基于IPSO-CHRFA模型的海洋哺乳动物叫声分类方法
- 国知局
- 2024-06-21 11:54:44
本发明涉及仿生隐蔽水声通信,具体为基于ipso-chrfa模型的海洋哺乳动物叫声分类方法。
背景技术:
1、海洋哺乳动物是海洋生态系统中的最为重要的旗舰物种和指示生物,具有不可替代的研究意义和保护价值。海洋哺乳动物依靠叫声来进行交流、捕食、定位和水下导航等活动,例如,抹香鲸通过发出四种不同的叫声来相互交流,虎鲸使用回声定位来定位并捕获难以捉摸的鲑鱼类猎物。
2、然而随着人类活动对海洋生态环境的不断影响,海洋中的人为噪声源,如:船舶交通、地震调查、海底钻探、军用声纳、遥测装置、海洋实验、水下爆炸等,会以不同的方式干扰海洋哺乳动物的生活。海洋哺乳动物叫声监测分类任务对于了解和分析其生活习性、种群状况和栖息地范围,进而科学地对它们实施保护措施具有重要的意义,科学有效的检测方法是支持这项任务的重要组成部分。由于海洋哺乳动物之间的交流方式复杂且难以探测,所以其发声行为一直未能得到全面而详细的解释。
3、目前,虽然已有一些分类方法被应用于海洋哺乳动物叫声的分析,但这些方法普遍存在着识别精度低、识别速率慢、识别类别少和鲁棒性差等问题。因此,开发一种更为科学、有效的海洋哺乳动物叫声多物种分类方法,成为了一项亟待解决的技术问题。
技术实现思路
1、本发明的目的在于提供一种基于ipso-chrfa模型的海洋哺乳动物叫声分类方法,能够准确捕捉并识别分类各种复杂的叫声以及噪音,降低训练时间,同时还具备高效、稳定的特点,以适应海洋环境的复杂性和多变性,实现了对海洋哺乳动物叫声的高效分类。
2、为实现上述目的,本发明提供如下技术方案:
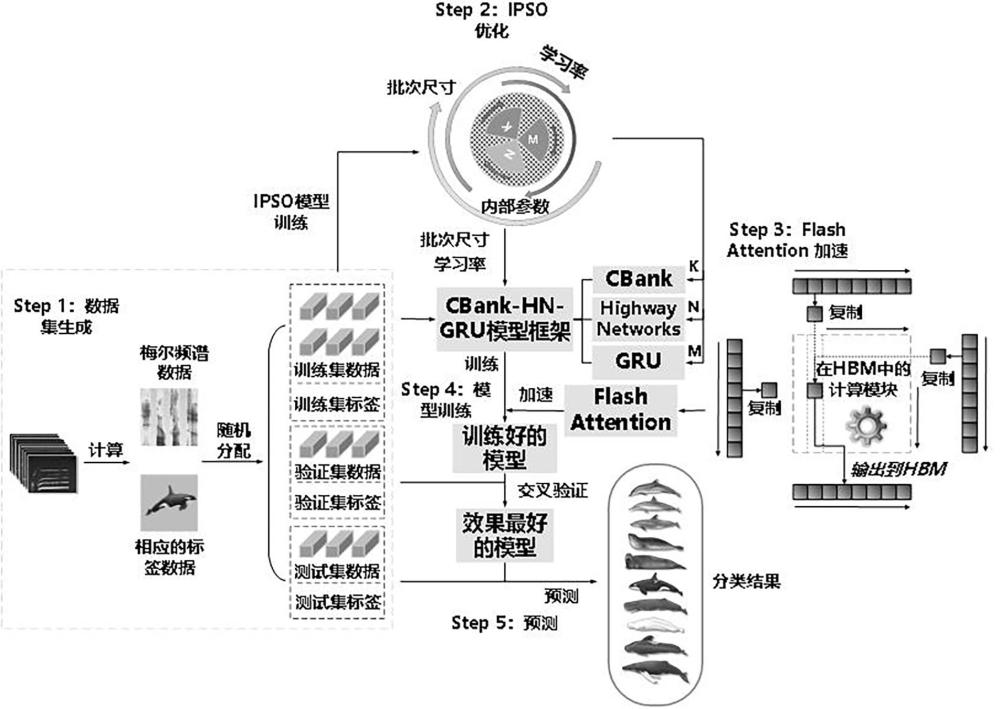
3、本发明的ipso-chrfa模型包括cbank-hn-gru分类模型、ipso改进的粒子群优化算法以及flash attention加速算法模块;其中,flash attention加速算法模块是一种重新排序注意力计算的算法,利用平铺、重计算经典技术来显著提升计算速度;并将序列长度中的内存实现从二次到线性减少,给模型的训练过程带来时钟时间加速;
4、cbank-hn-gru分类模型包括cbank(cnn-bank)卷积银行、hn(highway networks)高速网络以及gru(abidirectional gated recurrent unit)双向门控制单元网络。
5、优选的,具体步骤包括:
6、s1、生成海洋哺乳动物叫声音频数据集;
7、s2、构建cbank-hn-gru分类模型基础框架;
8、s3、使用ipso改进的粒子群优化算法对cbank-hn-gru分类模型进行优化;
9、s4、使用flash attention加速算法模块对cbank-hn-gru分类模型训练进行加速;
10、s5、ipso-chrfa模型的训练与验证。
11、优选的,s1步骤具体为:
12、s1.1、使用adobe audition软件对原始10种海洋哺乳动物叫声和1种噪声音频进行降噪、声音增强、回声消除、咔嗒声去除等操作;
13、s1.2、从经过预处理的海洋哺乳动物叫声音频中提取梅尔频谱特征;包括对原始音频进行降噪、增幅、分帧、傅里叶变换、梅尔滤波器数据处理和离散余弦变换,最后得到尺寸大小为(513,800)的梅尔频谱特征;
14、s1.3、将所有的梅尔频谱特征以及其对应的标签通过指定比例随机划分为训练集、测试集和验证集,比例为0.8:0.1:0.1。
15、优选的,s2步骤具体为:
16、s2.1、搭建模型开始的cbank网络;
