英语发音评估的方法、设备和计算机程序
- 国知局
- 2024-06-21 11:53:20
本发明涉及发音评估,具体为英语发音评估的方法、设备和计算机程序。
背景技术:
1、随着学习英语人数逐渐增加,英语培训机构与英语学习软件也越来越多。英语与汉语口语发音方法存在的相同点极少;教师更为重视学生写作、阅读理解、语法,轻视口语;学习者缺少练习英语口语的环境和时间。
2、针对传统英语口语发音评估的方法对学生发音错误不能及时校正、反馈的问题,设计一种英语发音评估的方法。
技术实现思路
1、本发明提供了英语发音评估的方法、设备和计算机程序,具备及时校正的优点,解决了上述背景技术所提出的问题。
2、本发明提供如下技术方案:英语发音评估的方法,包括以下步骤:
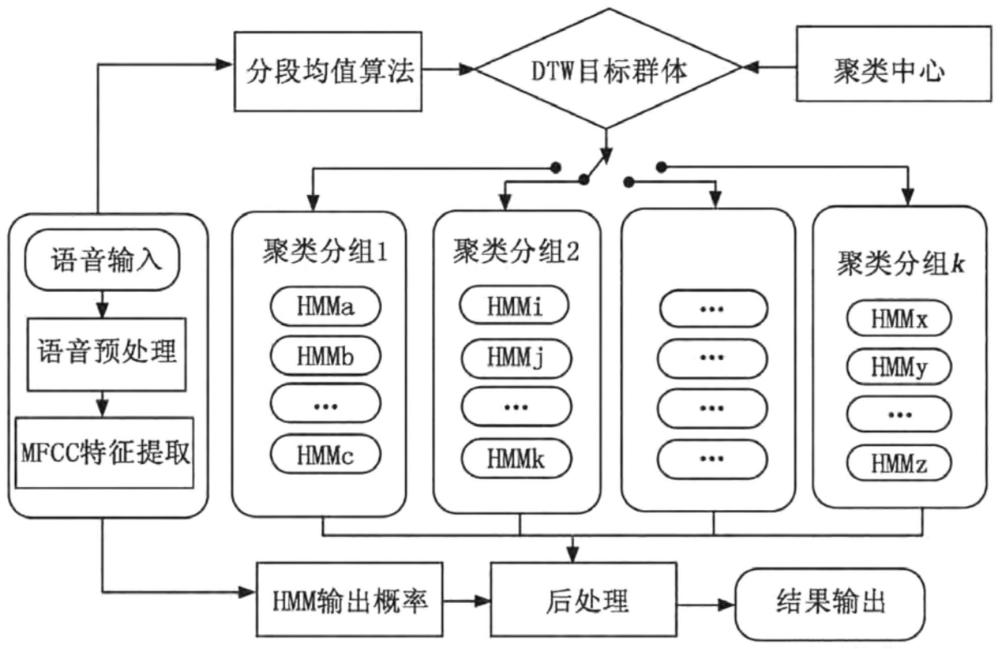
3、步骤s1:获取待评分的英语发音音频和发音视频;
4、步骤s2:将英语发音音频和发音视频传输至识别模型中,进行数据预处理和特征提取,得到英语发音音频特征和英语发音视频特征;
5、所述数据预处理包括,对采集的原始数据进行预处理,以删减干扰信息和噪音,提高语音信号特征提取精度,为特征提取和语音识别提供有效的数据;同时将单一英语词汇所对应的相应帧视频画面进行分组标记;
6、所述评分模型为实现输入语音的准确识别和分类,基于单一hmm识别系统,在其基础上加入聚类交叉分组算法,通过聚类交叉分组算法对每个输入语音进行概率计算,并在特征聚类组中对hmm参数进行语音映射,最终得到准确的语音识别结果;
7、步骤s3:将英语发音音频特征,输入到训练后的评分模型中,输出英语发音的评分结果;
8、所述评分模型包括口语发音训练模型,所述口语发音训练模型通过hmm模型与baum-welch方法进行训练;
9、过程如下:
10、起始模型λ=(a,b,π);通过监测训练o,得出新的参数,即x=(a,b,π);重复上一步,并优化模型参数,一直到p(o|λ)收敛为止;
11、优选的,a表示hmm中和时间无关情况下转移函数方程;b表示hmm中给定状态的监测数值情况;π表示hmm中起始状态空间数值;
12、所述hmm模型中样本数据选择采用matlabgui对英语词语进行语音视频采集,采样频率设置为8khz,选择某高校英语专业学生20人,给予每人100个单词进行语音输出,得到采集数据共2000个,该数据集中,主要包含语音和视频参数的采样频率、状态数目和语音字符序列;
13、步骤s4:所述评分模型包括错误发音识别和错误发音校正;
14、步骤s5:通过,错误发音识别模块得出的结果,实现英语发音音频中错误发音的提取,通过对英语发音音频中英语词汇进行分类,并计算错误发音词汇在该英语发音音频中总词汇的占比,得出该英语发音音频的评分;
15、步骤s6:同时通过错误发音识别模块得出的错误词汇结果,通过检索该错误词汇的帧数位置,得出与该错误词汇所对应的帧视频画面,通过显示器进行错误词汇的错误朗读画面和错误词汇的正确朗读画面,使人员实现自我对比,以实现自我调整学习;
16、步骤s7:通过错误发音校正,将该英语发音音频进行发音校正,并通过设备进行音频播放。
