基于多源深度域泛化的帕金森病语音识别系统
- 国知局
- 2024-06-21 11:55:49
:本发明涉及智慧医疗技术,具体地说,是一种基于多源深度域泛化的帕金森病语音识别系统。
背景技术
0、背景技术:
1、帕金森病(pd)是一种多发于老年人的神经系统变性疾病,严重影响老年人群的晚年幸福。帕金森病不可治愈且具有不可逆性,只能通过早诊早治延缓病程。因此,帕金森病的早诊早治尤为重要。
2、构音障碍是pd的早期症状之一,由于其数据采集方便且无损,目前已经被广泛运用于pd的早期诊断。然而,受限于pd语音数据集的高混叠、小样本特性,使得传统的机器学习方法在pd语音识别上的性能较为有限。如何提升pd语音识别的准确率已成为相关领域学者或研究人员面临的关键科学问题。
3、针对pd语音样本的数据特性给机器学习方法带来的挑战,解决的主要思路是迁移学习。迁移学习利用单个或多个其他pd语音数据(以下称为“源域”)向目标pd语音数据(以下称为“目标域”)进行样本或知识迁移,进而提升目标域pd语音数据的模型训练效果,提升pd诊断的准确率。
4、迁移学习打破了目标域数据“量”的限制,利用源域数据中与目标域数据共同知识,协助模型训练目标域数据。迁移学习在pd诊断中的运用,目前主要集中在单源迁移学习。单源迁移学习方法借助单个源域pd语音数据集向目标域pd语音数据集迁移。虽然单源迁移学习方法一定程度上提升了目标域的机器学习分类性能,但受制于pd语音数据的小样本特性,导致单源迁移学习方法在单一源域pd语音数据上挖掘的知识有限,难以满足实现良好的机器学习的需求。因此,多源迁移学习方法应运而生。
5、多源迁移学习主要是利用多个源域数据向目标域数据进行迁移。为应对多源数据间的巨大分布差异,多源迁移学习方法主要集中在深度学习领域,即利用深度学习网络强大学习能力去消除多个源域数据之间的巨大分布差异。然而,深度迁移学习在pd语音识别方面的研究极其稀少,这与pd语音数据特性密切相关。一方面,多源pd语音数据集间的巨大分布差异需要深度学习网络协助消除;另一方面,深度学习网络需要大量的数据用于网络模型的参数优化。两者的需求难以同时满足,极易导致模型的过拟合与负迁移。
技术实现思路
1、针对现有技术的不足,本发明的目的是提供一种基于多源深度域泛化的帕金森病语音识别系统(以下简称“pd语音识别系统”),首先将多个含有标签信息的源辅助域pd语音数据与不包含标签信息的目标域pd语音数据作输入特征提取模块,尽可能地学习多源pd语音数据与目标域pd语音数据间的共有的内在不变特征。其次,本发明基于对抗思想,设计极大化多源辅助域pd语音数据类间分布差异与极小化多源辅助域pd语音数据与目标域pd语音数据域间分布差异的迁移准则,结合特征提取部分,设计了多源深度域泛化模型,利用不包含标签信息的目标域pd语音数据指导多源辅助域pd语音数据向其对齐的同时,极大化多源辅助域pd语音数据的类间的分布差异,进一步提升多源辅助域pd语音数据的共有内在不变特征提取效果。最后,利用多源辅助域pd语音数据的共有内在不变特征训练k最近邻(knn)模型并预测目标域pd语音数据对应标签。
2、本发明的目的是通过以下技术方案实现的:
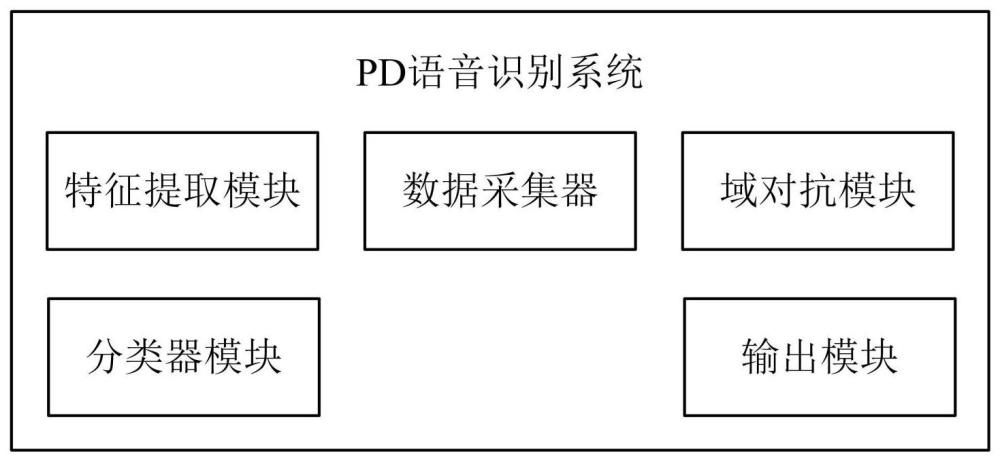
3、一种基于多源深度域泛化的帕金森病语音识别系统,包括:
4、数据采集器、特征提取模块、域对抗模块、分类器模块和输出模块,其中,
5、数据采集器,用于获取目标pd语音数据和多源辅助域pd语音数据,多源辅助域pd语音数据均包含代表帕金森病况的标签信息,目标pd语音数据中的pd语音数据均不包含代表帕金森病况的标签信息。
6、特征提取模块,用于利用深度学习网络提取多源辅助域pd语音数据中的内在不变特征,消除多源辅助域pd语音数据之间的分布差异;
7、域对抗模块,用于利用对抗思想设计神经网络,通过极大化多源辅助域pd语音数据的类间分布差异的同时,极小化目标域pd语音数据与多源辅助域pd语音数据间的域间分布差异,协助特征提取模块更好的提取多源辅助域pd语音数据与目标域pd语音数据中共有内在不变特征。
8、分类器模块,基于特征提取模块提取的多源辅助域pd语音的内在不变特征训练knn模型。
9、输出模块,用于输出分类器模块对目标域pd语音数据的标签预测结果。
10、可选地,对于多源辅助域pd语音数据中的内在不变特征的提取包括正向信号传递和反向误差传播两个过程。
