训练和/或使用编码器模型确定自然语言输入的响应动作的制作方法
- 国知局
- 2024-06-21 11:45:06
本公开涉及训练和/或使用编码器模型确定自然语言输入的响应动作。
背景技术:
1、用户利用自由形式自然语言输入与各种应用程序对接。例如,用户可以使用此处称为“自动助理”(也称为“聊天机器人”,“交互式个人助理”,“智能个人助理”,“个人语音助理”,“会话代理”等)的交互式软件应用来参与人机对话。例如,人类(当他们与自动助理交互时可以称为“用户”)可以使用自由形式自然语言输入来提供命令、查询和/或请求(在本文中统称为“查询”),自由形式自然语言输入可以是被转换成文本然后进行处理的有声话语和/或通过键入的自由形式自然语言输入。
2、许多自动助理和其他应用被配置为响应于各种查询而执行一个或多个响应动作。例如,响应于自然语言查询“how are you(你好吗)”,自动助理可以配置为以图形和/或声音输出“great,thanks for asking(很好,谢谢询问)”来响应查询。作为另一个示例,响应于对“what’s the weather for tomorrow(明天天气如何)”的查询,可以将自动助理配置为(例如,通过api)与天气代理(例如,第三方代理)对接以确定“本地的”明天的天气预报,并且利用传达这样的天气预报的图形和/或声音输出来响应该查询。作为又一个示例,响应于对“play music videos on my tv(在我的电视上播放音乐视频)”的用户查询,可以将自动助理配置为使音乐视频在用户的网络电视上流传输。
3、然而,响应于寻求执行自动助理可执行的动作的各种查询,许多自动助理可能无法执行该动作。例如,自动助理可以被配置为响应于“play music videos on my tv”的查询而使音乐视频在用户的网络电视上流传输,但是可能无法响应于例如“make somevideos of the music variety appear on the tube(使音乐曲目的一些视频出现在管子上)”的各种其他查询而执行这种动作,尽管其他查询都寻求执行相同的动作。因此,自动助理将不会执行查询所期望的动作,而是可以提供一般误差响应(例如,“i don’t know howto do that(我不知道该怎么做”)或完全不响应。这可能导致用户不得不在另一个尝试中提供另一个查询,以使自动助理执行该动作。这浪费了各种资源,例如处理查询(例如,语音到文本处理)和/或传输查询(例如,当自动助理的组件位于远离提供查询的客户端的设备上时)所需的资源。
技术实现思路
1、本说明书的实现方式针对与以下有关的系统,方法和计算机可读介质:训练编码器模型,该编码器模型可用于(直接和/或间接)确定自然语言文本字符串与一个或多个附加自然语言文本字符串中的每一个的语义相似性;和/或使用经训练的编码器模型来确定要响应自然语言查询执行的一个或多个响应动作。编码器模型是机器学习模型,例如神经网络模型。
