一种结合精准模型与轻量级模型的抑郁症识别方法及系统
- 国知局
- 2024-06-21 11:54:44
本发明涉及语音识别,尤其涉及一种结合精准模型与轻量级模型的抑郁症识别方法及系统。
背景技术:
1、抑郁症是一种常见的精神障碍,涉及长时间情绪低落或失去快乐或对活动的兴趣。根据世界卫生组织的不完全统计,全球约有3.5亿人患有不同程度的抑郁症。抑郁症的发病机制和病理学原理尚未明确,临床诊断只能根据患者的自我描述和相关信息进行主观诊断,缺乏客观的定量评价指标。此外,精神病理学评估通常需要丰富的专业知识支持,而且耗时长、评测项目繁多,不利于抑郁症的早期快速确诊。
2、近年来,使用生物材料样本进行抑郁症的客观评估引起许多研究者的关注,比如使用细胞因子或者唾液等,但生物材料样本的获取通常是侵入性的,并且对其进行分析检测的成本较高。与此同时,基于生理信号的抑郁症自动检测方法也进入人们的视野,生理信号主要包括心率、脑电、皮肤电、核磁、睡眠生理数据等信号,但上述生理信号的获取需要大量的人力物力、低精密度、技术门槛高、不易推广,并且生理状态和情感状态之间的相互作用仍有待在可穿戴设备的帮助下进行研究,数据获取具有挑战性,并且存在个人隐私泄露的风险。
3、由于抑郁症患者和非抑郁症患者之间的声学特征存在显著差异,一些研究开始聚焦于使用语音信号进行抑郁症检测,并证实了使用语音信号检测抑郁症的可行性。此外,录音设备的普及率高、录音成本低、语音信号的获取相对简单且无侵入性,进一步提高了使用语音信号检测抑郁症的可行性。随着深度学习方法的发展,一些研究开始尝试将其应用于抑郁症检测。诸如无监督编码,基于注意力机制的转换器(transformer),并行卷积神经网络(transformer and parallel convolutional neural networks,tcc),高效语音架构(speechformer++),双向门控循环单元(bidirectional gate recurrent unit,bi-gru),循环神经网络,图卷积神经网络等深度学习方法在语音抑郁症识别领域有广泛的应用。
4、目前,在使用语音数据进行抑郁症识别方面仍然存在数据规模不足、模型泛化性能有待提高等挑战。此外,对抑郁症的识别研究主要局限于单一语言的二分类任务,鲜有对抑郁症严重程度进行多分类研究以及跨语言的抑郁症识别检测。因此跨语言的语音抑郁症自动化早期快速筛查与精准诊断有重要的实际意义与广阔的应用前景。
技术实现思路
1、有鉴于此,本发明提供一种结合精准模型与轻量级模型的抑郁症识别方法及系统,不仅可快速筛查是否抑郁,还对抑郁程度进行精准识别,能够为抑郁症的早期检测提供一种有效辅助支持手段。
2、本发明的技术目的是这样实现的:
3、一方面,一种结合精准模型与轻量级模型的抑郁症识别方法,包括以下步骤:
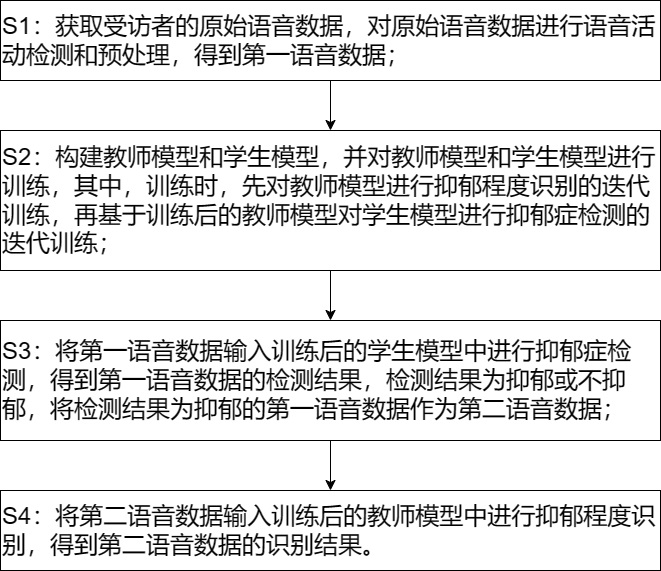
4、s1:获取受访者的原始语音数据,对原始语音数据进行语音活动检测和预处理,得到第一语音数据;
5、s2:构建教师模型和学生模型,并对教师模型和学生模型进行训练,其中,训练时,先对教师模型进行抑郁程度识别的迭代训练,再基于训练后的教师模型对学生模型进行抑郁症检测的迭代训练;
6、s3:将第一语音数据输入训练后的学生模型中进行抑郁症检测,得到第一语音数据的检测结果,检测结果为抑郁或无抑郁,将检测结果为抑郁的第一语音数据作为第二语音数据;
7、s4:将第二语音数据输入训练后的教师模型中进行抑郁程度识别,得到第二语音数据的识别结果。
8、在上述技术方案的基础上,优选的,步骤s1包括:
