神经网络定向拾音方法、系统及可读存储介质与流程
- 国知局
- 2024-06-21 11:57:11
本发明涉及音频信号处理,尤其涉及一种神经网络定向拾音方法、系统及可读存储介质。
背景技术:
1、语音增强技术,通常是指对语音信号进行降噪处理,在通讯技术日益发达的今天,有着非常广泛的应用场景。多麦克风语音增强算法利用空间信息对目标方向的声音进行增强,不仅可以抑制平稳噪声,也可以抑制非目标方向的非平稳噪声。该算法可粗略分为两类:求和算法和差分算法。求和算法也称为加性算法,包括delay&sum,mvdr,gsc等算法,优点是通用性好,失真小,缺点是低频指向性不好;差分算法通过设置零点,可以完全抑制掉非目标方向声音,缺点是低频通过补偿后底噪容易被放大,对麦克风间距有要求。无论是麦克风阵列求和算法还是差分算法,本质上都是利用阵列信号的相位关系进行的空域滤波。当然,也有的算法同时利用求和的频谱与差分的频谱求得增益,将增益作用于频谱进行增强。
2、但是在实践中发现,对于传统的定向拾音算法,目标方向声音的保留程度与非目标方向声音的抑制程度是不容易同时满足的。尤其在目标声音中混杂着非目标声音时,只能对非目标声音进行一定程度的削弱,如果想要完全抑制非目标声音,则目标声音也面临损失的风险。
技术实现思路
1、本发明的目的在于提供一种神经网络定向拾音方法、系统及可读存储介质,相比于传统的定向增强算法,在资源消耗提升不大的情形下能够对增强方向的声音进行更好的保留同时对非增强方向的声音进行更好的抑制。
2、为达到上述目的,本发明提供一种神经网络定向拾音方法,包括:
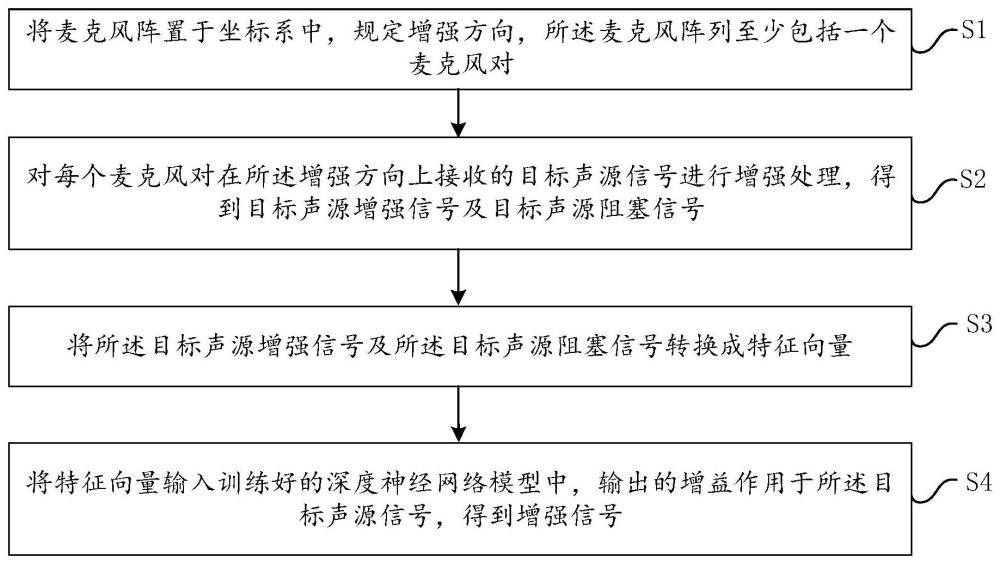
3、将麦克风阵置于坐标系中,规定增强方向,所述麦克风阵列至少包括一个麦克风对;
4、对每个麦克风对在所述增强方向上接收的目标声源信号进行增强处理,得到目标声源增强信号及目标声源阻塞信号;
5、将所述目标声源增强信号及所述目标声源阻塞信号转换成特征向量;
6、将特征向量输入训练好的深度神经网络模型中,输出的增益作用于所述目标声源信号,得到增强信号。
7、可选的,对每个麦克风对在所述增强方向上接收的目标声源信号进行增强处理的步骤具体包括:
8、计算所述目标声源信号到达所述麦克风对中两个麦克风的时间差;
9、根据所述时间差进行时延补偿,分别计算出两个所述麦克风的补偿频谱;
10、对两个所述麦克风的补偿频谱进行求和以及求差分,得到所述目标声源增强信号及所述目标声源阻塞信号。
11、可选的,两个所述麦克风的补偿频谱在所述增强方向上完全对齐。
12、可选的,将所述目标声源增强信号及所述目标声源阻塞信号转换成特征向量的步骤具体包括:
13、将所述目标声源增强信号及所述目标声源阻塞信号乘以梅尔频谱转化矩阵转换成所述特征向量。
14、可选的,将特征向量输入训练好的深度神经网络模型中,输出的增益作用于所述目标声源信号,得到增强信号的步骤具体包括:
15、将所述特征向量输入训练好的深度神经网络模型中,输出梅尔频谱增益;
16、将所述梅尔频谱增益乘以所述梅尔频谱转化矩阵的伪逆矩阵得到傅里叶频谱增益;
17、将所述傅里叶频谱增益作用于所述目标声源信号的频谱,转换后得到所述增强信号。
18、可选的,将特征向量输入训练好的深度神经网络模型之前,所述神经网络定向拾音方法还包括构建并训练所述深度神经网络模型,具体包括:
19、基于两个所述麦克风接收到的来自不同声源的麦克风信号,生成两个所述麦克风的频域信号;
20、对两个所述麦克风的频域信号进行求和以及求差分,得到求和信号及差分信号;
21、将所述求和信号及所述差分信号乘以梅尔频谱转化矩阵转换成梅尔频谱向量;
22、构建深度神经网络模型,将所述特征向量输入所述深度神经网络模型中并对所述深度神经网络模型进行训练。
23、可选的,当所述麦克风大于等于两对时,对每个麦克风对求所述增益,并将多个所述增益求平均值或者求最小值后所述目标声源信号,得到所述增强信号。
