一种基于不自然性的语音对抗样本检测方法
- 国知局
- 2024-06-21 11:57:12
本发明属于智能语音系统中的语音识别模型安全,具体涉及一种基于不自然性的语音对抗样本检测方法。
背景技术:
1、语音识别技术可以将语音转换成文本,目前已广泛应用于智能手机、汽车、工业控制终端等设备,能够实现语音控制、语音转录、语音搜索等功能。现有研究表明,语音识别技术受到对抗攻击的威胁。在对抗攻击中,攻击者将恶意构造的对抗噪声叠加人类语音形成对抗样本,诱使语音识别模型输出错误的文本。在语音控制场景下,此类攻击会导致智能手机、摄像头、家电、车辆等设备发生恶意操作,威胁各类语音识别应用的安全运行。
2、现有研究提出了多种生成对抗样本的攻击方法,这些攻击使用了不同的可听性指标,如分贝失真、绝对听觉阈值、心理声学听觉等,在不同的可听性指标下生成的扰动具有不同的形态,同时也具有不同的自然度。分贝失真使用扰动和原始音频之间的强度比来表示扰动的可听性,通过将原始音频和扰动之间的信噪比固定在一个较大值来防止对抗噪声强度过大被人类发觉。使用分贝失真作为可听性指标时生成的对抗扰动在信号形态和听觉效果上都类似于白噪声,与正常的人类语音有较大的差别。这使得生成的对抗样本自然度较差,容易被人类分辨。与之相对的是心理声学听觉掩映方案,此方案利用了心理声学的理论,即对于人类听觉来说,高能量声音能掩盖和它相似频率和时间点的低能量声音。以此为可听性指标生成的扰动在时频域上的能量分布与原始音频类似,因此扰动听起来像人类的低语声,因此此类对抗样本自然度较好,攻击的隐蔽性好,难以被人类发现,但它仍保留了部分对抗特性。另外,绝对听觉阈值等其他可听性指标下生成的对抗样本性能在上述两者之间。
3、基于语音对抗样本与良性语音之间在信号形态上的差异,现有研究提出了多种检测语音对抗样本的方法,按照原理主要可以分为四类:(1)基于扰动敏感性,此类检测方法利用了对抗音频易被扰动的特性,通过对音频进行加噪、去噪、压缩、特征变换、重构、时域分割等操作,比较操作后和操作前音频的识别结果来区分正常音频和对抗样本;(2)基于模型迁移性,此类检测方法利用了对抗攻击在模型间的可迁移性差这一特点,使用多个语音识别模型或微调后的模型来识别音频,并根据不同模型识别结果的相似性来区分正常音频和对抗样本;(3)基于模型识别模式,此类检测方法利用了识别对抗样本和良性样本时模型识别中间值的不同来区分;(4)基于分类器分类,此类检测方法通过直接训练二分类器来区分正常音频和对抗样本。
4、基于扰动敏感性检测语音对抗样本的相关工作包括:
5、(1)kwon h等人在2019年的《proceedings of the acm sigsac conference oncomputer and communications security(acm ccs)》上发表的《poster:detecting audioadversarial example through audio modification》和tamurak等人在2021年的《proceedings of the ieee international workshop on computational intelligenceand applications(iwcia)》上发表的《protection method based on multiple sub-detectors against audio adversarial examples》,他们对音频进行低通滤波、下采样处理、音频静默去除、添加新的低电平失真等加噪或去噪处理,通过对比处理前和处理后音频的模型识别结果的相似性来检测对抗样本;
6、(2)yuan x等人在2018年的《proceedings of the usenix security symposium》上发表的《commandersong:asystematic approach for practical adversarial voicerecognition》和kwon h等人在2020年的《neurocomputing》上发表的《acoustic-decoy:detection of adversarial examples through audio modification on speechrecognition system》对音频进行mp3压缩、8位压缩等压缩处理,通过对比处理前和处理后音频的模型识别结果的相似性来检测对抗样本;
