一种结合自回归的端到端的文本合成语音方法及系统与流程
- 国知局
- 2024-06-21 11:56:24
本发明涉及语音合成,具体涉及一种结合自回归的端到端的文本合成语音方法及系统。
背景技术:
1、近年来,文本转语音(text to speech,tts)取得了显著进展。目前最先进的tts方法可以分为端到端和零样本(zero shot)方法。
2、端到端的tts技术是一种革命性的方法,它允许直接从文本生成自然流畅的语音,无需复杂的中间步骤。端到端tts模型的核心思想是将文本直接映射到语音波形,通常通过神经网络来实现。这种模型的优势在于简化了系统架构,使得整个语音合成过程更加高效和直接。通过端到端的方法,tts系统可以更好地捕捉文本和语音之间的关联,从而生成更加自然、流畅的语音输出,并能够合成单个或多个说话这的高质量语音。相关工作有tacotron2,fastspeech,vits等。
3、zero-shot tts是一种语音合成技术,可以在没有特定说话人的语音样本或者仅有非常有限的训练数据的情况下生成语音。这种技术的核心思想是通过利用先进的生成模型和表示学习技术,使得系统能够从文本直接生成自然流畅的语音,而无需针对特定说话人进行训练。一般来说需要利用在数万小时规模数据集上训练的大规模生成模型来执行零样本tts,比如vall-e、xtts、yourtts等。这些强大的模型可以有效地合成语音,只需一个单一的语音提示,消除了对大量数据准备的需求。
4、基于端到端的tts方法虽然简化了系统架构并提高了训练效率,但是也存在一些缺陷。一:要克隆一个声音,需要该声音的大量数据来进行训练,对数据依赖性较高。二:生成的语音情感信息较差,语音语调比较平。而zero shot方法依赖于数万小时规模的数据集,可以无须针对训练,只需要5s左右的目标音频,就能够克隆声音。然而目前的zero shottts方法,主要是通过对音频离散化处理,将音频表征为离散code,套用大语言模型的自回归训练方式训练相关模型,最后根据模型的输出,来使用相关的解码部件。这样的方法带来了一些缺陷,一:模型生成的声音稳定性差,容易出现吞字、变调以及怪音出现。二:只能利用3-10秒的短提示音频,短提示音频里的信息量不足以引导模型学习到个人的说话风格,比如个人说话的韵律、发音习惯等。三:自回归生成音频速度的较慢,假设1秒中的音频编码为75个token,生成1秒的音频就需要推理75次!另外,为了获取更好的音频效果,一般还会采取多次推理,取更好推理结果,速度更慢了。根据vall-e模型实践,生成1分钟的音频,需要1至2分钟的等待时间。
技术实现思路
1、本发明提供了一种结合自回归的端到端的文本合成语音方法及系统,能至少部分的改善上述问题。
2、为实现上述目的,本发明采用以下技术方案:
3、一种结合自回归的端到端的文本合成语音方法,其包括:
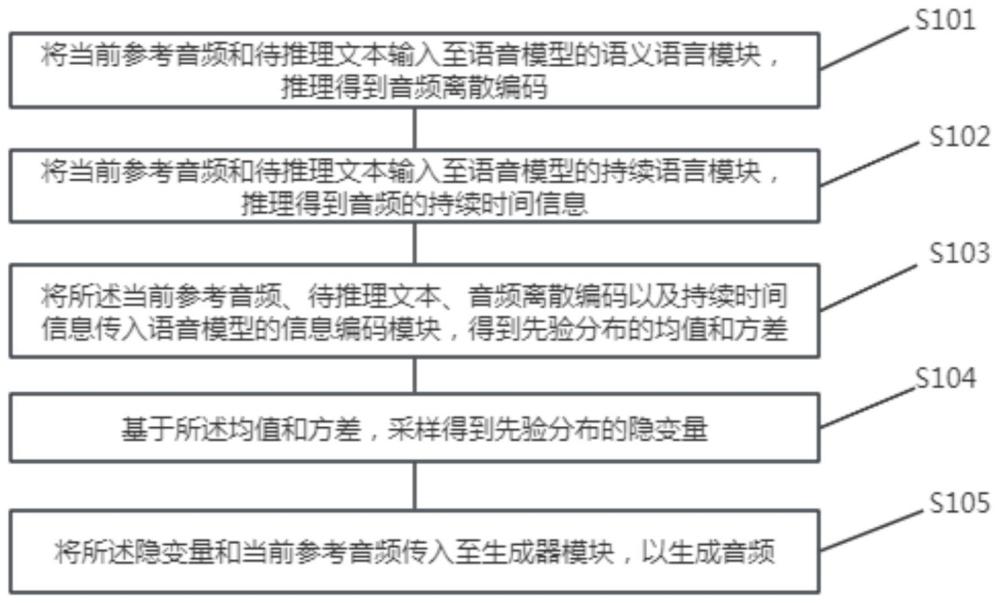
4、将当前参考音频和待推理文本输入至语音模型的语义语言模块,推理得到音频离散编码;
5、将当前参考音频和待推理文本输入至语音模型的持续语言模块,推理得到音频的持续时间信息;
6、将所述当前参考音频、待推理文本、音频离散编码以及持续时间信息传入语音模型的信息编码模块,得到先验分布的均值和方差;
7、基于所述均值和方差,采样得到先验分布的隐变量;
8、将所述隐变量和当前参考音频传入至生成器模块,以生成音频。
9、优选地,在推理得到音频离散编码时:
10、基于语音模型的hubert模块对所述当前参考音频进行编码,其编码结果表示为,其中表示当前参考音频的时间长度,50为当前参考音频的帧率,表示隐藏维度,表示数值是实数域的、维度是多维的;