2、例如,一些实现方式使用经训练的编码器模型来处理针对自动助理的自由形式自然语言输入。使用经训练的编码器模型处理自由形式自然语言输入会生成自由形式自然语言输入的编码,例如是值的矢量的编码。然后将编码与均具有一个或多个映射到其上(直接和/或间接映射)的自动助理动作的预定编码进行比较。映射到预定编码的自动助理动作可以包括,例如,提供针对听觉和/或图形表示的特定响应,提供针对听觉和/或图形表示的响应的特定类型,与第三方代理对接,与物联网(iot)设备对接,确定一个或多个值(例如,“槽值(slot value)”),以包括在给代理和/或iot设备的命令中,等等。预定编码可以每个都是已分配给对应自动助理动作的对应文本段的编码。此外,可以使用经训练的编码器模型基于对对应文本段的处理来生成每个预定编码。此外,基于被分配给关于其生成预定编码的文本段的对应自动助理动作,预定编码被映射到对应自动助理动作。作为一个示例,可以使用经训练的编码器模型基于对“你好吗”的处理来生成预定编码,并且可以基于被分配给文本段“你好吗”(例如,以前由自动助理的程序员手动分配)的响应将预定编码映射到提供“很好,谢谢询问”的响应的自动助理动作。
3、比较(自由形式自然语言输入的编码与预定编码)可以被用来确定与该编码“最接近”的一个或多个预定编码。然后,可以由自动助理,可选地取决于“最接近”的预定编码“足够接近”(例如,满足距离阈值),执行映射到一个或多个“最接近”的预定编码的动作。作为一个示例,每种编码可以是值的矢量,并且两种编码的比较可以是矢量的点积,这导致指示两个矢量之间距离的标量值(例如,标量值可以是从0到1,其中标量值的大小指示距离),并且指示基于其生成编码的两个文本段的语义相似性。
4、作为一个特定示例,程序员可以将待分配的“使音乐视频在电视上流传输”的自动助理动作明确分配给文本段“在我的电视上播放音乐视频”,但是可以不明确分配该动作(或任何动作)到文本段“使音乐曲目的一些视频出现在管子上”。可以使用经训练的编码器模型来处理文本段“在我的电视上播放音乐视频”,以生成文本段的编码,并且可以利用“使音乐视频在电视上流传输”的自动助理动作的映射来存储该编码。此后,可以基于来自用户的用户界面输入,将自由形式自然语言输入“使音乐曲目的一些视频出现在管子上”引导至自动助理。可以使用经训练的编码器模型来处理输入“使音乐曲目的一些视频出现在管子上”以生成编码,并将该编码与预定编码(包括“在我的电视上播放音乐视频”的预定编码)进行比较。基于该比较,可以确定“在我的电视上播放音乐”的预定编码最接近“使音乐曲目的一些视频出现在管子上”的编码,并且满足接近度阈值。作为响应,自动助理可以执行映射到预定编码的动作。
5、以这些和其他方式,即使没有将自动助理动作明确地直接映射到自然语言输入,自动助理也通过执行适当的自动助理动作来鲁棒且准确地响应各种自然语言输入。这导致改进的自动助理。另外,从计算资源的角度来看,作为编码与预定编码的比较,生成“使音乐曲目的一些音乐视频出现在管子上”的编码是有效的(因为可以使用简单点积和/或其他比较)。此外,最大内部产品搜索和/或其他技术可以被用来进一步提高效率。这导致自动助理(相对于其他技术)更快地执行响应动作和/或确定响应动作以(相对于其他技术)使用较少的计算资源来执行。而且,存储编码到自动助理动作的映射比存储完整文本段到自动助理动作的映射可以更有效地利用存储空间。另外,由于单个预定编码可以在语义上(距离上)表示多个语义上相似的文本段,而无需将那些文本段中的每一个映射到自动助理动作,因此可以提供对自动助理动作的更少映射。此外,在自动助理接收查询作为语音输入的情况下,可以减少处理语音输入以确定查询(例如语音到文本处理)所需的资源,因为可以执行适当的自动助理动作,而没有要求用户在尝试获得所需结果时输入另一个查询的失败的查询响应。类似地,当查询是由远离自动助理的系统处理的(例如,当自动助理的组件位于远离提供查询的客户端设备的设备上时),发送查询并接收适当的响应所需的资源可以减少,因为可以执行适当的自动助理动作,而不必发送另一个查询来尝试获得相同的结果。这样,可以减少网络资源的使用。