17、优选的,步骤s2具体包括,特征提取具体包括,完成数据预处理后,采用梅尔频率倒谱系数(mel-frequencycepstralcoefficients,mfcc)进行语音特征提取,mfcc特征提取流程如图2所示;
18、mfcc特征提取的具体流程可分为3个步骤,具体表现为:
19、(1)进行端点检测后,音频信号转换为数字信号,对每帧语音信号x(n)
20、进行n点fft变换,从而获得频谱信息x(k),其表达式为:
21、
22、(2)根据x(k)求出功率谱|x(k)|2,利用mel频率滤波器组hm(k)求出mel频谱后,从中取对数,获得对数能量谱信号s(m),
23、
24、其中,hm(k)表示滤波器组,m表示频率分组;
25、若滤波器组hm(k)的最高频率和最低频率分别为fh和fl,语音信号采样频率表示为fs,即可得到mel中心频率f(m)表达式为:
26、
27、其中,b(f)表示以赫兹为单位的线性频率f的转换函数,b-1(f)表示逆函数;
28、
29、(3)采用离散余弦变换方法(discretecosinetrans-form,dct)对能量谱信号s(m)进行倒谱处理,并求出i阶的mfcc倒谱系数c(i),i值大小通常为12~16范围内,c(i)表达式为:
30、
31、为更好地表述各帧信号间的关联性,基于倒谱系数c(i)计算出倒谱差分系数,计算式为:
32、
33、其中,k为差分参数,取值为2,利用上述公式(1)得到mfcc一阶差分系数,可用δmfcc进行表示,将δmfcc代入上述公式(1)中再次计算,得到二阶差分系数δ2mfcc,最后得到24维mfcc特征参数,从而完成特征提取。
34、优选的,步骤s3具体包括,所述评分模型包括错误发音识别,使用灭错方式将特征提取发音进行错误发音识别,设定n表示特征提取口语发音频率振动的波动极值;p表示频率振动的波谷的极值;d表示频率音频的正确周期;n表示介子传输频率的振幅;ah表示口语发音标准振幅;t表示频率参数,特征提取口语发音的振动音频e为:
35、
36、将得出音频做标准化与填充处理,即:
37、
38、优选的,ηe描述了音频填充中离散数值;n'描述了填充最大值与最小值的权重函数差;t描述了两个不同音频节点间跳数;dij描述了节点i与j间最近距离,填充处理后数据就能做属性规划,得出:
39、
40、优选的,ui表示音频指标;i表示正确音频特有周期参数,其属性已经被标签并做灭错识别运算,得出公式(5):
41、
42、优选的,at代表音频抖动性,是衡量音符的参数;s-1代表音频属性集合数值,是对音频进行灭错识别的参数;m表示相应音频匹配因子;r代表进阶音频所包含高程权重;vi代表音频进行灭错识别得出极限数值。
43、优选的,步骤s3具体包括,所述评分模型包括错误发音校正,将公式(5)得出结果输入系统反馈控制设备中进行校正,反馈控制设备需预先算出反馈途径,即:
44、
45、优选的,ωi表示反馈音频的衔接算子;ωj表示音阶通信数值参数;p表示音频种类参数编码,
46、经过公式(6)得出反馈途径与相关参数,若m表示发音的音频失效数值,采用序列方式将音频失效状态进行表述,该方法可以较好地对音频进行对照,得出公式(7):
