一种基于完全端到端的藏语拉萨话语音合成方法及系统
- 国知局
- 2024-06-21 11:53:16
本发明涉及人工智能,尤其涉及一种基于完全端到端的藏语拉萨话语音合成方法及系统。
背景技术:
1、语音合成(text-to-speech,tts)主要任务是将输入的文字序列转化为可听的语音信息,其应用从信息播报、汽车导航等拓展到智能语音对话、语音教学等各个领域,为人类社会带来经济效益,具有十分重要的理论意义和实践价值。随着时间的推移和科学技术的革新,语音合成技术的发展大致经历了机械式合成器、电子式合成器和基于计算机的语音合成三个阶段,语音合成发展史上具有实用性的tts系统应从基于计算机的波形拼接语音合成方法开始发展起来的,后来发展到基于统计参数的语音合成,再进一步发展到目前主流的深度学习语音合成方法。近年来,随着深度神经网络模型在各种序列生成任务上大放异彩,研究人员提出了基于端到端(end-to-end,e2e)的语音合成方法,极大地简化了传统语音合成方法的复杂流程,利用深层神经网络强大的非线性建模能力,有效提升建模精度,为语音合成的研究开辟了一条新的发展道路。
2、近年来,鉴于基于深度学习的端到端技术在很多语种的语音合成任务中得到成功应用,以及藏语各方言语音数据的规模逐日增长,相关研究人员提出了基于端到端的藏语语音合成方法,降低了对语言学知识的要求,从而减少前端文本分析模块对后端声学模型的负面影响,并合成语音的整体表现相比于传统方法获得了显著提升,实现了当前最好的藏语语音合成效果,表明了端到端技术已成为藏语语音合成的主流方法。然而,藏语由于复杂的发音特点且缺乏相关基础资源,以及研究力量薄弱等各种因素,导致藏语语音合成技术的整体研究进展缓慢,一直没有得到更大的突破,特别是针对藏语卫藏方言的语音合成研究甚少。近年来,尽管基于深度学习的声学建模技术在藏语语音合成中取得了重要进展,但是其合成语音的效果相比真实语音还有明显差距。此外,现有基于端到端的藏语声学建模通常采用“编码器-注意力-解码器”结构的自回归式生成模型,由于梅尔谱图的长序列和自回归性质,不仅推理速度慢,而且频繁出现漏词、跳词、重复吐词和错误发音等自回归模型中误差累积带来的鲁棒性问题,依然与人机交互的实际应用场景存在很大的距离。
3、近年来,为了更进一步简化训练过程和加快解码的推理速度,以及提高系统鲁棒性的同时,为了合成的语音具有更好的可控性和丰富的表现力,研究人员将凭借深度生成模型变分自编码器(variational auto-encoder,vae)、标准化流(normalizing flow)、生成式对抗网络(generative adversarial networks,gan)、降噪扩散概率模型(denoisingdiffusion probabilistic models,ddpm)等强大的建模能力,以及充分结合其各自的特性,将声学模型和声码器集成到一个模型,提出了完全端到端语音合成方法,从而打通了直接学习文本到波形采样点之间的映射关系。该方法不仅能够显著提升语音合成的速度,而且有效解决两阶段不匹配现象,成为当前在语音合成任务中主流的技术。受上述完全端到端语音合成方法在其他语种中得到成功应用的启发,本发明研究以音素作为建模单元的完全端到端藏语卫藏方言(拉萨话)语音合成方法,以解决现有藏语声学模型鲁棒性差、推理速度慢且音素覆盖率低等关键问题。