7、(3)mehlman n等人在2023年的《jasaexpress letters》上发表的《mel frequencyspectral domain defenses against adversarial attacks on speech recognitionsystems》和hussain s等人在2021年的《proceedings of the usenix securitysymposium》上发表的《waveguard:understanding and mitigating audio adversarialexamples》对音频进行量化-去量化、降采样-升采样、提取梅尔频谱-逆变换等特征变化处理,通过对比处理前和处理后音频的模型识别结果的相似性来检测对抗样本;
8、(4)wu s等人在2023年发表的《defending against adversarial audio viadiffusion model》、梁嘉烨等人在2023年的《科学技术创新》上发表的《基于bilstm-dnn的语音识别对抗样本防御研究》和魏春雨等人在2024年的《信息安全学报》上发表的《基于噪声破坏和波形重建的声纹对抗样本防御方法》对音频提取特征后利用wavegan声码器、线性预测编码等工具重新生成音频,通过对比处理前和处理后音频的模型识别结果的相似性来检测对抗样本;
9、(5)另外,yang z等人在2018年发表的《characterizing audio adversarialexamples using temporal dependency》、guo q等人在2020年的《ieee access》上发表的《multipad:amultivariant partition-based method for audio adversarial examplesdetection》和tamura k等人在2021年的《proceedings of the ieee internationalworkshop on computational intelligence and applications(iwcia)》上发表的《protection method based on multiple sub-detectors against audio adversarialexamples》将音频分割成片段,通过对比整条语音的识别结果和片段语音分别识别的结果的相似性来检测对抗样本。
10、基于模型迁移性检测语音对抗样本的相关工作包括zeng q等人在2019年的《proceedings of the annual ieee/ifip international conference on dependablesystems and networks(dsn)》上发表的《amultiversion programming inspiredapproach to detecting audio adversarial examples》、jayashankar t等人在2020年的《proceedings of the interspeech》上发表的《detecting audio attacks on asrsystems with dropout uncertainty》、choi y等人在2023年的《ieee access》上发表的《exploring diverse feature extractions for adversarial audio detection》、vyasa等人在2019年的《proceedings of the ieee international conference onacoustics,speech and signal processing(icassp)》上发表的《analyzinguncertainties in speech recognition using dropout》,他们利用不同架构、不同类型、随机丢弃不同神经元的语音识别模型来识别对抗样本,通过对比不同语音识别模型的识别结果的相似性来检测对抗样本。