17、cbank网络是由卷积核从1到k的k个并行1d-cnn层组成的,k个卷积核不同的并行1d-cnn层可以有效捕获叫声音频不同时间尺度上的特征;cbank网络的后面是十六个batchnorm1d层,为cbank里的每个并行的1d-cnn层后面添加一个batchnorm1d层,以提高模型训练的稳定性;之后又加了两层1d-cnn层和一层batchnorm1d层,来减少cbank网络输出的通道数;再后面是maxpooling层,用于减少音频时间序列数据的维度,同时增加局部不变性,保留最重要的特征;此时池化操作的窗口大小为2,保持步长stride=1,来保持原始的时间分辨率,以避免因池化操作导致的序列长度缩减太多;其maxpooling层的公式如下所示:
18、;
19、其中,fij是输入特征图上的元素,i、j表示特征图上的索引位置,s是步长,k、l是在池化窗口内部遍历的索引,window是池化窗口的大小,定义了进行最大值操作的区域范围;
20、s2.2、在cbank网络的后面连接hn高速网络;
21、将hn高速网络设置为了n层,每一层的单元维度都是513,对应音频的梅尔频谱的频率维度大小,即梅尔滤波器组的数量,来提取更加高级的特征;hn高速网络通过其门控机制,缓解模型训练时的梯度消失问题,并且有助于改善模型的信息流动,使模型能更快地收敛到较优的性能;hn高速网络的输入的是x,则对于每个hn层,输出y公式计算如下:
22、;
23、其中,h是非线性变换,通过relu激活函数;t是转换门,通过sigmoid函数;c是载波门,通常设置为c(x)=1-t(x),wh和wt分别表示非线性变换和转换门的权重;
24、s2.3、在hn高速网络的后面添加gru双向门控制单元网络;
25、将gru双向门控制单元网络设置为了双向、m层的网络,使gru双向门控制单元在处理序列数据时,不仅从前向后处理数据,还从后向前处理数据,可以捕获序列中的前后文信息,进一步提高模型的性能。
26、优选的,s3步骤具体为:
27、s3.1、设计并搭建使用量子计算技术和混沌算法来改进ipso粒子优化算法模型;
28、使用混沌映射来初始化粒子群的位置和速度,公式为:
29、;
30、;
31、其中,xmin、xmax 分别定义了粒子位置向量的最小值和最大值,vmin、vmax分别定义了粒子速度向量的最小值和最大值,并用来定义粒子位置和速度的取值范围;chaos(x0)是一个迭代产生混沌序列的函数;x0和v0 是在区间(0,1)内的随机初始值;
32、在粒子的速度更新中引入了量子概率云,新的速度更新公式为:
33、;
34、其中,mbest(t)是群体粒子最佳位置的平均值,β是控制搜索范围的系数量子势阱宽度,是第i个粒子在第t次迭代的服从(0,1)均匀分布的随机数;
35、在位置更新中引入量子位的坍缩行为,以及混沌理论来增强多样性,新的位置更新公式为:
36、;
37、其中,xi(t+1)表示粒子下一时刻的位置,xi(t)表示粒子当前的位置,vi(t+1)表示粒子下一刻的速度,chaos(xi(t))表示粒子当前位置的混沌映射值;
38、s3.2、使用ipso改进的粒子群优化算法优化cbank-hn-gru分类模型;
39、使用ipso改进的粒子群优化算法来自动寻找cbank-hn-gru分类模型内部参数的最优值,以及确定cbank模型中并行cnn层的数量k、hn高速网络的层数n、gru双向门控制单元网络的层数m、模型训练时的learning-rate学习率和batch-size批量大小。
40、优选的,s4步骤具体为:
41、s4.1、设计并搭建flash attention算法模块;
42、flash attention加速算法模块通过单独计算softmax的归一化因子,来实现解耦并以此来节省显存,定义softmax的归一化因子为:
43、;
44、其中,qi是模型输入序列矩阵的第i列,qit是其转置,kj是查询向量相关序列矩阵的第j列;当输入的序列长度为n时,p是(n,n)的矩阵,则输出o的第i个列向量oi为:
