语音合成方法、装置、语音合成模型训练方法、装置与流程
- 国知局
- 2024-06-21 11:44:35
本技术涉及计算机,特别是涉及语音合成方法、装置、语音合成模型训练方法、装置、电子设备,以及计算机可读存储介质。
背景技术:
1、随着深度学习的发展,基于神经网络端到端的语音合成方法已经代替统计参数合成方法成为语音合成的基本方向。端到端语音合成方法可分为双阶段训练法和单阶段训练法。在单阶段的端到端语音合成中,整个合成系统在一个阶段进行训练,可以完全端到端的直接优化文本到音频的映射。单阶段语音合成方法根据不同的生成方法有vae(variational autoencoder)为框架的vits(variational inference with adversariallearning for end-to-end text-to-speech)模型,以normalizing flow为主的glow-tts模型,以及基于dpm(diffusion probabilistic model)的grad-tts模型。其中vits模型采用带有标准化流的变分推断和对抗训练过程,极大提高了生成的音频质量,同时引入基于标准化流的随机时长预测器实现了合成不同节奏的语音。但是实际使用中发现,采用vits模型进行语音合成时,仍然存在合成语音不够自然,缺少表现力,缺少情感色彩的缺陷。
2、可见,现有技术中的采用vits模型的语音合成方法还需要改进。
技术实现思路
1、本技术实施例提供一种语音合成方法、装置、语音合成模型训练方法、装置、电子设备及存储介质,可以提升语音合成在语音和情感方面的表现力,提升了合成语音的品质。
2、第一方面,本技术实施例提供了一种语音合成方法,应用于语音合成模型,所述方法包括:
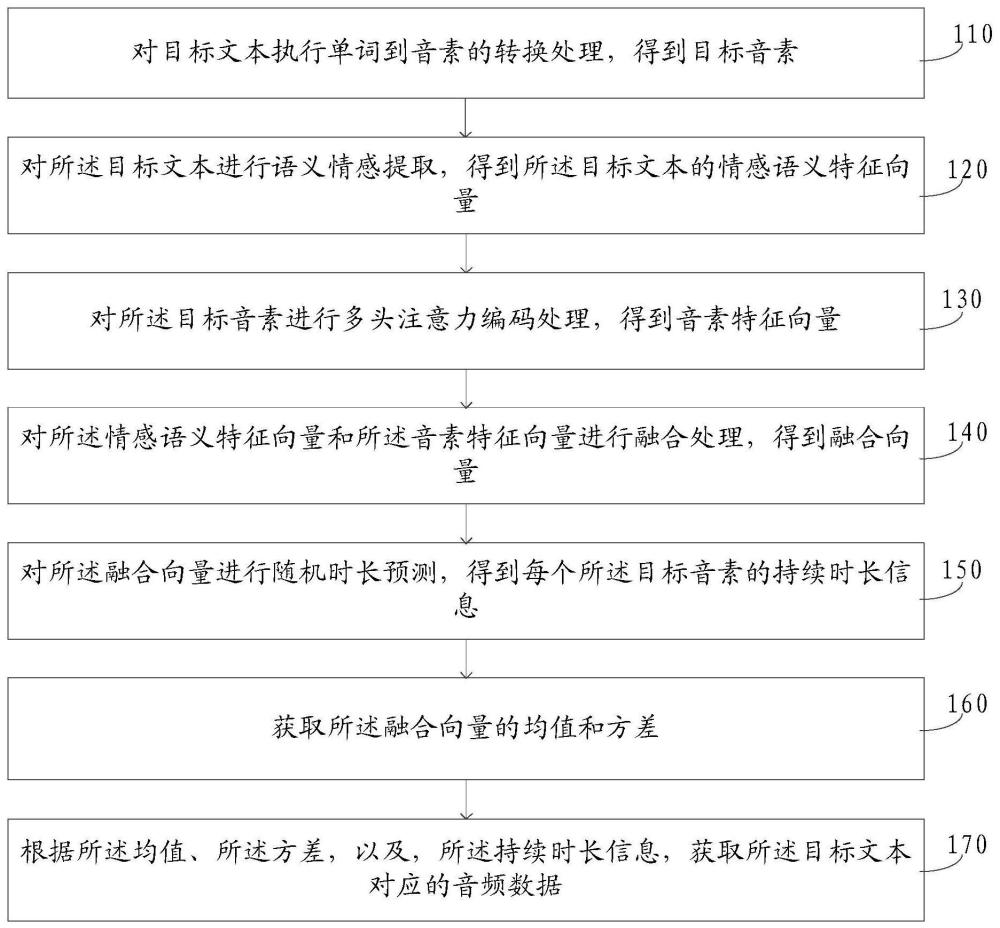
3、对目标文本执行单词到音素的转换处理,得到目标音素;
4、对所述目标文本进行语义情感提取,得到所述目标文本的情感语义特征向量;
5、对所述目标音素进行多头注意力编码处理,得到音素特征向量;
6、对所述情感语义特征向量和所述音素特征向量进行融合处理,得到融合向量;
7、对所述融合向量进行随机时长预测,得到每个所述目标音素的持续时长信息;
8、获取所述融合向量的均值和方差;
9、根据所述均值、所述方差,以及,所述持续时长信息,获取所述目标文本对应的音频数据。
10、第二方面,本技术实施例提供了一种语音合成装置,应用于语音合成模型,所述装置包括:
11、目标音素获取模块,用于对目标文本执行单词到音素的转换处理,得到目标音素;
12、情感语义特征向量获取模块,用于对所述目标文本进行语义情感提取,得到所述目标文本的情感语义特征向量;
13、音素特征向量获取模块,用于对所述目标音素进行多头注意力编码处理,得到音素特征向量;
14、融合向量获取模块,用于对所述情感语义特征向量和所述音素特征向量进行融合处理,得到融合向量;
15、持续时长信息获取模块,用于对所述融合向量进行随机时长预测,得到每个所述目标音素的持续时长信息;