6、另外和/或可替代地,本说明书的实现方式涉及用于训练编码器模型的各种技术。编码器模型是机器学习模型,例如神经网络模型。可以利用各种编码器模型架构,例如前馈神经网络模型、递归神经网络模型(即,包括一个或多个递归层,例如长短期存储器(lstm)层和/或门控递归单元(gru)层)、递归和卷积神经网络模型(即,包括一个或多个卷积层和一个或多个递归层)和/或转换器编码器。
7、在训练编码器模型的一些实现方式中,将编码器模型训练为基于与可以使用编码器模型的“语义文本相似性”任务(例如,上面相对于自动助理示例描述的语义相似性任务)不同的一个或多个任务而进行训练的较大的网络架构的一部分。在那些实现方式的一些中,编码器模型被训练为更大的网络架构的一部分,该更大的网络架构被训练为使得能够预测文本响应是否是对文本输入的真实响应。作为一个工作示例,可以利用训练实例,每个训练实例都包括训练实例输入,该训练实例输入包括:文本输入的输入特征以及文本响应的响应特征。训练实例各自进一步包括训练实例输出,该训练实例输出指示对应训练实例输入的文本响应是否是针对训练实例输入的文本输入的实际响应。对于正训练实例,基于被指示为实际上是对对话资源中文本输入的“响应”的文本响应,使用文本响应。例如,文本输入可以是第一用户的时间较早的电子邮件、文本消息、聊天消息、社交网络消息、互联网评论(例如,来自互联网讨论平台的评论)等,并且响应可以是附加用户的全部或部分响应电子邮件、文本消息、聊天消息、社交网络消息、互联网评论等。例如,文本输入可以是互联网讨论,响应可以是对互联网讨论的回复。
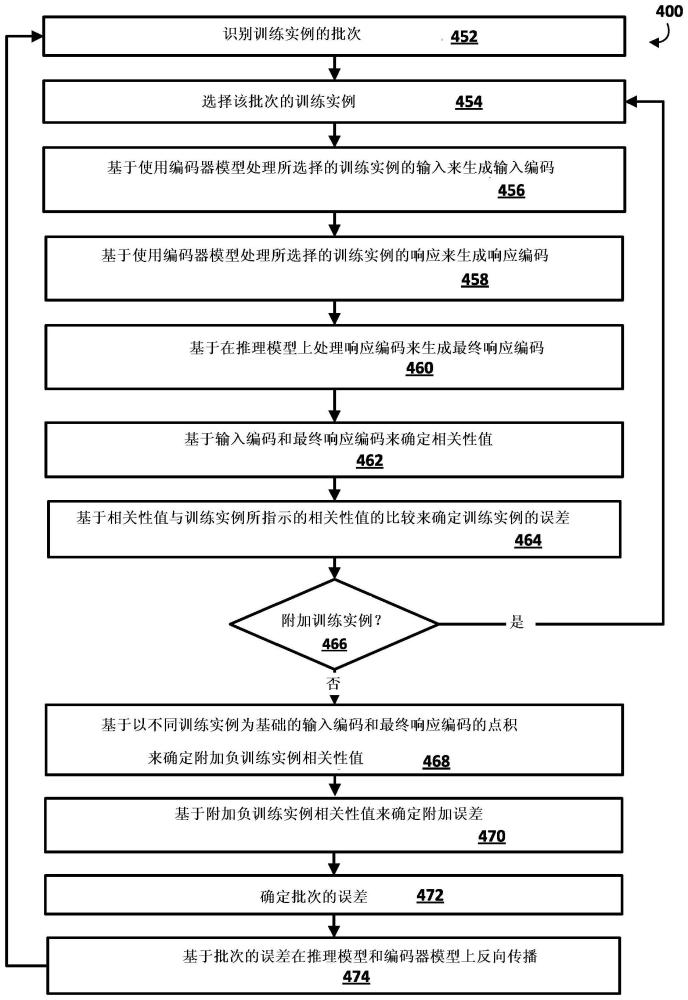
8、在训练期间,并继续工作示例,将训练实例的训练实例输入的输入特征应用为编码器模型的输入(而不应用训练实例输入的响应特征),并且输入编码基于使用编码器模型处理该输入生成。此外,将训练实例输入的响应特征应用为编码器模型的输入(而不应用训练实例输入的输入特征),并且响应编码基于使用编码器模型处理该输入来生成。使用推理模型进一步处理响应编码,以生成最终响应编码。推理模型可以是机器学习模型,例如前馈神经网络模型。然后基于输入编码和最终响应编码的比较来确定响应分值。例如,响应分值可以基于输入矢量和响应矢量的点积。例如,点积可以产生从0到1的值,其中“1”指示对应响应是对对应电子通信的适当响应的最高可能性,“0”指示最低可能性。然后,可以基于以下各项的比较来更新推理模型和编码器模型两者:响应分值(和可选的此处描述的批处理技术中的附加响应分值);以及由训练实例指示的响应分值(例如,对于正训练实例为“1”或其他“正(positive)”响应分值,对于负训练实例为“0”或其他“负(negative)”响应分值)。例如,可以基于响应分值与指示的响应分值之间的差来确定误差,并且在推理模型和编码器模型上反向传播误差。
