模型的训练方法、装置、终端设备和可读存储介质与流程
- 国知局
- 2024-06-21 11:55:51
本申请属于模型训练,尤其涉及一种模型的训练方法、装置、终端设备和可读存储介质。
背景技术:
1、数字人是一种通过数字技术模拟人类外形、声音、情感等特征的虚拟人物。它们具有高度的逼真度和灵活性,可以用于教育、医疗、游戏、娱乐、虚拟展览等应用场景。合成数字人主要用到计算机图形学、人工智能、语音识别和合成等技术。由于asr模型可以将口语转换为文本,因此可以利用asr模型来实现数字人的语音识别技术。在相关技术中,asr模型存在准确性低、泛化能力差的问题。
技术实现思路
1、本申请实施例提供一种模型的训练方法、装置、终端设备和可读存储介质,可以解决相关技术中asr模型准确性低、泛化能力差的问题。
2、第一方面,本申请实施例提供了一种模型的训练方法,包括:
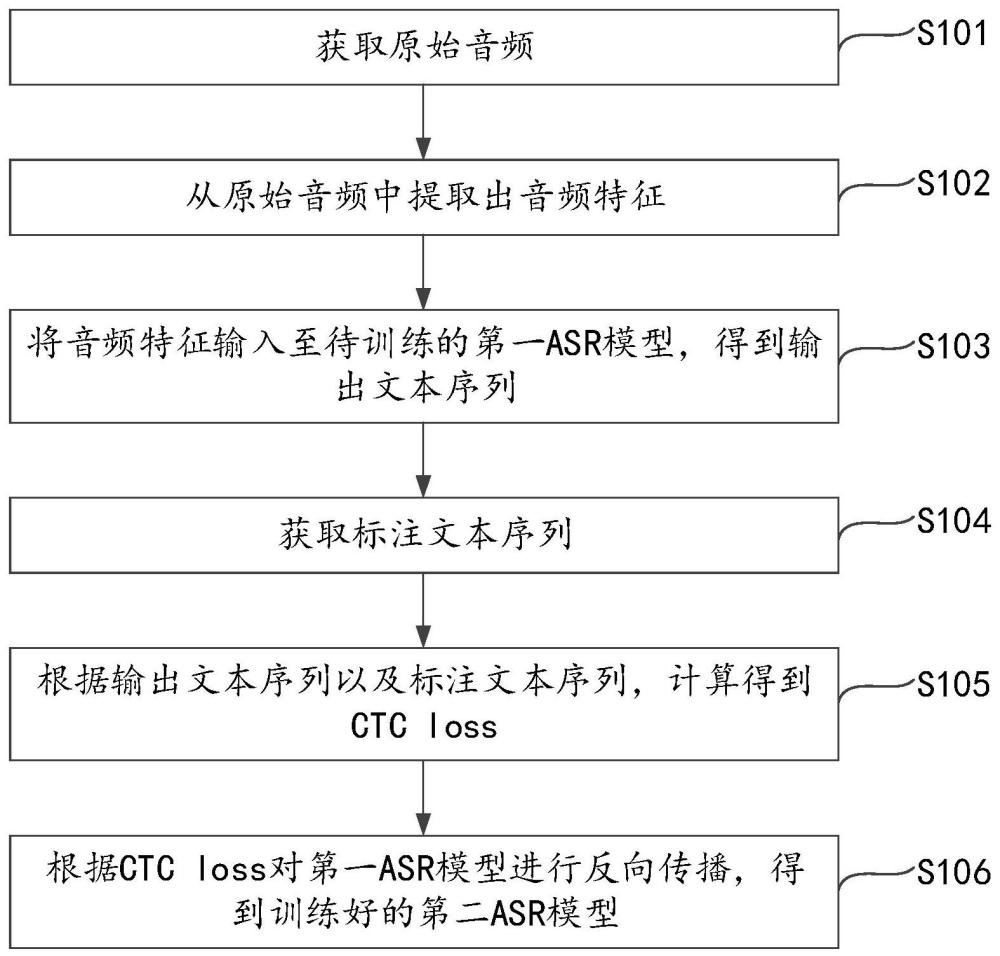
3、获取原始音频;
4、从所述原始音频中提取出音频特征;
5、将所述音频特征输入至待训练的第一asr模型,得到输出文本序列;
6、获取标注文本序列,所述标注文本序列基于所述原始音频得到;
7、根据所述输出文本序列以及所述标注文本序列,计算得到ctc loss;
8、根据所述ctc loss对所述第一asr模型进行反向传播,得到训练好的第二asr模型。
9、第二方面,本申请实施例提供了一种模型的训练装置,包括:
10、第一获取模块,用于获取原始音频;
11、提取模块,用于从所述原始音频中提取出音频特征;
12、输入模块,用于将所述音频特征输入至待训练的第一asr模型,得到输出文本序列;
13、第二获取模块,用于获取标注文本序列,所述标注文本序列基于所述原始音频得到;
14、计算模块,用于根据所述输出文本序列以及所述标注文本序列,计算得到ctcloss;
15、反向传播模块,用于根据所述ctc loss对所述第一asr模型进行反向传播,得到训练好的第二asr模型。
16、第三方面,本申请实施例提供了一种终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述模型的训练方法的步骤。
17、第四方面,本申请实施例提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述模型的训练方法的步骤。
18、第五方面,本申请实施例提供了一种计算机程序产品,当计算机程序产品在终端设备上运行时,使得终端设备执行上述模型的训练方法。