11、基于模型识别模式检测语音对抗样本的相关工作包括akinwande v等人在2020年发表的《identifying audio adversarial examples via anomalous patterndetection》通过模型识别对抗样本和正常样本时激活的不同神经元来检测对抗样本;s等人在2020年的《proceedings of the interspeech》上发表的《detectingadversarial examples for speech recognition via uncertainty quantification》通过计算模型的预测不确定性来检测对抗样本;zong w等人在2022年的《journal ofimaging》上发表的《detecting audio adversarial examples in automatic speechrecognition systems using decision boundary patterns》通过模型识别对抗样本和正常样本时决策边界的不同来检测对抗样本;kwon h等人在2023年的《computers&security》上发表的《audio adversarial detection through classification score on speechrecognition systems》通过模型识别对抗样本和正常样本时softmax分数分布的不同来检测对抗样本。
12、基于分类器分类检测语音对抗样本的相关工作包括samizade s等人在2020年的《proceedings of the ieee international conference on acoustics,speech andsignal processing(icassp)》上发表的《adversarial exampledetection byclassification for deep speech recognition》、carlini n等人在2016年的《proceedings of the usenix security symposium》上发表的《hidden voicecommands》、马健等人在2022年的《东莞理工学院学报》上发表的《基于多频谱特征的音频对抗样本检测方法》,他们利用已知的某些对抗攻击来生成对抗样本,利用这些样本和语料库中的原始语音来训练二分类器用以检测对抗样本。
13、上述工作从多个角度对对抗样本和良性语音进行区分,但所提出的方法未考虑语音对抗样本不自然性这一本质特点,检测效果均具有一定的局限性,如利用扰动敏感性和模型迁移性的检测方法仅在检测鲁棒性差的对抗样本时有效,直接利用对抗样本训练的分类器难以检测未经训练的对抗攻击。
技术实现思路
1、对于上述存在的问题,本发明针对语音识别模型的对抗攻击,提出了一种基于不自然性的语音对抗样本检测方法。首先提出了对抗样本的四类适用于机器学习的不自然性相关的共性特征,并针对每一种不自然性相关的共性特征提出了若干个声学-统计特征用于描述此类不自然性。最后设计了一种轻量化的语音对抗样本检测器,实现了基于自然度评估的语音对抗样本检测。
2、本发明是通过以下技术方案得以实现的:
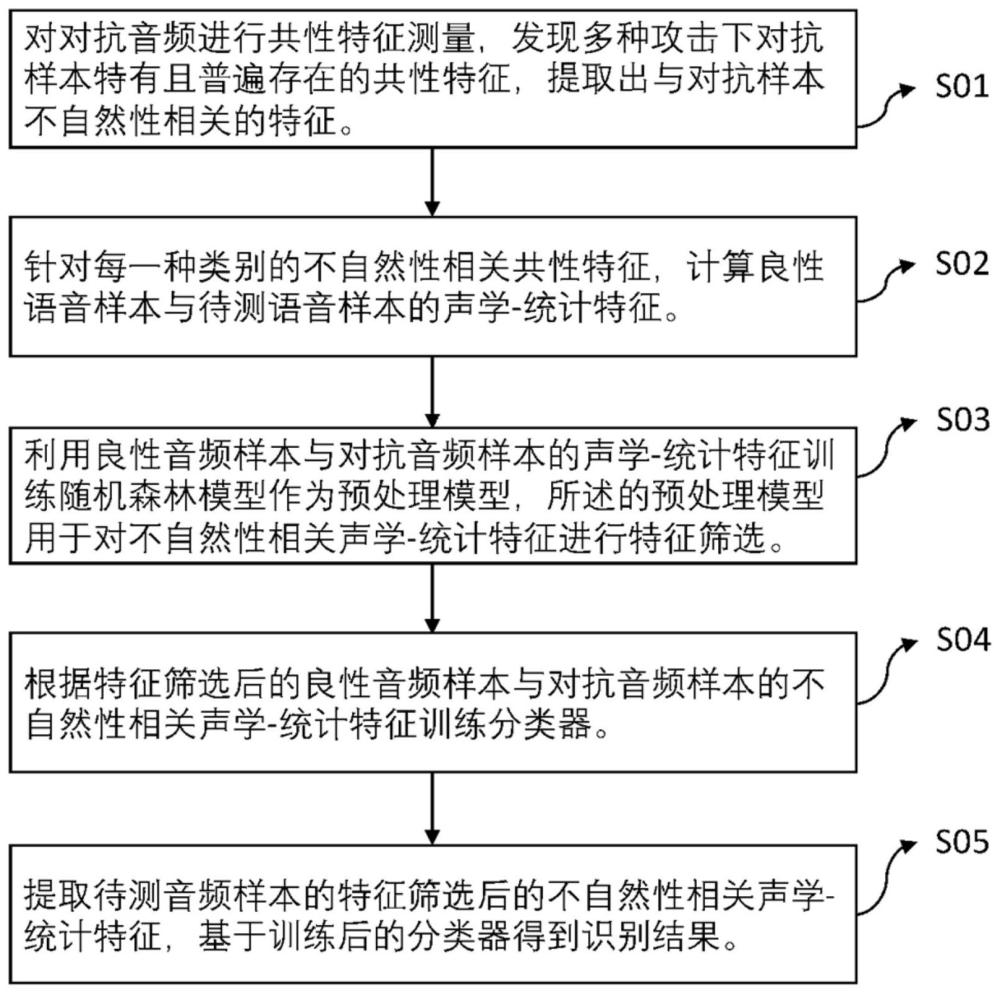
3、一种基于不自然性的语音对抗样本检测方法,包括以下步骤:
4、(1)获取对抗音频与不自然性相关的共性特征,所述的与不自然性相关的共性特征包括四种类型,分别为时域信号不连续、频域信号不连续、时域信号不规律、频域信号不规律;
5、(2)针对每一种类别的不自然性相关共性特征,计算良性音频样本与对抗音频样本的不自然性相关声学-统计特征;
6、(3)利用良性音频样本与对抗音频样本的不自然性相关声学-统计特征训练随机森林模型作为预处理模型,所述的预处理模型用于对不自然性相关声学-统计特征进行特征筛选;
7、(4)根据特征筛选后的良性音频样本与对抗音频样本的不自然性相关声学-统计特征训练分类器;