11、利用一维卷积和多层rvq残差模块,将当前参考音频的帧率从50帧降25帧,再将其进行压缩,得到音频离散编码。
12、优选地,所述持续时间信息为音素级别的信息,将持续时间信息通过持续投影层,在音素级别上与所述待推理文本对齐,以使语音模型获知每个音素应该发音的时间。
13、优选地,所述语音模型在训练时候采用对抗网络的训练方式,其训练目标是是最大化变分下界elbo,最大化似然的公式为:
14、
15、其中,表示给定文本的隐变量的先验分布,是数据样本的似然函数,是近似后验分布;
16、得到训练损失为-elbo,其中,训练损失为重构损失和kl散度的和,其取值为:。
17、优选地,单次前向后向的训练流程具体为:
18、获取作为训练样本的音频的线性谱,将所述线性谱通过语义量化模块,得到音频离散编码,表示当前音频的长度,表示隐藏维度;
19、将音频离散编码、持续时间信息、文本音素、以及线性谱输入至信息编码模块,得到当前训练样本的后验分布的均值和方差;
20、将线性谱输入后验编码器,获取当前训练样本的后验分布的均值、方差、以及隐变量;
21、将所述后验分布的隐变量和线性谱通过流模块进行仿射变换,得到仿射结果;
22、将所述后验分布的隐变量和线性谱,通过生成器模块,采样生成音频;
23、分别将所述音频和线性谱转成mel频谱和,并计算重构损失;
24、根据所述仿射结果、先验分布的均值、后验分布的均值、后验分布的方差计算kl散度;
25、鉴别器根据所述kl散度计算生成损失,其中,所述鉴别器使用了hifi-gan的多周期鉴别器;
26、计算音频离散编码解码和编码结果的mse损失;
27、根据各个模块的损失,对语音模型的参数进行调整。
28、优选地,所述流模块为可逆,其通过多个仿射耦合层,提升高斯分布的分布复杂程度,从而提高所述语音模型的表达能力。
29、本发明实施例还提供了一种结合自回归的端到端的文本合成语音系统,其包括:
30、语义语言模块,用于将当前参考音频和待推理文本输入至语音模型的语义语言模块,推理得到音频离散编码;
31、持续语言模块,用于将当前参考音频和待推理文本输入至语音模型的持续语言模块,推理得到音频的持续时间信息;
32、信息编码模块,用于将所述当前参考音频、待推理文本、音频离散编码以及持续时间信息传入语音模型的信息编码模块,得到先验分布的均值和方差;
33、先验编码模块,用于基于所述均值和方差,采样得到先验分布的隐变量;
34、生成器模块,用于将所述隐变量和当前参考音频传入至生成器模块,以生成音频。
35、本发明提供了一种结合自回归的端到端的文本合成语音方法及系统,该方法的核心在于,引入的两个自回归模型slm和dlm,先基于语音模型对音频进行编码,降低音频的帧率,将再其压缩为离散码本;这意味着,要生成3秒的音频,slm理论上仅需推理75个token即可,相比于纯自回归的文本生成语音模型,例如vall-e快了3倍以上。同时,针对于自回归文本生成语音模型容易吞字问题,引入了音素级别的持续时间信息,将持续时间信息通过持续投影层(duration project),在音素级别上与文本对齐,使模型知道每个音素应该发音的时间。最后,基于参考音频、待推理文本、音频离散编码以及持续时间信息,得到合成音频;从而解决了纯自回归文本到语音模型推理速度慢、容易吞字以及端到端模型需要依赖大量音频数据的问题。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24601.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表