技术实现思路
1、本发明的目的是提出一种基于完全端到端的藏语拉萨话语音合成及系统。首先,通过自然语音采集、自动标注和声学分析等构建一个7000条中等规模的藏语卫藏方言语音数据库;其次,由于现有开源模型不能很好地表征藏文音节结构特征,且现有相关描述无法全面地刻画藏语语音结构,提出了现代藏文存在7种字形结构,并将其转写成对应的音素系列作为vits声学模型的建模单元;最后,经典的端到端开源模型vits应用在上述语音数据上进行了藏语语音合成试验,以实现具有高保真度和实时合成语音的藏语拉萨话语音合成系统;同时,为了提高合成系统的鲁棒性,在模型中引入预训练得到的音素强制对齐信息。
2、本发明的一个目的是提供一种基于完全端到端的藏语拉萨话语音合成方法,语音合成方法包括训练和合成两个阶段;
3、在训练阶段,包括以下步骤:
4、步骤1:在分析藏语卫藏方言基本语音结构的基础上,采用字音转换模型将待处理藏语文本转换为音素序列文本,记作音素序列ctext;
5、步骤2:通过mfa预训练模型将音素序列文本ctext与待处理藏语文本对应的音频进行音素强制对齐,得到以textgrid文件格式的音素对齐信息,记作音素对齐序列ctextgrid;
6、步骤3:基于声学模型的输入数据要求,对所述待处理藏语文本对应的音频数据进行预处理,得到与所述音频数据对应的线性谱图,记作高维语音x;
7、步骤4:将得到的音素对齐序列ctextgrid和高维语音x作为vits模型的输入,并通过vits的深层网络结构训练声学模型;
8、在合成阶段,包括以下步骤:
9、步骤5:将步骤1中的字音转换模型和步骤4训练好的vits模型部署到后台;
10、步骤6:基于步骤5部署到后台的字音转换模型,获得与输入文本对应的音素文本;
11、步骤7:将步骤6所得的音素文本输入到步骤5部署到后台的vits模型中,得到其对应的音频信号,并直接输出。
12、优选的,步骤1中,字音转换模型的建立过程如下:
13、(1)依据藏文传统文法对音节结构的描述,以及通过分析现代藏语文本的真实面貌,提出现代藏文共有7种字形结构;
14、(2)依据藏文音节结构与由声韵母音素构成基本语音单元的天然联系,即以音节的第一个元音为界限,此元音前面的所有组成构件反映藏语声母系统,而此元音及之后的所有组成构件结合反映藏语韵母系统,结合步骤(2)提出的7种藏文音节结构下,得到由231个声母和126个韵母组成的藏语声韵母体系;
15、(3)以所述藏语声韵母体系为基础,结合现代藏语书面语卫藏方言的声韵母发音特点,对藏语声韵母系统中相同发音动作的同音素进行合并处理,构建由52个声母音素和105个韵母音素组合的藏语卫藏方言音素系统,即其作为藏语卫藏方言的基本语音结构;
16、(4)最后,基于所述藏语卫藏方言的基本语音结构,采用排列组合的生成算法建立藏语文本转音素系列的字音转换模型。
