基于语义加强识别的调度语音交互方法、装置及机器人
- 国知局
- 2024-06-21 11:55:49
本技术涉及机器人,具体地涉及一种基于语义加强识别的调度语音交互方法、装置及机器人。
背景技术:
1、目前,调度大厅作为电网运营中的一个重要部门,承担了对电网运行情况进行监控、调度和管理的职责。为了使现场客人(如运行人员、维护人员等)能够更好地理解电网的运行情况和相关信息,需要安排专门人员对已有电网内部平台的数据和知识进行讲解,已有电网内部平台的数据和知识包括电网的拓扑结构、设备状态、电力负荷、运行参数等。通过人工讲解,现场客人可以了解电网的实时运行情况,掌握重要的运行指标和数据,以便做出相应的决策和调度。
2、但是,现场客人可能会有一些问题和疑惑,需要对其进行解答,这些问题可能涉及电网运行的细节、异常情况的处理、设备故障的排除等,专门人员仅凭自身经验可能不足以完全解答现场客人的疑问或者会出现解答错误的情况,若出现专门人员无法凭借自身经验解答或者解答错误的情况,会导致讲解效率以及准确性偏低,因此,亟需一种机器人讲解方式,以提高讲解的效率和准确性。
技术实现思路
1、本技术实施例的目的是提供一种基于语义加强识别的调度语音交互方法、装置及机器人,用以解决现有技术中讲解效率以及准确性偏低的问题。
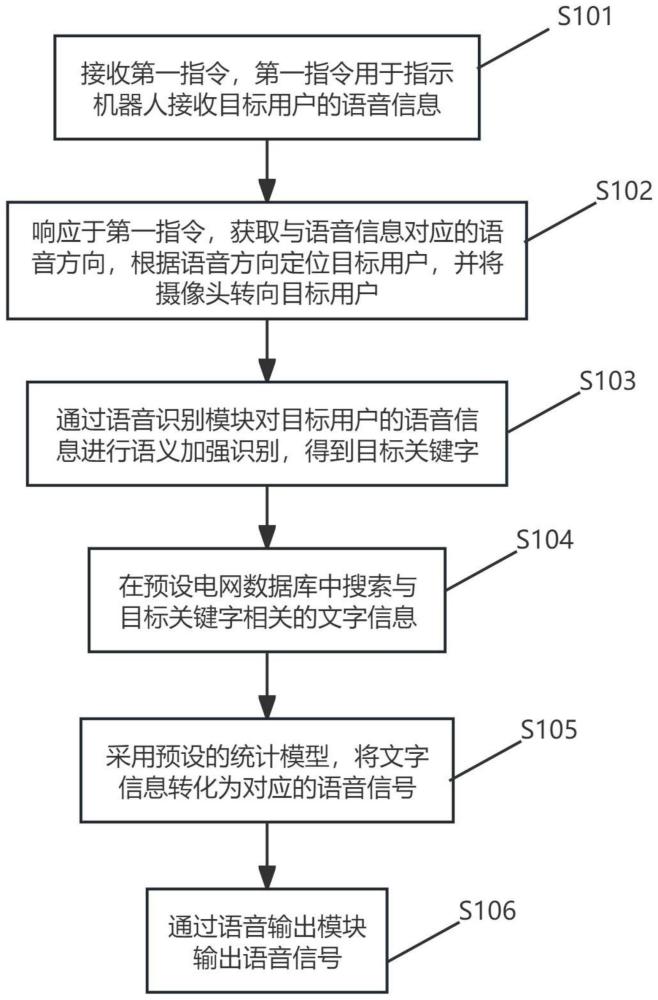
2、为了实现上述目的,本技术第一方面提供一种基于语义加强识别的调度语音交互方法,应用于机器人,所述机器人包括语音识别模块、语音输出模块和摄像头,该方法包括:
3、接收第一指令,所述第一指令用于指示所述机器人接收目标用户的语音信息;
4、响应于所述第一指令,获取与所述语音信息对应的语音方向,根据所述语音方向定位目标用户,并将所述摄像头转向所述目标用户;
5、通过所述语音识别模块对所述目标用户的所述语音信息进行语义加强识别,得到目标关键字;
6、在预设电网数据库中搜索与所述目标关键字相关的文字信息;
7、采用预设的统计模型,将所述文字信息转化为对应的语音信号;
8、通过所述语音输出模块输出所述语音信号。
9、在本技术实施例中,所述机器人还包括麦克风阵列,所述麦克风阵列包括多个麦克风,所述获取与所述语音信息对应的语音方向,根据所述语音方向定位目标用户,包括:
10、获取所述麦克风阵列中每个麦克风采集的用户的声音信号;
11、根据每个麦克风采集的用户的声音信号,确定每个声音信号相对所述麦克风阵列的语音方向,并根据预设的方向区间分类逻辑将所有所述声音信号的语音方向划分至对应的方向区间,其中,每个所述方向区间均对应一个或多个声音信号;
12、在多个所述方向区间中,确定与所述语音信息对应的声音信号的目标方向区间;
13、通过所述摄像头采集所述目标方向区间的目标图像;
14、采用图像识别算法,根据所述目标图像确定用户数量;
15、在所述目标方向区间对应多个声音信号的情况下,获取所述目标方向区间中的每个用户的语音片段和每个所述声音信号的声音强度;
16、对所述目标方向区间中的每个所述用户的语音片段进行特征提取,得到每个用户的语音特征;
17、对所述目标图像进行图像识别,得到所述目标用户说话时刻的所述目标方向区间的每个用户的用户特征;
18、根据所述声音强度、每个用户的所述语音特征以及每个用户的所述用户特征,确定所述目标用户。