9、s11:获取受访者的原始语音数据,采用基于短时能量和短时平均过零率的动态双门限端点检测方法对原始语音数据进行语音活动检测,得到有效语音数据;
10、s12:将有效语音数据进行预处理,对有效语音数据的语音信号按照时序关系进行前后拼接,得到第一语音数据。
11、在上述技术方案的基础上,优选的,步骤s11包括:
12、计算原始语音数据中语音前导静默片段平均能量值和短时平均过零率,作为背景噪声平均能量值和背景噪声短时平均过零率,并获取原始语音数据的语音信号,计算语音信号的短时平均能量值;
13、设置第一阈值t1、第二阈值t2和第三阈值t3,其中,t1=背景噪声平均能量值,t2=短时平均能量值,t3=背景噪声短时平均过零率;
14、在语音信号中针对每个短时时间段内的能量值进行计算,并将能量值连接形成一条曲线,作为短时能量包络线,其中,短时能量包络线用于表示语音信号在时间上的能量变化;
15、将t2与短时能量包络线进行比对,在短时能量包络线中查询与t2重合的点,作为第一交点;
16、将t2与短时能量包络线进行粗判,将短时能量包络线中高于t2的曲线部分判定为有效能量包络线,其中,第一交点位于有效能量包络线上;
17、将t1与有效能量包络线重合的点作为第二交点,在有效能量包络线上从第一交点开始沿曲线路径进行搜索,将搜索到的第二交点作为候选点,根据语音信号的能量值波动趋势在候选点中选取两个第二交点,作为第一起止点对,包括第一起点和第一止点,将第一起点和第一止点之间的曲线作为第一曲线段;
18、在有效能量包络线上从第一起止点对开始分别沿曲线路径的远离第一曲线段的两个方向进行搜索,寻找有效能量包络线上能量值低于t3的点:
19、从第一起点开始沿曲线路径的远离第一曲线段的方向进行搜索,当搜索到首个能量值低于t3的点,即停止该方向的搜索,将该点作为第二起点;
20、从第一止点开始沿曲线路径的远离第一曲线段的方向进行搜索,当搜索到首个能量值低于t3的点,将该点作为第二候选止点,计算第二候选止点的静音区域长度,判断静音区域长度是否满足最小长度,若满足,则将第二候选止点作为第二止点,并结束搜索;若不满足,则继续搜索下一个能量值低于t3的点,直至静音区域长度满足最小长度,得到第二止点;
21、将第二起点和第二止点之间的语音数据作为有效语音数据。
22、在上述技术方案的基础上,优选的,步骤s2中,教师模型包括第一多尺度特征编码器、第一特征融合模块、上下文网络、量化模块和bi-lstm网络;学生模型包括第二多尺度特征编码器、第二特征融合模块和lstm网络;
23、其中,第一多尺度特征编码器由三个不同尺度的第一特征编码器构成,每个第一特征编码器包括7层一维卷积层,第一层一维卷积层采用组归一化计算输出,其余层一维卷积层采用层归一化计算输出;
24、第二多尺度特征编码器由三个不同尺度的第二特征编码器构成,每个第二特征编码器包括4层一维卷积层。
25、在上述技术方案的基础上,优选的,教师模型的训练过程为:
26、获取语音训练数据x,x包含真实分类,其中,语音训练数据为跨语言数据集;
27、将语音训练数据x输入第一多尺度特征编码器,经三个第一特征编码器处理后得到三个特征向量序列z1、z2和z3,并对三个特征向量序列做池化处理;
28、将三个特征向量序列z1、z2和z3输入第一特征融合模块,第一特征融合模块包括特征向量拼接层和两层全连接层,利用特征项链拼接层进行特征拼接,并连接到两层全连接层进行特征选择,得到特征向量z;
29、将特征向量z输入量化模块进行离散化,形成有限的语音表示q;
30、将特征向量z同步输入上下文网络中,经编码为上下文表示c,其中,上下文网络包含12个transformer 模块;