19、本申请实施例与现有技术相比的有益效果是:本申请实施例通过获取原始音频,并从原始音频中提取出音频特征,再将音频特征输入至待训练的第一asr模型,得到输出文本序列,并获取标注文本序列,再根据输出文本序列以及标注文本序列,计算得到ctcloss,最后根据ctc loss对第一asr模型进行反向传播,得到训练好的第二asr模型。本申请实施例根据待训练的第一asr模型输出的文本序列,与标注文本序列进行比较,计算得到ctc loss,也即确定二者的差异,再根据ctc loss对待训练asr模型进行优化,最终得到训练好的asr模型,使得训练好的asr模型提高了准确性以及泛化能力。
技术特征:1.一种模型的训练方法,其特征在于,包括:
2.如权利要求1所述的模型的训练方法,其特征在于,所述根据所述输出文本序列以及所述标注文本序列,计算得到ctcloss,包括:
3.如权利要求1所述的模型的训练方法,其特征在于,所述从所述原始音频中提取出音频特征,包括:
4.如权利要求1所述的模型的训练方法,其特征在于,所述将所述音频特征输入至待训练的第一asr模型,得到输出文本序列,包括:
5.如权利要求1所述的模型的训练方法,其特征在于,所述根据所述ctc loss对所述第一asr模型进行反向传播,得到训练好的第二asr模型,包括:
6.如权利要求1所述的模型的训练方法,其特征在于,在所述获取原始音频之后,所述从所述原始音频中提取出音频特征之前,所述方法还包括:
7.如权利要求1所述的模型的训练方法,其特征在于,所述获取标注文本序列,包括:
8.一种模型的训练装置,其特征在于,包括:
9.一种终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如权利要求1至7任一项所述模型的训练方法的步骤。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7任一项所述模型的训练方法的步骤。
技术总结本申请适用于模型训练技术领域,提供了一种模型的训练方法、装置、终端设备和可读存储介质。上述模型的训练方法包括:获取原始音频;从原始音频中提取出音频特征;将音频特征输入至待训练的第一ASR模型,得到输出文本序列;获取标注文本序列;根据输出文本序列以及标注文本序列,计算得到CTC loss;根据所CTC loss对第一ASR模型进行反向传播,得到训练好的第二ASR模型。本申请实施例根据待训练的第一ASR模型输出的文本序列,与标注文本序列进行比较,计算得到CTC loss,再根据CTC loss对待训练ASR模型进行优化,最终得到训练好的ASR模型,使得训练好的ASR模型提高了准确性以及泛化能力。技术研发人员:宋泽山受保护的技术使用者:上海积图科技有限公司技术研发日:技术公布日:2024/6/2本文地址:https://www.jishuxx.com/zhuanli/20240618/24543.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表