一种基于AI卷积神经网络深度学习识别狗叫声的方法与流程
- 国知局
- 2024-06-21 11:55:57
本发明涉及一种用于犬训练器、止吠器、犬玩具电子产品等识别狗叫声的方法,尤其涉及一种基于ai卷积神经网络深度学习识别狗叫声的方法。
背景技术:
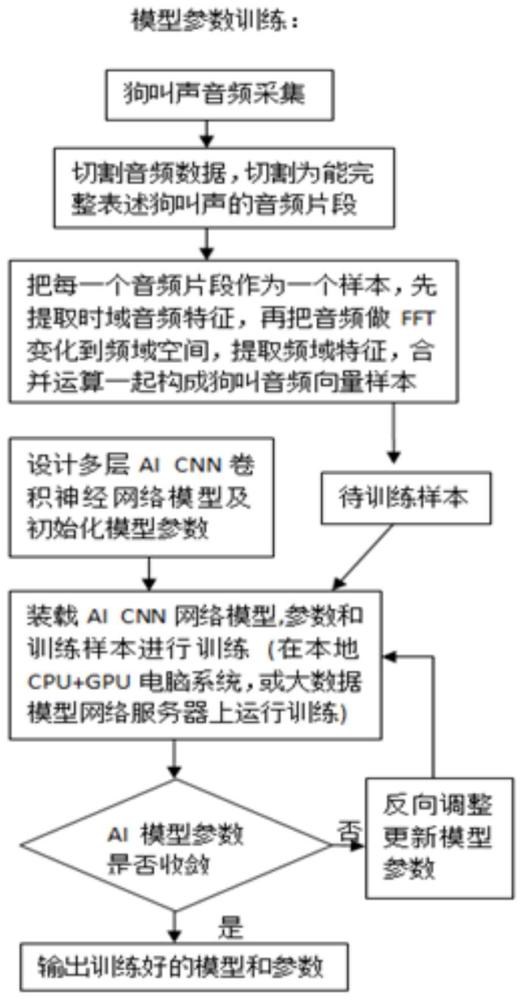
1、卷积神经网络是深度学习的代表算法之一,属于包含卷积计算且具有深度结构的前馈神经网络,卷积神经网络是在前馈神经网络的隐藏层做的改变,其隐藏层包括卷积层、池化层、全连接层三部分。其中,卷积层使用卷积核进行特征提取和特征映射,池化层于卷积层进行特征提取之后,输出的特征图会被传递至池化层进行特征选择和信息过滤,并且,池化层包含预设定的池化函数,其功能是将特征图中单个点的结果替换为其相邻区域的特征图统计量,池化层选取池化区域与卷积核扫描特征图步骤相同,由池化大小、步长和填充控制。此外,卷积神经网络的输入层可以处理多维数据,例如,二维卷积神经网络可处理二维或三维数组,三维卷积神经网络可处理四维数组。
2、本发明之技术方案是利用上述涉及的卷积神经网络深度学习技术来辅助识别狗叫声,目前的用于犬训练器、止吠器、宠物玩具产品等识别狗叫声的技术,均是基于对狗叫声音频分析、或者音频模板比对来实现的。由于狗的品种繁多,同一只狗于不同时刻、不同情绪状态下,其叫声不同且复杂,若仅用以往的音频分析的方式或者音频模板比对的方式来识别,会导致非常大的误判率,而且很难在技术上去突破和提高,不具备技术拓展的前景,无法用于需准确感知狗叫声的应用场合。
技术实现思路
1、为克服上述问题或者至少部分地解决或缓减解决上述问题,本发明提供一种基于ai卷积神经网络深度学习识别狗叫声的方法。
2、为实现上述目的,本发明采用以下技术方案:
3、一种基于ai卷积神经网络深度学习识别狗叫声的方法,用于犬训练器、犬止吠器、犬玩具电子产品的狗叫声识别,该方法包括基于ai卷积神经网络模型参数训练过程、模型部署及应用过程;
4、其中,基于ai卷积神经网络模型参数训练过程所采取的步骤依次为:
5、步骤ⅰ:采集不同品类的狗叫声并且同时采集不同年龄段的狗叫声,在采集的音频中进一步收集不同情绪时的狗叫声以及不同叫法的狗叫声,另外采集一定数量的非狗叫环境声音,为后期cnn训练时作为对照样板;
6、步骤ⅱ:对采集的每个音频均编辑截取为能正确表述一段狗叫声的音频片段,转为pcm格式音频样本供下阶段音频特征向量提取使用;
7、步骤ⅲ:将pcm格式音频样本进行时域能量参数提取,再进行fft频域变换,以便抽取音频的频域能量特征参数,一起运算组成音频特征向量集合,构成机器学习样本,提供给下一个阶段使用;
8、步骤ⅳ:利用机器学习工具tensorflow或pytorch构建卷积神经网络cnn深度学习模型,设计为5层卷积核,采用5x5,3x3的卷积核,每层卷积核运算从不同维度计算样本的特征参数,每层卷积运算串联,前级输出接后级输入,卷积运算最后层接全连接计算概率输出;
9、步骤ⅴ:借助于本地pc或网络ai大数据训练中心部署,输入cnn网络模型和提取的音频特征向量样本,输入反复计算,训练调整模型参数,直到模型收敛,训练结束,输出训练好的模型和参数,提供给终端产品进行模型部署和应用;
10、其中,模型部署及应用过程所采取的步骤依次为:
11、步骤ⅰ:将ai卷积神经网络cnn模型和参数,部署在有一定运算能力的终端电子应用产品;
12、步骤ⅱ:于应用产品工作中,录制一段音频,转为待处理的pcm格式;
13、步骤ⅲ:对pcm格式音频数据进行时域频域变换,抽取音频的时域频域特征参数,合并运算组成声音的特征向量;