9、通过这种训练,对编码器模型进行训练以使其独立地被使用(即,没有推理模型)以导出提供对对应输入的鲁棒且准确的语义表示的对应编码。同样,通过对每个都是基于文本输入和实际响应的正实例,和每个都是基于文本输入和非实际响应的文本响应的负实例进行训练,对应输入的语义表示至少部分基于文本输入与实际文本响应;以及文本输入与不是实际响应的文本响应之间的学习的差异。此外,可以如本文所述以无监督的方式有效地生成基于文本输入和文本响应的训练实例,并且可以从一个或多个语料库(例如如在这里所述的可公开获得的互联网评论)中生成大量多样的训练实例。如此大量的无监督和多样化的训练实例的使用可以产生强大的可以一般化到许多不同的文本段的编码器模型。
10、在训练之后,可以独立地使用编码器模型(即,没有推理模型)来确定两个文本字符串之间的语义相似性(语义文本相似性任务)。例如,可以基于使用经训练的编码器模型处理第一文本字符串来生成第一文本字符串的第一编码,并且可以基于使用经训练的编码器模型处理第二文本字符串来生成第二文本字符串的第二编码。此外,可以对两种编码进行比较以确定分值,该分值指示第一文本字符串和第二文本字符串之间的语义相似性的程度。例如,该分值可以基于第一编码和第二编码的点积。例如,点积可以产生从0到1的值,其中“1”指示最高相似度,“0”指示最低相似度(和最高不相似度)。
11、这样的分值可以用于各种目的。例如,这样的分值可以用于各种自动助理目的,例如上述那些目的。作为另一示例,搜索引擎可以使用这种分值来确定一个或多个在语义上类似于所接收的文本查询的文本查询。此外,由于指示两个文本段之间的相似性的分值基于两个文本段的对应编码的比较,因此经训练的编码器模型可以用于预先确定各种文本段的编码(例如,明确分配给对应响应动作(例如对应自动助理动作)的那些),以及存储的那些预定编码(例如,以及到它们对应响应动作的映射)。因此,可以通过使用经训练的编码器模型处理自然语言查询以生成编码,然后将所生成的编码与给定文本段的预存储编码进行比较,来确定输入自然语言查询与给定文本段的相似性。这消除了对运行时确定预存编码的需求,从而节省了运行时的各种计算资源和/或减少了运行时生成响应的延迟。此外,在运行时,基于使用经训练的编码器模型处理查询来确定自然语言输入查询输入矢量的编码,并且自然语言查询的相同编码可以与多个预定编码进行比较。这使得能够在运行时通过对编码器模型的单次调用来确定编码,并且与多个预定编码中的每一个相比,使用该编码。
12、在训练编码器模型的一些实现方式中,编码器模型被训练为基于与可以为其使用编码器模型的“语义文本相似性”任务不同的多个任务而进行训练的较大网络架构的一部分。在那些实现方式的一些中,基于预测文本响应是否是对文本输入的真实响应的任务来训练编码器模型(例如,如上所述),并且基于至少一个不同于语义文本相似性任务的附加任务来训练编码器模型。在那些实现方式中,在针对每个任务的训练中利用并更新了编码器模型,但是针对每个任务利用并更新了较大网络架构的不同附加组件。例如,上述推理模型可以用于预测文本响应是否为真实响应的任务,并且针对该任务的确定的误差用于在训练期间更新推理模型和编码器模型。而且,例如,对于附加任务,可以利用附加模型,并且针对该附加任务的确定的误差在训练期间被用于更新该附加模型和编码器模型。