17、优选的,7种字形结构具体构成为:
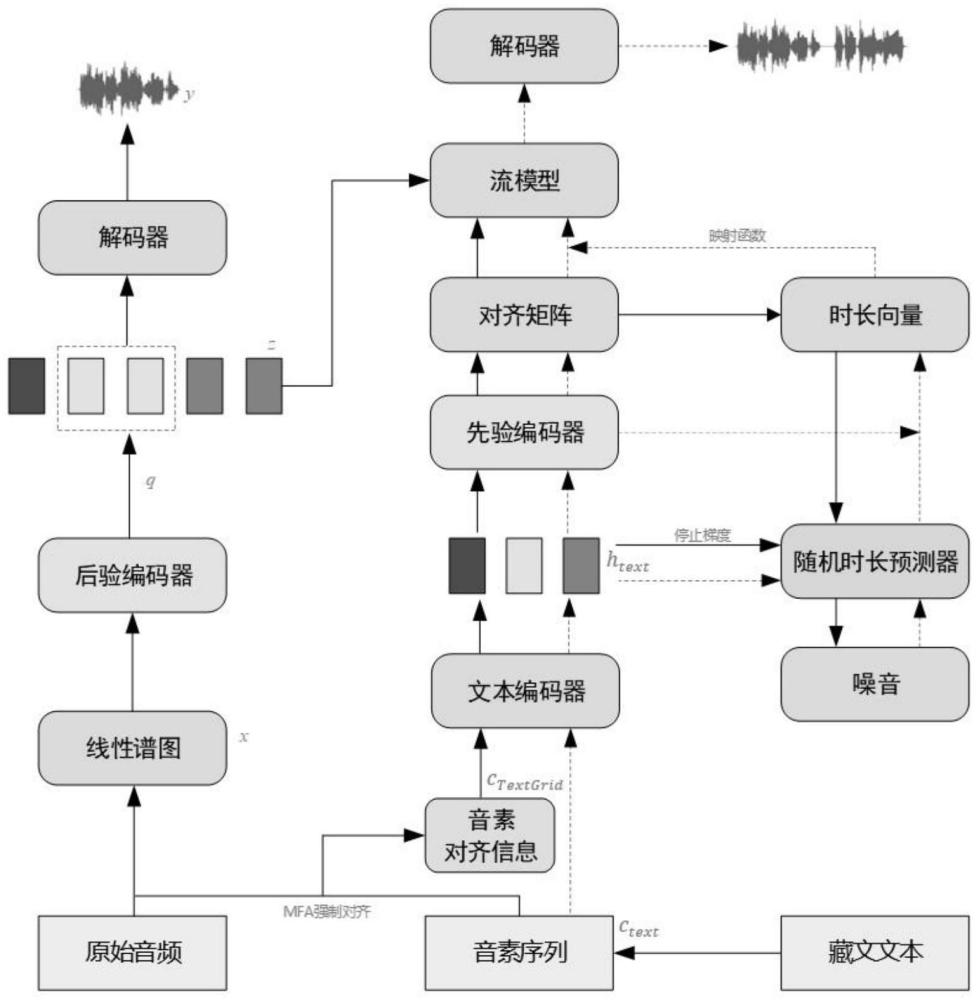
18、基字+下加字+再下加字+元音;
19、前加字+上加字+基字+下加字+再下加字+元音+后加字+再后加字;
20、前加字+上加字+基字+下加字+元音+辅音+二元音;
21、前加字+上加字+基字+下加字+元音+辅音+二元音+二辅音;
22、前加字+上加字+基字+下加字+再下加字+元音+辅音+二辅音;
23、前加字+上加字+基字+下加字+元音+辅音+二元音+二辅音+三辅音;
24、前加字+上加字+基字+下加字+元音+辅音+二元音+二辅音+三元音。
25、在上述7种字形结构中,除了“基字”和“元音”为组成藏文音节的首要成分外,其余成分的存在有无因字而异。
26、优选的,在所述步骤4的vits声学模型训练过程中,将输入的高维语音x通过后验编码器转换为后验分布q,再从后验分布q中采样得到与z对应的隐变量x;利用flow模型的可逆变换将得到的z转换为与先验分布p类似的pz;音素对齐序列ctextgrid则通过文本编码器得到文本的隐变量htext,并从中提取音素持续时间,再利用先验编码器将htext映射为先验分布p;最后,基于所述mfa强制对齐的音素对齐信息,搜索文本h与隐变量z之间的最优对齐信息a。
27、本发明的又一个目的是提供一种基于完全端到端的藏语拉萨话语音合成系统,该系统包括:
28、输入模块,用于获取用户输入的藏语文本信息;
29、转换模块,调用所述步骤5部署到后台的字音转换模型,获得与输入文本对应的音素文本;
30、输出模块,调用所述步骤5部署到后台的vits模型,将所述的音素文本转换成声学特征,并直接输出音频信号。
31、本发明的另一个目的是提供一种计算机设备,包括处理器和存储器,处理器与存储器相连,存储器用于存储计算机程序,处理器用于执行存储器中存储的计算机程序,以使得计算机设备执行上述所述的方法。
32、本发明的另一目的是提供一种计算机可读存储介质,计算机可读存储介质中存储有计算机程序,当计算机程序被运行时,实现如上述所述的方法。
33、与现有技术相比,本发明具有如下优点:
34、本发明通过分析大量的藏语文本,重新梳理分析了藏文音节结构的特殊性,并使用基于7种字形结构的藏语音素序列作为声学模型的建模单元,显著提升了藏语音段特征的覆盖率,从而缓解低资源且黏着语常见的数据稀疏导致模型训练困难、发音错误率高等问题。
35、本发明基于7种字形结构的音素文本作为建模单元且声学建模中引入基于mfa预训练模型的音素强制对齐信息,进一步提高了合成系统的鲁棒性;采用非自回归的端到端声学建模有效减少了模型的推理时间及进一步提高了合成语音的质量,相比“两段式模型”和直接使用拉丁文本作为模型的输入,mos值别分提高0.4和0.2左右。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24282.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表