11、可选地,对于协助多源辅助域pd语音数据中的内在不变特征提取的域对抗模块的正向信号传递和反向误差传播共有两条独立的路径。
12、可选地,对于度量多源辅助域与目标域之间的分布差异,在本系统中采用最大均值差异(mmd)。mmd的计算公式可表示为:
13、
14、其中xsi与xtj分别表示多源辅助域第i个样本与目标域第j个样本,n与m表示多源辅助域与目标域样本数量,θ(·)表示映射函数,ds与dt多源辅助域与目标域。
15、可选地,假设有n个源辅助域pd语音数据,数据矩阵分别表示为xs1~xsn,假设第i个源辅助域的第c类pd语音第j个样本数据可表示为假设目标域pd语音数据的数据矩阵表示为xt,则正向信号传播输出可分别表示为:
16、omax=f(wgmax(f(wfxs+bf))+bgmax)
17、omin=f(wgmin(f(wfxst+bf))+bgmin)
18、其中,xs表示输入的多源辅助域pd语音数据的数据矩阵([xs1,...,xsn]=xs,),xst表示输入的多源辅助域pd语音数据与目标域pd语音数据的数据矩阵([xs1,...,xsn,xt]=xst),wf与bf为特征提取模块的神经网络的权重与偏置,wgmax与bgmax为极大化多源辅助域pd语音数据的类间分布差异的神经网络的权重与偏置,omax为极大化多源辅助域pd语音数据的类间分布差异的正向信号传播输出,wgmin与bgmin为极小化多源辅助域pd语音数据与目标域pd语音数据的域间分布差异的神经网络的权重与偏置,omin为极小化多源辅助域pd语音数据与目标域pd语音数据的域间分布差异的正向信号传播输出,f(·)为神经网络的激活函数。
19、进一步地,所属的反向误差传播可分为两条路径,两条路径的损失函数可表示为:
20、
21、lmin=mmd(omins,omint)
22、l=lmax+lmin
23、其中,c表示多源辅助域pd语音数据的标签类别数,与分别表示omax中第i类与第j类多源辅助域pd语音数据对应输出,lmax为多源辅助域pd语音数据对应输出的类间分布差异损失,omins与omint分别表示omin中多源辅助域pd语音数据对应输出与目标域pd语音数据对应的输出,lmin为多源辅助域pd语音数据对应的输出与目标域pd语音数据对应的输出的域间分布差异损失,l为模型的总损失。
24、在反向误差传播过程中,通过链式法则计算每层的权重矩阵和偏置向量的梯度,并利用梯度下降法更新每层的权重矩阵和偏置向量。
25、为能同时实现lmax与lmin的反向传播,在域对抗模块中加入梯度反转层。
26、其中,需要注意的是,lmax的反向传播路径分为两个部分。在域对抗模块中,其通过链式法则计算每层的权重矩阵和偏置向量的梯度,并利用梯度下降法更新每层的权重矩阵和偏置向量;在特征提取模块中,lmax需加权后继续通过链式法则计算每层的权重矩阵和偏置向量的梯度,并利用梯度下降法更新每层的权重矩阵和偏置向量。当lmax开始更新特征提取模块时,lmax可表示为:
27、lmax=λlmax
28、
29、其中,λ为对lmax的因子,p为常数变量,表示为epoch_i表示当前训练的轮次,epoch_n表示预设的训练总轮次。
30、可选地,所述的knn模型基于样本间距离片段样本间的相似性,其距离计算可表示为:
31、
32、其中,pi与qi表示进行比较的两个样本的第i维特征,n表示样本特征数量。
33、可选地,对分类器模块进行训练的数据仅为从特征提取模块中获取的多源辅助域pd语音数据内在不变特征。
34、可选地,输出模块仅输出分类器模块对从特征提取模块中获取的目标域pd语音数据的内在不变特征数据的标签预测结果。
35、本发明的有益效果是:
36、本发明通过设计多源深度域泛化模型,借助深度学习强大学习能力消除多个源辅助域数据的分布差异的同时,基于对抗思想设计迁移准则,在进一步指导多源辅助域pd语音数据向目标域pd语音数据对齐的同时,增加多源辅助域pd语音数据的类间分布差异,提升多源辅助域pd语音数据与目标域pd语音数据共有的内在不变特征提取效果,进而提升分类器模型无监督学习效果,提升帕金森病的诊断精度。此外,由于本系统受无监督学习训练,系统对未知语种的pd语音识别具有较强的泛化能力。
37、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24536.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表