16、均值和方差获取模块,用于获取所述融合向量的均值和方差;
17、音频数据获取模块,用于根据所述均值、所述方差,以及,所述持续时长信息,获取所述目标文本对应的音频数据。
18、第三方面,本技术实施例提供了一种语音合成模型训练方法,所述语音合成模型包括:后验编码器、解码器、单调对齐搜索模块、标准化流模型、随机时长预测器、局部注意力编码器、音素转换模块,以及,情感语义特征提取模块,所述方法包括:
19、针对每条训练样本,通过所述音素转换模块对所述训练样本中的样本文本执行单词到音素的转换处理,得到目标音素;
20、通过所述局部注意力编码器,对所述目标音素进行多头注意力编码处理,得到音素特征向量;
21、通过所述情感语义特征提取模块,对所述样本文本进行语义情感提取,得到所述样本文本的情感语义特征向量;
22、通过所述局部注意力编码器,对所述情感语义特征向量和所述音素特征向量进行融合处理,得到融合向量;
23、通过所述局部注意力编码器,获取所述融合向量的均值和方差;
24、通过后验编码器,获取根据所述样本文本对应的音频真实值进行后验编码处理得到的第一隐层向量;
25、通过所述标准化流模型,对所述第一隐层向量进行处理,得到第二隐层向量;
26、通过所述单调对齐搜索模块,根据所述均值、所述方差和所述第二隐层向量,搜索得到持续时长信息;
27、根据所述均值、所述方差,以及,所述持续时长信息,得到标准化流输入向量;
28、将所述标准化流输入向量作为所述标准化流模型的反向流输入,得到所述标准化流模型输出的第三隐层向量;
29、通过所述解码器,对所述第三隐层向量进行解码处理,得到音频合成值;
30、获取所述语音合成模型的模型损失,其中,所述模型损失至少包括:所述音频合成值和所述音频真实值的线性频谱的绝对值损失,以及,所述标准化流模型的反向流损失,所述反向流损失根据以下第一条件分布和第二条件分布的差值计算得到:给定文本的条件下,所述标准化流模型的反向流输出的第三隐层向量的第一条件分布、给定音频的条件下,所述后验编码器输出的第四隐层向量的第二条件分布;
31、以优化所述模型损失为目标,迭代训练所述语音合成模型。
32、第四方面,本技术实施例提供了一种语音合成模型训练装置,所述语音合成模型包括:后验编码器、解码器、单调对齐搜索模块、标准化流模型、随机时长预测器、局部注意力编码器、音素转换模块,以及,情感语义特征提取模块,所述装置包括:
33、目标音素获取模块,用于针对每条训练样本,通过所述音素转换模块对所述训练样本中的样本文本执行单词到音素的转换处理,得到目标音素;
34、音素特征向量获取模块,用于通过所述局部注意力编码器,对所述目标音素进行多头注意力编码处理,得到音素特征向量;
35、情感语义特征向量获取模块,用于通过所述情感语义特征提取模块,对所述样本文本进行语义情感提取,得到所述样本文本的情感语义特征向量;
36、融合向量获取模块,用于通过所述局部注意力编码器,对所述情感语义特征向量和所述音素特征向量进行融合处理,得到融合向量;
37、均值和方差获取模块,用于通过所述局部注意力编码器,获取所述融合向量的均值和方差;
