基于视觉场景的多模态语音识别方法、电子设备、介质与流程
- 国知局
- 2024-06-21 11:57:51
本发明属于语音识别,尤其涉及一种基于视觉场景的多模态语音识别方法、电子设备、介质。
背景技术:
1、语音是人类社会中重要的信息载体,语音识别技术作为一项重要的人机交互手段,在通讯、车载、工业等领域具有广泛的应用价值。近年来,人工智能算法的迅速发展,基于深度神经网络的语音识别方法极大地提升了语音识别的正确率。主流的语音识别技术主要采用单模态信息(即音频)进行语音识别。spille等人的研究(spille c,ewert sd,kollmeier b,meyer b t.predicting speech intelligibility with deep neuralnetworks.computer speech&language,2018,48:51-66)指出,主流的单模态语音识别技术在简单、安静场景下的性能已接近人类,但是在复杂、噪声场景下的性能仍严重不足;相比之下,人类在复杂场景中能够保持稳定、高效的语音识别。因此,借鉴人脑的听觉语音处理机制逐渐成为解决当前语音模型性能不足的重要途径之一。在复杂噪声环境中,人脑常利用视觉信息作为语音加工的补充线索。具体而言,说话人的面部动作(如表情、唇动)与语音的声学波动相互关联,能够促进人脑对语音的感知与识别。受到脑科学研究的启发,语音识别领域提出了多模态语音识别技术,即采用多模态信息(即音频与视频)进行语音识别。xu等人的研究(xu b,lu c,guo y,wang j.discriminative multi-modality speechrecognition.proceedings of the ieee/cvf conference on computer vision andpattern recognition.2020:14433-14442)发现,利用目标说话人的视频信息能够有效地提升语音识别模型在嘈杂环境下的语音识别性能。
2、当前的多模态语音识别技术主要利用目标说话人的视频信息(例如,面部动作和唇形)来提升语音识别的性能。尽管已经具备较高的鲁棒性与准确性,当前的多模态语音识别技术在真实世界的嘈杂场景中也显示出明显的性能下降。afouras等人的研究(afourast,chung js,senior a,et al.deep audio-visual speech recognition.ieeetransactions on pattern analysis and machine intelligence,2018,44(12):8717-8727)指出,音频中的噪声水平可以直接影响由面部动作或者唇形等视频输入所带来的语音识别性能的改善。除此之外,由于当前的多模态语音识别技术需要目标说话人的视频作为视觉信息输入。在自然听觉环境中,实时获取目标说话人面部动作或唇形的视频数据存在一定难度,视频的有效性容易受到视频清晰度、拍摄角度以及遮挡物等因素的影响。因此,当前的多模态语音识别技术在使用场景上也存在一定的限制。
3、综上所述,现有技术中语音识别方法存在以下问题:
4、1、传统的单模态语音识别技术在复杂噪声环境中存在性能缺陷。尽管在简单安静环境下,单模态语音识别系统能够实现较高的语音识别准确率,但是在复杂噪声环境下,语音识别的准确率会大幅降低。因此,单模态语音识别技术往往只适于低噪声的语音环境,使得其在实际应用场合中的通用性大打折扣。
5、2、目前多模态语音识别技术需要获取目标说话人清晰、干净的面部动作或唇形视频作为辅助的视觉输入来提升语音识别系统在复杂噪声环境中的性能。一方面,在自然听觉环境中实时获取目标说话人的面部动作或唇形视频存在一定的难度。另一方面,即便通过目标说话人的视觉输入能够提升语音识别的准确率,其性能仍易受到自然环境中复杂噪声的影响。因此,多模态语音识别技术在实际应用场景中也存在一定的局限性。
技术实现思路
1、本发明针对现有技术不足,提供了一种基于视觉场景的多模态语音识别方法、系统、设备、介质。
2、本发明实施例的第一方面,提供了一种基于视觉场景的多模态语音识别方法,所述方法包括:
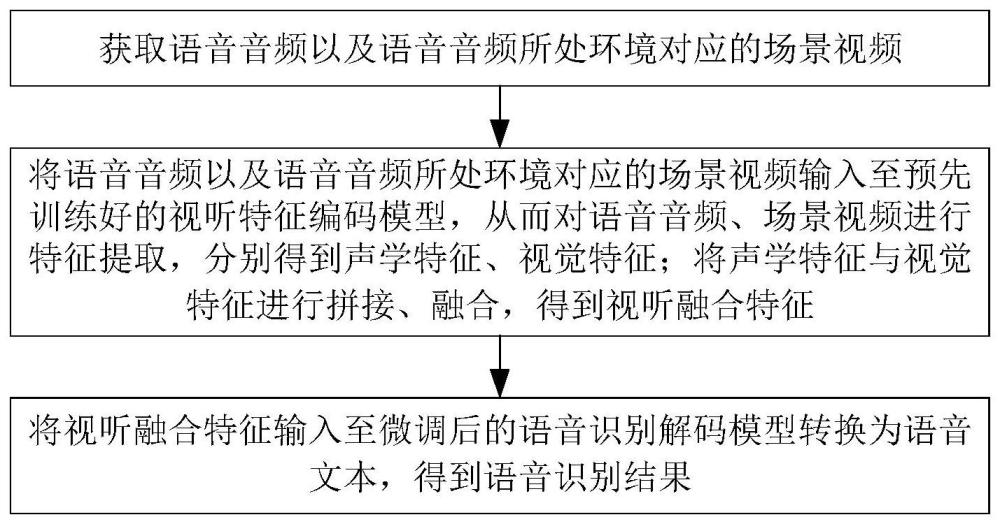
3、获取语音音频以及语音音频所处环境对应的场景视频;
4、将语音音频以及语音音频所处环境对应的场景视频输入至预先训练好的视听特征编码模型,从而对语音音频、场景视频进行特征提取,分别得到声学特征、视觉特征;将声学特征与视觉特征进行拼接与融合,得到视听融合特征;