13、在基于不同于“语义文本相似性”任务的多个任务训练编码器模型的各种实现方式中,同时对多个任务训练编码器模型。换句话说,编码器模型不是首先对第一任务被训练,然后在完成对第一任务的训练后再对第二任务被训练,等等。相反,编码器模型的权重的一个或多个更新(例如,通过误差的一个或多个反向传播)可以是基于第一任务的,然后,编码器模型的权重的一个或多个更新可以是基于第二任务的,然后,编码器模型的权重的一个或多个更新可以是基于第一任务的,然后,编码器模型的权重的一个或多个更新可以是基于第二任务的,等等。在这些各种实现方式中的一些中,可以在训练中利用独立的工作者(计算机工作),并且每个工作者使用针对对应任务的训练实例的批次只对对应任务进行训练。可以将不同数量的工作者投入到任务中,从而调整每个任务在训练编码器模型时的影响。作为一个示例,95%的工作者可以对预测文本响应是否是真正的响应任务进行训练,而5%的工作者可以对附加任务进行训练。
14、可以利用各种附加任务,并且可以利用除编码器模型之外的各种附加网络架构组件。附加任务的一个示例是自然语言推断任务,其可以使用监督训练实例(例如来自斯坦福自然语言推断(snli)数据集的监督训练实例)进行训练。这样的训练实例每个都包括一对文本段作为训练实例输入,以及训练实例输出,该训练实例输出是该对文本段的多个类别(例如,蕴涵,矛盾和中立的类别)中的一个类别的人工标签。可以用于自然语言推断任务的附件网络架构组件可以包括前馈神经网络模型,例如具有完全连接的层和softmax层的模型。
15、在针对自然语言推断任务的训练中,训练实例的训练实例输入的第一文本段被应用为编码器模型的输入(而不应用训练实例输入的第二文本段),并且第一编码基于使用编码器模型处理该输入而生成。此外,训练实例输入的第二文本段被应用为编码器模型的输入(而不应用训练实例输入的第一文本段),并且第二编码基于使用编码器模型处理该输入而生成。可以基于第一编码和第二编码生成特征矢量,例如(u1,u2,|u1-u2|,u1*u2)的特征矢量,其中u1代表第一编码,u2代表第二编码。可以使用针对自然语言推断任务的前馈神经网络模型来处理特征矢量,以针对多个类别(例如,蕴涵、矛盾和中立的类别)中的每个类别生成预测。可以比较该预测和训练实例的训练实例输出的标记类别,并基于比较(以及可选的此处描述的批处理技术自然语言推断任务的附加比较)更新自然语言推断任务的前馈神经网络模型。例如,可以基于比较确定误差,并在两个模型上反向传播。
16、本文公开的各种实现方式可以包括一个或多个非暂时性计算机可读存储介质,其存储可由处理器(例如,中央处理单元(cpu),图形处理单元(gpu)和/或张量处理单元(tpu))执行的指令,以执行方法,例如本文所述的一种或多种方法。其他各种实现方式可以包括一个或多个计算机的系统,该计算机包括一个或多个处理器,该一个或多个处理器可操作来执行存储的指令以执行诸如本文所述的一个或多个方法中的方法。
17、应当理解,本文中更详细描述的前述概念和附加概念的所有组合被认为是本文公开的主题的一部分。例如,出现在本公开的结尾处的要求保护的主题的所有组合被认为是本文公开的主题的一部分。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23360.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。