38、第一隐层向量获取模块,用于通过后验编码器,获取根据所述样本文本对应的音频真实值进行后验编码处理得到的第一隐层向量;
39、第二隐层向量获取模块,用于通过所述标准化流模型,对所述第一隐层向量进行处理,得到第二隐层向量;
40、持续时长信息获取模块,用于通过所述单调对齐搜索模块,根据所述均值、所述方差和所述第二隐层向量,搜索得到持续时长信息;
41、标准化流输入向量获取模块,用于根据所述均值、所述方差,以及,所述持续时长信息,得到标准化流输入向量;
42、第三隐层向量获取模块,用于将所述标准化流输入向量作为所述标准化流模型的反向流输入,得到所述标准化流模型输出的第三隐层向量;
43、音频合成模块,用于通过所述解码器,对所述第三隐层向量进行解码处理,得到音频合成值;
44、损失计算模块,用于获取所述语音合成模型的模型损失,其中,所述模型损失至少包括:所述音频合成值和所述音频真实值的线性频谱的绝对值损失,以及,所述标准化流模型的反向流损失,所述反向流损失根据以下第一条件分布和第二条件分布的差值计算得到:给定文本的条件下,所述标准化流模型的反向流输出的第三隐层向量的第一条件分布、给定音频的条件下,所述后验编码器输出的第四隐层向量的第二条件分布;
45、迭代训练模块,用于以优化所述模型损失为目标,迭代训练所述语音合成模型。
46、第五方面,本技术实施例还公开了一种电子设备,包括存储器、处理器及存储在所述存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现本技术实施例所述的语音合成方法和/或语音合成模型训练方法。
47、第六方面,本技术实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时本技术实施例公开的语音合成方法和/或语音合成模型训练方法的步骤。
48、本技术实施例公开的语音合成方法,通过对目标文本执行单词到音素的转换处理,得到目标音素;对所述目标文本进行语义情感提取,得到所述目标文本的情感语义特征向量;对所述目标音素进行多头注意力编码处理,得到音素特征向量;对所述情感语义特征向量和所述音素特征向量进行融合处理,得到融合向量;对所述融合向量进行随机时长预测,得到每个所述目标音素的持续时长信息;获取所述融合向量的均值和方差;根据所述均值、所述方差,以及,所述持续时长信息,获取所述目标文本对应的音频数据,通过引入待合成文本的情感和语义信息,提高文本先验分布的复杂程度,拉近先验分布和后验分布距离,最终合成更富有表现力,富有情感的语音。
49、上述说明仅是本技术技术方案的概述,为了能够更清楚了解本技术的技术手段,而可依照说明书的内容予以实施,并且为了让本技术的上述和其它目的、特征和优点能够更明显易懂,以下特举本技术的具体实施方式。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23283.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。