5、其中,视听特征编码模型的训练过程包括:获取初始声学特征、初始视觉特征,拼接得到初始视听融合特征;对每段时间窗口内的初始视听融合特征进行聚类,得到聚类标签;随机选择部分时间窗口的初始视听融合特征进行掩蔽;利用未掩蔽时间窗口的视听融合特征向量对掩蔽时间窗口的聚类标签进行预测,从而对视听特征编码模型进行训练;
6、将视听融合特征输入至微调后的语音识别解码模型转换为语音文本,得到语音识别结果。
7、本发明实施例的第二方面,提供了一种电子设备,包括存储器和处理器,所述存储器与所述处理器耦接;其中,所述存储器用于存储程序数据,所述处理器用于执行所述程序数据以实现上述的基于视觉场景的多模态语音识别方法。
8、本发明实施例的第三方面,提供了一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现上述的基于视觉场景的多模态语音识别方法。
9、本发明实施例的第四方面,提供了一种计算机程序产品,包括计算机程序/指令,该计算机程序/指令被处理器执行时实现上述的基于视觉场景的多模态语音识别方法。
10、与现有技术相比,本发明的有益效果为:
11、(1)本发明获取语音音频以及语音音频所处环境对应的场景视频,基于语音音频所在环境的视觉场景信息通过神经网络获取与环境噪声相关的声学线索,从而有效增强语音识别系统对环境噪声的抑制能力,提升语音识别的稳定性与准确率。
12、(2)在视听特征编码模型的训练过程,本发明对每段时间窗口内的初始视听融合特征进行聚类,得到聚类标签,通过数据驱动的方式对场景的视听融合特征进行聚类,使得模型在视听特征编码的过程中学习不同听觉场景下视听融合特征的聚类标签,实现模型对不同场景(不同噪声源的类型、属性、位置、运动等)的模式识别,从而提升模型在不同噪声环境下的语音识别性能。
13、(3)不同于现有技术,本发明无需获取与说话人相关的视觉信息,例如面部动作、唇形等。因此,视频采集设备可放置于说话人所处环境的任意位置,或者直接由说话人进行佩戴,从而采集语音音频所处环境对应的场景视频,具备更高的自由度与更广泛的应用场景。
技术特征:1.一种基于视觉场景的多模态语音识别方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于视觉场景的多模态语音识别方法,其特征在于,得到视听融合特征的过程包括:
3.根据权利要求1所述的基于视觉场景的多模态语音识别方法,其特征在于,随机选择部分时间窗口的初始视听融合特征进行掩蔽包括:
4.根据权利要求3所述的基于视觉场景的多模态语音识别方法,其特征在于,利用未掩蔽时间窗口的视听融合特征向量对掩蔽时间窗口的聚类标签进行预测,从而对视听特征编码模型进行训练包括:
5.根据权利要求4所述的基于视觉场景的多模态语音识别方法,其特征在于,掩蔽时间窗口的损失函数的表达式如下:
6.根据权利要求1所述的基于视觉场景的多模态语音识别方法,其特征在于,对语音识别解码模型进行微调的过程包括:
7.根据权利要求1所述的基于视觉场景的多模态语音识别方法,其特征在于,通过文本转化任务构建的损失函数的表达式如下:
8.一种电子设备,包括存储器和处理器,其特征在于,所述存储器与所述处理器耦接;其中,所述存储器用于存储程序数据,所述处理器用于执行所述程序数据以实现上述权利要求1-7任一项所述的基于视觉场景的多模态语音识别方法。
9.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述程序被处理器执行时实现如权利要求1-7中任一所述的基于视觉场景的多模态语音识别方法。
10.一种计算机程序产品,包括计算机程序/指令,其特征在于,该计算机程序/指令被处理器执行时实现权利要求1-7中任一所述的基于视觉场景的多模态语音识别方法。
技术总结本发明公开了一种基于视觉场景的多模态语音识别方法、电子设备、介质,包括:获取语音音频以及语音音频所处环境对应的场景视频;将其输入至预先训练好的视听特征编码模型进行特征提取,分别得到声学特征、视觉特征,经拼接与融合,得到视听融合特征;其中,视听特征编码模型的训练过程包括:获取初始声学特征、初始视觉特征,经拼接、融合后得到视听融合特征;对每段时间窗口内的视听融合特征进行聚类,得到聚类标签;随机选择部分时间窗口的视听融合特征进行掩蔽;利用未掩蔽时间窗口的视听融合特征对掩蔽时间窗口的聚类标签进行预测,完成训练过程;将视听融合特征输入至微调后的语音识别解码模型转换为语音文本,得到语音识别结果。技术研发人员:罗城,孙周健,孙文慧,王瑶瑶,章佳颖受保护的技术使用者:之江实验室技术研发日:技术公布日:2024/6/11本文地址:https://www.jishuxx.com/zhuanli/20240618/24755.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。