19、在本技术实施例中,所述麦克风阵列中的麦克风之间的距离相等,所述根据每个麦克风采集的用户的声音信号,确定每个声音信号相对所述麦克风阵列的语音方向,并根据预设的方向区间分类逻辑将所有所述声音信号的语音方向划分至对应的方向区间,包括:
20、对于所述麦克风阵列采集到的任意一个声音信号,循环执行第一步骤,至得到所述麦克风阵列采集到的所有声音信号相对所述麦克风阵列的语音方向;
21、采用预设的方向区间分类逻辑,将得到的所有语音方向划分至对应的方向区间;
22、其中,所述第一步骤包括:
23、将所述麦克风阵列采集到的任意一个声音信号作为目标声音信号,采用声源定位算法,确定所述目标声音信号与所述麦克风阵列中每个所述麦克风的角度;
24、对于每个所述麦克风,将采集到的所述目标声音信号与其他麦克风采集到的目标声音信号进行延迟对齐;
25、根据所述目标声音信号与每个所述麦克风的角度,确定每个所述麦克风的权重;
26、将延迟对齐后的每个麦克风采集的声音信号与对应的权重相乘,得到多个加权后的声音信号;
27、将多个加权后的声音信号相加,得到波束信号;
28、根据所述波束信号,确定所述目标声音信号相对所述麦克风阵列的语音方向。
29、在本技术实施例中,所述用户特征包括面部特征和姿态特征,所述根据所述声音强度、每个用户的所述语音特征以及每个用户的所述用户特征,确定目标用户,包括:
30、将声音强度最大的声音信号对应的用户作为待测用户,对所述目标用户的语音信息进行特征提取,得到所述目标用户的第一语音特征;
31、计算所述第一语音特征与所述待测用户的语音特征的第一相似性;
32、在所述第一相似性大于或等于预设第一相似性阈值的情况下,将所述第一语音特征输入预训练的姿态特征模型,得到第一姿态特征与第一面部特征;
33、计算所述第一姿态特征与所述待测用户的姿态特征的第二相似性,以及计算所述第一面部特征与所述待测用户的面部特征的第三相似性;
34、在所述第二相似性大于预设第二相似性阈值且所述第三相似性大于预设第三相似性阈值的情况下,确定所述待测用户为所述目标用户。
35、在本技术实施例中,所述语音特征包括声调特征、频率特征和声音的持续时间,在所述根据所述声音强度、每个用户的所述语音特征以及每个用户的所述用户特征,确定所述目标用户之后,包括:
36、将所述目标用户的声调特征、频率特征和声音的持续时间输入至预训练的情感识别模型,得到所述目标用户的情感状态;
37、根据所述目标用户的情感状态,根据预设的回应策略生成回应信息,并通过所述语音输出模块输出所述回应信息。
38、在本技术实施例中,在所述通过所述语音输出模块输出所述语音信号之后,包括:
39、接收所述目标用户发出的第二指令,所述第二指令用于指示所述机器人与第二用户进行交互;
40、通过所述摄像头获取所述目标用户的图像信息,并在所述图像信息中识别所述目标用户的手部图像;
41、对所述手部图像进行图像识别,得到所述目标用户的手势特征;
42、根据所述手势特征,获取所述机器人与所述第二用户的相对位置;
43、将所述手势特征与所述机器人与所述第二用户的相对位置输入至预训练的神经网络模型中,得到所述神经网络模型输出的预测动作;
44、执行所述预测动作,以使所述机器人跟随所述第二用户移动。
45、在本技术实施例中,所述神经网络模型的训练方法包括:
46、将所述机器人与所述第二用户的相对位置和所述第二用户的手势动作作为状态,并获取初始状态,其中,所述相对位置包括离开、靠近与跟随,所述手势动作包括向左和向右;