24、可选的,将所述增益作用于所述目标声源信号之前,所述神经网络定向拾音方法还包括:
25、利用波束形成算法预先对所述麦克风阵列进行预处理;
26、将所述增益作用于所述目标声源信号,通过加窗、idft及重叠保留得到所述增强信号。
27、基于同一技术构思,本发明还提供了一种神经网络定向拾音系统,包括:
28、定向模块,被配置为将麦克风阵置于坐标系中,规定增强方向,所述麦克风阵列至少包括一个麦克风对;
29、处理模块,被配置为对每个麦克风对在所述增强方向上接收的目标声源信号进行增强处理,得到目标声源增强信号及目标声源阻塞信号;
30、转换模块,被配置为将所述目标声源增强信号及所述目标声源阻塞信号转换成特征向量;
31、增强模块,被配置为将特征向量输入训练好的深度神经网络模型中,输出的增益作用于所述目标声源信号,得到增强信号。
32、基于同一技术构思,本发明还提供了一种可读存储介质,其上存储有计算机程序,所述计算机程序被执行时能实现如上所述的神经网络定向拾音方法。
33、在本发明提供的一种神经网络定向拾音方法、系统及可读存储介质中,相比于传统的定向增强算法,本发明在拾取增强方向中混杂着非增强方向的声音时,在资源消耗提升不大的情形下能够对增强方向的声音进行更好的保留同时对非增强方向的声音进行更好的抑制。
技术特征:1.一种神经网络定向拾音方法,其特征在于,包括:
2.根据权利要求1所述的神经网络定向拾音方法,其特征在于,对每个麦克风对在所述增强方向上接收的目标声源信号进行增强处理的步骤具体包括:
3.根据权利要求2所述的神经网络定向拾音方法,其特征在于,两个所述麦克风的补偿频谱在所述增强方向上完全对齐。
4.根据权利要求1所述的神经网络定向拾音方法,其特征在于,将所述目标声源增强信号及所述目标声源阻塞信号转换成特征向量的步骤具体包括:
5.根据权利要求4所述的神经网络定向拾音方法,其特征在于,将特征向量输入训练好的深度神经网络模型中,输出的增益作用于所述目标声源信号,得到增强信号的步骤具体包括:
6.根据权利要求1所述的神经网络定向拾音方法,其特征在于,将特征向量输入训练好的深度神经网络模型之前,所述神经网络定向拾音方法还包括构建并训练所述深度神经网络模型,具体包括:
7.根据权利要求1所述的神经网络定向拾音方法,其特征在于,当所述麦克风大于等于两对时,对每个麦克风对求所述增益,并将多个所述增益求平均值或者求最小值后所述目标声源信号,得到所述增强信号。
8.根据权利要求1所述的神经网络定向拾音方法,其特征在于,将所述增益作用于所述目标声源信号之前,所述神经网络定向拾音方法还包括:
9.一种神经网络定向拾音系统,其特征在于,包括:
10.一种可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被执行时能实现根据权利要求1-8中任一项所述的神经网络定向拾音方法。
技术总结本发明涉及音频信号处理技术领域,尤其涉及一种神经网络定向拾音方法、系统及可读存储介质,方法包括以下步骤:将麦克风阵置于坐标系中,规定增强方向,麦克风阵列至少包括一个麦克风对;对每个麦克风对在增强方向上接收的目标声源信号进行增强处理,得到目标声源增强信号及目标声源阻塞信号;将目标声源增强信号及目标声源阻塞信号转换成特征向量;将特征向量输入训练好的深度神经网络模型中,输出的增益作用于目标声源信号,得到增强信号。相比于传统的定向增强算法,本发明在拾取增强方向中混杂着非增强方向的声音时,在资源消耗提升不大的情形下能够对增强方向的声音进行更好的保留同时对非增强方向的声音进行更好的抑制。技术研发人员:罗本彪,邹灵琦,居彩霞,董鹏宇,尹东受保护的技术使用者:上海富瀚微电子股份有限公司技术研发日:技术公布日:2024/6/11本文地址:https://www.jishuxx.com/zhuanli/20240618/24689.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。