45、;
46、其中,vj为输入序列中各个位置具体信息矩阵的第j个列,p是注意力矩阵,pij表示p矩阵第i行第j列的元素,li是归一化因子;在计算得到归一化因子li 后,通过反复累加来得到oi;因此,通过改变计算顺序,相比于标准注意力,将显存复杂度从 o(n2) 降低到了o(n);
47、针对内存受限的标准注意力,flash attention加速算法模块是io感知的,目标是避免频繁地从hbm中读写数据;通过kernel融合的操作来减少对hbm的读写次数,有效利用更高速的sram来进行计算,最后将计算结果写入到hbm中,将多个操作融合成一个操作,减少读写hbm的次数,极大的加快了计算速度;
48、s4.2、使用flash attention加速算法模块加速cbank-hn-gru分类模型的训练速度。
49、优选的,s5步骤具体为:
50、s5.1、ipso-chrfa整体模型的分类训练;
51、训练网络都是使用主流深度学习框架pytorch编写的,在模型训练时还引入了提前停止策略;训练中使用的激活函数是自正则化非单调激活函数mish,mish的公式为:
52、;
53、其中x表示激活的输入,tanh表示双曲正切函数,softplus表示软正数激活函数,ln表示自然对数函数;
54、s5.2、使用acc、auc、map、f1score和kappa系数6个评价指标来验证模型的性能;
55、acc指的是准确率,是评估分类模型性能的一个基本指标,准确率表示模型正确预测的样本数占总样本数的比例,acc值越高,模型的性能越优;
56、auc即roc曲线下的面积,是评估分类器整体性能的一个指数,auc值越高,模型的性能越优;
57、map是一个在多类别对象检测和信息检索领域常用的评价指标,其计算的是平均精确率(average precision,ap)的平均值,map值越高,模型的性能越优;
58、f1score是衡量模型精确度的一个指标,f1分数提供一个同时考虑精确率和召回率的单一指标,特别适合于类别不平衡的情况;f1分数的范围从0到1,其中1表示最佳可能的性能,0表示最差的性能;
59、kappa系数是一个评价分类准确性的统计量,特别用于量化两个评价者或评价系统对同一个数据集分类一致性的程度;当k的值接近1时,表示预测一致性很高;当k的值接近0时,表示没有比随机预测更好的一致性;当k的值为负数时,表示一致性比随机预测还要差。
60、本发明的有益效果:
61、本发明的基于ipso-chrfa模型的海洋哺乳动物叫声分类方法,能够准确捕捉并识别分类各种复杂的叫声以及噪音,降低训练时间,且还具备高效、稳定的特点,以适应海洋环境的复杂性和多变性,实现对海洋哺乳动物叫声的高效分类,为海洋哺乳动物叫声信号识别分类任务提供了一种高效而灵活的解决方案,同时为其他领域的声音识别任务提供了新的思路。
62、其ipso-chrfa模型结合了ipso改进的粒子群优化算法、cbank卷积银行、hn高速网络、gru双向门控制单元网络和flash attention加速算法模块,其ipso改进的粒子群优化算法可以对网络模型的参数进行优化,提高模型的分类精度;同时hn高速网络由于其高效的信息流动机制,可以加速深层网络的训练过程;且gru双向门控制单元网络使网络能够在序列的不同部分保留或忘记信息,使其可以更有效地处理音频数据;另外flash attention是一种重新排序注意力计算的算法,它利用平铺、重计算等经典技术来显著提升计算速度,并将序列长度中的内存使用实现从二次到线性减少,给模型的训练过程带来了显著时间加速。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24424.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。