47、m=(dt-p-1)mod180(7)
48、优选的,d代表对照音频路径的权重,利用排序方式将对照结果做数字化排列,有效提升校正的正确率,该过程对照公式为:
49、
50、优选的,mt表示音频衡量最佳参数;n表示特定范围内音频校正的正确率,若发音正确率为ci,现实发音为cq,获得函数关系为:
51、
52、优选的,t表示反馈因子,l表示极值频率,为了确保反馈流程中校正结果的精准性,将反馈流程做鲁化处理,得出:
53、
54、优选的,maxx4个数值分别表示反馈系统中鲁化上值、下值、载量、传输的极限数值;α代表发音音频的律动性能;r代表属性内置数值,使用鲁化算法能直接表现出系统使用状况,并对音频的上阶、下阶进行控制,使系统能够正常工作,该过程计算公式为:
55、ωij(k+1)=ωij(k)+η(dj-yj)yj(1-yj)·f(1-f(uij))xij (11)
56、优选的,η表示学习系数;k表示迭代次数;ωij表示音频收集权重;dj表示音频节点间距离;yj表示音频输出数值;uij表示音频收集速度;xij表示实测音频节点。
57、优选的,所述设备包括:
58、用于存储所述处理器可执行指令的存储器;
59、以及用于执行存储在所述存储器中的程序指令的处理器,以执行以下:
60、接收包括英语语音、视频和与所述英语语音对应的文本转录本的音频、视频文件;将所述音频、视频文件中包括的音频、视频信号输入到识别模型中,以获得所述英语语音的每个单词中的每个音素的语音信息。
61、优选的,所述计算机程序用于执行上述权利要求1-4中任一所述的英语发音评估的方法。
62、本发明具备以下有益效果:
63、1、该英语发音评估的方法、设备和计算机程序,通过采用梅尔频率倒谱系数将英语口语发音进行特征提取,并将得出结果进行标准化与填充处理,再根据属性规划做灭错识别计算,有效减少将发音错误当成正确发音的数量。
64、2、该英语发音评估的方法、设备和计算机程序,通过错误发音识别模块得出的错误词汇结果,通过检索该错误词汇的帧数位置,得出与该错误词汇所对应的帧视频画面,通过显示器进行错误词汇的错误朗读画面和错误词汇的正确朗读画面,使人员实现自我对比,以实现自我调整学习;
65、通过错误发音校正,将该英语发音音频进行发音校正,并通过设备进行音频播放;
66、解决传统英语口语发音评估的方法对学生发音错误不能及时校正、反馈问题。
67、3、该英语发音评估的方法、设备和计算机程序,hmm特征聚类分组算法能够提升英语机器人语音识别准确率,语音识别时间减少,识别效率进一步提高,仿真结果表明,本模型的平均识别率为99.65%,平均识别时间仅为1.1037s,比传统模型的识别准确率更佳,对比于深度学习中的ann模型识别率97.83%,本模型的识别率为99.65%,识别率高于ann模型,识别效果更好。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24288.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表