8、(5)提取待测音频样本的特征筛选后的不自然性相关声学-统计特征,基于训练后的分类器得到识别结果。
9、进一步地,所述时域信号不连续对应的不自然性相关声学-统计特征包括频谱图中峰的差值、频谱包络中共振峰的差值、线性预测编码的余弦距离、线性预测编码的欧式距离。
10、进一步地,所述频域信号不连续对应的不自然性相关声学-统计特征包括频谱图中峰的高度、频谱图中峰的宽度、频谱图中峰的峰度、频谱包络中共振峰高度、频谱包络中共振峰宽度、频谱包络中共振峰峰度、频谱包络中共振峰数量。
11、进一步地,所述时域信号不规律对应的不自然性相关声学-统计特征包括线性预测编码的长度、线性预测编码的自相关性、线性预测编码的过零率、线性预测编码的周期、线性预测编码的过零点距离。
12、进一步地,所述频域信号不规律对应的不自然性相关声学-统计特征包括频谱图中峰的自相关率、频谱图中频谱幅值的自相关率、频谱图中频谱幅值的过零率、频谱图中峰的周期、频谱图中频谱幅值的周期、频谱图中频谱幅值的过零点距离。
13、进一步地,所述的特征筛选过程包括:
14、(3.1)计算音频的不自然性相关声学-统计特征;
15、(3.2)针对每一个不自然性相关声学-统计特征,计算其概率累积分布函数,并从概率累积分布函数中选择均匀分布的n个特征值作为该不自然性相关声学-统计特征的特征向量,表示为:
16、xin={x|0.01k=fcdf(x),k=1,2,...,n}
17、
18、其中,x表示特征点,fcdf表示音频的某一不自然性相关声学-统计特征对应的概率累积分布函数,k表示自然数,xin表示特征点集合,xi表示特征向量中的第i个特征值,表示特征向量;
19、(3.3)将m×n维的输入特征训练一个随机森林模型作为预处理模型实现特征筛选,先通过特征排序从m×n维的输入特征中选取m’个权重排序靠前的声学-统计特征,再通过特征排序从m’×n维的输入特征中选取n’个权重排序靠前的特征值,输出m’×n’维的特征作为特征筛选后的结果。
20、进一步地,经过特征筛选后的特征中包含的声学-统计特征为:频谱图中峰的差值、线性预测编码的余弦距离、线性预测编码的欧式距离、频谱图中峰的高度、频谱图中峰的宽度、频谱图中峰的峰度、频谱包络中共振峰高度、频谱包络中共振峰宽度、频谱包络中共振峰峰度、频谱包络中共振峰数量、线性预测编码的长度、线性预测编码的过零率、线性预测编码的过零点距离、频谱图中峰的自相关率、频谱图中频谱幅值的自相关率、频谱图中频谱幅值的周期。
21、进一步地,所述的分类器由一个z-score归一化层和线性核的支持向量机组成。
22、进一步地,用于训练所述分类器的对抗音频样本基于不同的对抗攻击方式生成,包括白盒攻击、黑盒攻击、生成式攻击、通用扰动攻击,且不同的对抗攻击方式覆盖多种不同的语音识别模型。
23、进一步地,采用交叉验证方法训练所述的分类器。
24、本发明具有以下有益效果:
25、(1)本发明通过测量多种攻击下对抗音频的共性特征,根据这些共性特征的产生原因和与对抗攻击原理之间的联系,提出了与对抗样本不自然性相关的且适用于机器学习的特征,总结为时域信号不连续、频域信号不连续、时域信号不规律、频域信号不规律四类。通过在多种攻击下均存在的对抗样本的固有属性,弥补了现有研究在语音对抗样本本质特点探究方面的缺失,有助于对抗样本的检测与防御。
26、(2)本发明设计了用于描述语音不自然性的声学-统计特征,基于声学-统计特征设计了一种轻量级的对抗样本检测器,能够实现多种对抗攻击的检测。具体的,本发明首先根据语音的声学-统计特征提取得到若干特征向量。接着,训练随机森林模型作为预处理模型对输入特征向量进行降维和优化,完成特征筛选。基于特征筛选后的输入特征设计了一个二分类器用于检测对抗样本。本发明提出的对抗样本检测器输入数据维数低、模型参数少,是一种轻量级、易部署的检测方法,在利用少量已有对抗攻击的对抗样本训练分类器的情况下,可实现多种对抗攻击样本的检测,具有较高的应用价值。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24691.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表