47、定义奖励函数以及所述机器人的动作,根据所述机器人与所述第二用户的相对位置和所述手势动作,设置奖励值,所述机器人的动作包括前进、后退、左转和右转;
48、根据获取的历史数据,计算所述机器人的状态转移概率ε,所述状态转移概率ε用于表示机器人在不同状态下执行不同动作的概率,所述历史数据包括所述机器人执行的动作与对应的发生变化的状态;
49、初始化神经网络模型以及回报表,并定义初始q值,其中,所述回报表用于存储每个所述状态与对应的所述机器人的动作对应的q值,所述q值表示在特定状态下执行特定动作的预期回报;
50、循环执行神经网络模型训练步骤,至训练的次数达到预设次数阈值,得到训练后的神经网络模型;
51、其中,所述神经网络训练步骤包括:
52、以ε的概率随机选择一个所述机器人的动作,以1-ε的概率选择具有最高q值的动作;
53、执行选择的动作,并获取新状态和新奖励值;
54、根据当前状态、所述选择的动作、所述新状态和所述新奖励值,计算新q值,并将所述新q值更新到所述回报表中,其中,所述当前状态用于表示当前的状态;
55、使用所述初始q值作为目标值,将所述初始状态作为输入,通过反向传播算法更新神经网络模型的参数,以使神经网络模型学习状态转移概率的估计;
56、所述奖励函数包括:
57、r(s,a,s’)=-1+α×δd+β×δg;
58、式中,r(s,a,s’)是在状态s下执行动作a后转移到状态s’的奖励值,δd表示所述机器人与所述第二用户的距离的变化,δg表示所述机器人与所述第二用户的相对位置的变化,α和β均为预设参数。
59、在本技术实施例中,所述根据获取的历史数据,计算所述机器人的状态转移概率ε,包括:
60、根据所述历史数据,得到每个状态下执行任意一个动作的次数;
61、根据任意一个状态的总数量与所述状态下执行任意一个动作的次数,计算得到状态转移概率ε,其中,n为任意一个状态执行任意一个动作的次数,z为任意一个状态的总数量。
62、本技术第二方面提供一种基于语义加强识别的调度语音交互装置,其特征在于,包括:
63、存储器,被配置成存储指令;以及
64、处理器,被配置成从所述存储器调用所述指令以及在执行所述指令时能够实现上述的基于语义加强识别的调度语音交互方法。
65、本技术第三方面提供一种机器人,包括:
66、上述基于语义加强识别的调度语音交互装置;
67、语音识别模块,用于对目标用户的语音信息进行语义加强识别;
68、语音输出模块,用于输出语音信号,其中,所述语音信号是根据所述目标用户的语音信息检索到的文字信息转化得到;
69、摄像头,用于拍摄图像;
70、麦克风阵列,所述麦克风阵列包括多个麦克风,用于采集声音信号。
71、通过上述技术方案,通过接收目标用户的语音信息,并根据语音方向定位目标用户,机器人可以快速准确地与用户进行交互,除此之外,通过语音识别模块和语义加强识别,机器人可以根据用户的语音信息和目标关键字,搜索预设电网数据库中与关键字相关的文字信息,并采用预设的统计模型将文字信息转化为语音信号,从而使得机器人可以根据用户的需求提供电网运行情况讲解和解答,相比于人工讲解,可以提高讲解的效率,节省人力资源,同时有利于减少人为误差,提高讲解的准确性。
72、本技术实施例的其它特征和优点将在随后的具体实施方式部分予以详细说明。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24537.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表