介质,获取待识别语音的有声段边界内的各语音帧的声学特征后,对各语音帧的声学特征进行规整,得到各个语音帧的规整后特征;其中,任一语音帧的规整后特征由该任一语音帧的静态特征、该任一语音帧的静态特征的一阶差分信息和二阶差分信息构成;基于各个语音帧的规整后特征进行语音识别,获得语音识别结果。本申请通过有声段边界内的各语音帧的声学特征中的静态特征部分对有声段边界内的各语音帧的声学特征进行规整,进而利用有声段边界内各语音帧的规整后的声学特征进行语音识别,提高了语音识别的抗噪能力。技术研发人员:杨康,吴奎,张凯波,李宝善,盛志超,王士进,刘聪,胡国平受保护的技术使用者:科大讯飞股份有限公司技术研发日:技术公布日:2024/5/27本文地址:https://www.jishuxx.com/zhuanli/20240618/24295.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表