14、步骤ⅳ:应用产品装载置入的网络模型和参数,对录入音频的特征向量按照模型的卷积核和卷积流程同模型参数进行多层卷积运行,最终通过全连接层输出计算概率结果。
15、对于以上过程或步骤所采取的技术手段,还可进一步实施,在进行模型部署时,所采取的方法步骤为:
16、将模型参数训练阶段导出的onnx格式的计算图及参数转换为方便读取解析的格式置入应用芯片的存储空间中,再将录音进来的音频数据按照样本参数提取的算法通过滤波提取语音特征向量图,最后按照置入的模型计算图结构,依次调用算子,参数对输入的音频特征向量图进行运算,运算到计算图最后线性层输出概率向量;概率向量同训练阶段样本标签进行判断,最终确定输入音频是否是狗叫声。
17、对于以上过程或步骤所采取的技术手段,还可进一步实施,模型参数训练过程的步骤ⅲ中,构成音频特征向量集合的方法为:
18、第一步,对前阶段截取的pcm音频样板进行特征参数提取时,先将音频按128字节分帧,形成1x750维度的时域能量向量;针对该1x750的能量向量建立32路滤波器组,调节滤波参数,对能量向量进行滤波运算,提取能量变化特征,最终形成二维32x188的时域特征向量,同频域特征向量共同合成样本特征向量;
19、第二步,再将音频按512字节分帧,进行fft频域变换,并计算频域能量,形成128x188的功率谱;针对该功率谱,按频率分为32段,建立32组滤波器组,调节滤波参数,对功率谱滤波运算,提取变化特征,最终形成32x188的频域特征向量;
20、第三步,合并时域和频域的特征向量,构成音频样本的特征向量nx64x188,制成狗声和非狗声的标签,以供深度学习。
21、对于以上过程或步骤所采取的技术手段,还可进一步实施,模型参数训练过程的步骤ⅳ,深度学习模型的建立的方法步骤为:
22、第一,先用torch.nn.module构建cnn网络模型,输入层输入前阶段训练好的声音特征向量nx64x188,中间通过5x5,3x3,5层卷积层,池化层,输出到线性层输出[0,1]维度;
23、第二,创建学习损失计算函数loss=torch.nn.crossentropyloss();
24、第三,创建学习优化器并配置训练参数optimizer=torch.optim.sgd();
25、第四,针对网络输入样本向量数据,循环训练,根据样本数量和质量设定需要训练的epoch,通过loss.backward(),optimizer.step()调整和更新网络参数;
26、第五,训练完成后,导出网络结构及网络参数模型计算图到onnx格式。
27、对于ai卷积神经网络cnn模型和参数所部署的终端电子产品,包括具备dsp或npu运算能力的芯片;芯片有存储空间用以预先置入cnn模型和参数;芯片算法支持onnx格式的模型计算图及参数。
28、另外,对于采集的狗叫声音频予以持续的收集。
29、本发明采用将pcm格式音频样本进行时域能量参数提取,再进行fft频域变换,以便抽取音频的频域能量特征参数,一起运算组成音频特征向量集合,最后借助于本地cpu+gpu架构或网络ai大数据训练中心部署,输入cnn网络模型和提取的音频特征向量样本,反复计算,训练调整模型参数,直到模型收敛,输出训练好的模型和参数,提供给终端产品进行模型部署和应用;因而,通过将卷积神经网络cnn深度学习训练的网络模型和模型参数部署于电子产品如犬训练器、犬止吠器、犬玩具类等,可精确检测是否有狗叫声,然后触发相关提示,提高狗叫声识别率,降低误判率;同时,还通过不断增加不同的样本给网络深度学习,有利于持续改善识别的准确度。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24552.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。