31、将有限的语音表示q和上下文表示c输入bi-lstm网络,bi-lstm网络包括随机失活层和分类层,经分类层输出预测分类,预测分类为四分类,分别为无抑郁、轻度抑郁、中度抑郁以及重度抑郁;
32、根据预测分类和真实分类计算损失函数的值,根据损失函数的值反向传播梯度,调整教师模型的参数,直至损失函数收敛,得到训练后的教师模型。
33、在上述技术方案的基础上,优选的,在训练教师模型时,冻结教师模型中量化模块和上下文网络的参数,调整第一多尺度特征编码器、第一特征融合模块和bi-lstm网络的参数。
34、在上述技术方案的基础上,优选的,学生模型的训练过程为:
35、将语音训练数据x的真实分类调整为二分类形式的真实标签,作为硬标签;
36、设置教师模型的四分类输出与学生模型的二分类输出之间的映射关系,根据映射关系将教师模型的四分类输出映射为二分类,得到软标签;
37、将语音训练数据x输入学生模型,计算学生模型的预测输出与软标签的差异,作为蒸馏损失;同时计算学生模型的预测输出与硬标签之间的交叉熵损失,作为分类损失;
38、将蒸馏损失和分类损失进行加权求和得到学生模型的总损失;
39、迭代训练学生模型,直至学生模型的总损失收敛,得到训练后的学生模型。
40、在上述技术方案的基础上,优选的,映射关系为:
41、;
42、其中,s(0)、s(1)、s(2)、s(3)分别表示教师模型的无抑郁、轻度抑郁、中度抑郁及重度抑郁四分类输出;p(0)和p(1)分别表示无抑郁、抑郁的软标签。
43、在上述技术方案的基础上,优选的,蒸馏损失的计算公式为:
44、;
45、式中,l1为蒸馏损失;i表示第i个语音训练数据,p(i)表示i的软标签;q(i)表示学生模型的预测输出;
46、分类损失的计算公式为:
47、;
48、式中,l2为分类损失,y(i)表示i的硬标签,硬标签为无抑郁则y(i)的值为0,硬标签为抑郁则y(i)的值为1;q(i)表示学生模型的预测输出;
49、学生模型的总损失为:
50、;
51、式中,loss表示学生模型的总损失,λ为大于0.5的权重。
52、另一方面,本发明还提供一种结合精准模型与轻量级模型的抑郁症识别系统,所述系统用于执行上述任一项所述的方法,所述系统包括:
53、语音信号采集端,其包括录音设备,用于采集并保存语音信号,并将语音信号上传至云服务器;
54、云服务器,部署有数据分析模块、训练后的教师模型和训练后的学生模型,数据分析模块设置有语音活动检测算法,云服务器用于将采集到的语音信号进行语音活动检测和预处理,调用训练后的学生模型进行抑郁症检测,并在判定为抑郁后调用训练后的教师模型进行抑郁程度的识别;
55、显示模块,用于显示抑郁症检测结果和抑郁程度识别结果;
56、预警模块,用于提醒用户,并基于抑郁症检测结果和抑郁程度识别结果提供缓解建议。
57、本发明的方法相对于现有技术具有以下有益效果:
58、(1)本发明通过模型蒸馏的方式,不仅能快速筛查是否抑郁,还能实现对抑郁程度的精准识别,对于抑郁症的早期检测和干预治疗具有积极的影响;
59、(2)本发明采用动态双门限端点检测方法和前后拼接技术对语音数据进行处理,能够提取有效的语音特征,有助于提高抑郁症识别的准确性;
60、(3)本发明设计一种抑郁症检测系统,利用录音工具录制语音信号,通过小程序或网页将数据上传至云服务器,数据经过动态阈值语音活动检测预处理后,由两个跨语言的语音抑郁症识别模型对抑郁症进行快速筛查与精准检测,并在抑郁状态下给予用户放松和缓解压力的建议。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24425.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。