基于上下文相关频谱系数动态分割的声纹特征提取算法
- 国知局
- 2024-06-21 11:57:44
本发明属于声纹特征提取算法和模式识别,采用无监督的层次聚类进行声纹频谱系数的特征分析,特别涉及一种基于上下文相关的动态分割方法,实现从频谱系数到声纹特征的提取算法。
背景技术:
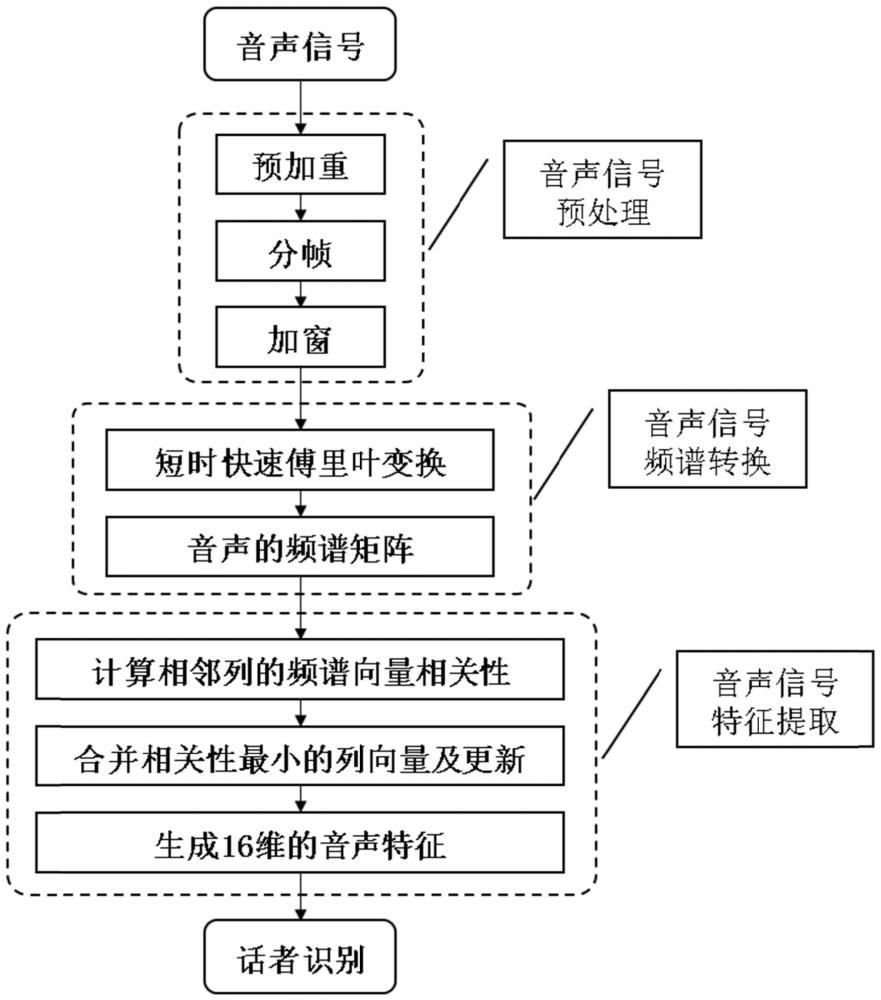
1、说话人识别技术包括声纹特征提取和声纹模式识别两部分。特征提取是说话人识别技术中的关键步骤,将直接影响到语音识别系统的整体性能。通常情况,一组语音信号经过预加重、分帧和加窗的预处理和基于傅里叶变换的频谱转换后,会产生大量高维度的频谱数据,需要通过去除原来语音中的冗余信息降低数据维度,进而得到有效的音声特征。现有方法中,一般会使用梅尔尺度变换和三角形滤波器组对高维的频谱数据进行处理,将语音信号转换为满足识别要求的声纹特征向量,并能够符合近似人耳听觉感知特性以及在一定程度上能够增强语音信号和抑制非语音信号。常用的声纹特征有梅尔频率倒谱系数,(mel-frequency cepstrum coefficient,mfcc)。mfcc作为最广泛的声纹特征,提取过程同样包含语音的预加重、分帧、加窗、傅里叶变换等处理,然后将所得高维能量谱通过一组梅尔尺度的三角形滤波器组进行滤波,通过计算每个滤波器组的输出得到mfcc特征。由于mfcc特征采用了等间隔的梅尔频率以及相同三角滤波器组,所以无法体现出高维频谱数据间的上下文相关性。
技术实现思路
1、本发明的目的主要是针对基于等频域分割频谱系数,提出一种基于上下文相关频谱系数动态分割的声纹特征提取算法,提高语音识别的准确率。
2、为了实现上述目的,本发明采用的技术手段如下:
3、基于上下文相关频谱系数动态分割的声纹特征提取算法,包括如下步骤:
4、s1、读取一组语音信号,对其分别进行预处理、频谱转换、上下文特征提取;
5、s11、对字节长为n的语音信号{x[1],x[2],...,x[i],...,x[n]}进行预处理;
6、s111、对语音信号x[i]进行预加重,其中α为预加重系数,取α=0.9,则得预加重后的语音信号x[i]如下:
7、x[i]=x[i]-α×x[i-1]
8、s112、对语音信号{x[1],x[2],...,x[i],...,x[n]}进行分帧,得到分帧后的语音信号{f[1],f[2],...,f[j],...,f[m]},f[j]为一帧包含256字节的语音信号,简称分帧信号,取帧移为128字节,求得总分帧数为m=int(n/128),每帧分帧信号的分帧索引与原语音信号的字节索引对应关系为i=(j-1)×128,则每帧分帧信号表达如下:
9、f[j]={x[i],x[i+1],...,x[i+255]}
10、s113、对分帧信号进行加窗处理,窗函数为:
11、
12、对每帧分帧信号操作如下:
13、f[j]=w(j)×f[j]
14、s12、对预处理后的每帧分帧信号f[j]进行从时域变换到频域的频谱转换;
15、s121、对分帧信号f[j],进行短时的快速傅里叶变换,f[j]中每一个语音信号x[i]通过以下计算得到频谱向量vi,j:
16、
17、s122、对每帧分帧信号重复s121操作,得到语音信号的频谱矩阵a如下:
18、
19、s13、提取基于上下文相关的声纹特征
20、s131、对频谱矩阵a中,依次计算每相邻两列频谱的线性相关性,得到相关性指标表示为:
21、(l[1],l[2],...,l[i],...,l[n-1]}
22、式中,l[i]由下式求得:
23、
24、其中,l[i]表示第i列向量与第i+1列向量的相关性,和分别表示第i列向量和第i+1列向量的平均值;
25、s132、对各相关性指标进行比较,求得最大l[i]值对应频谱矩阵a中的v[i]和v[i+1]两列进行合并,得到新的频谱列向量v[i],并更新其频谱元素如下:
26、
27、s133、计算新的频谱列向量v[i]与v[i-1]和v[i+2]的相关性,更新相关性指标l[i-1]和l[i],并从i+1到n-1依次更新频谱列向量和相关性指标:
28、v[i+1]=v[i+2],l[i+1]=l[i+2],2≤i≤n-2
29、更新结束后,令n=n-1;
30、s134、对频谱矩阵a重复步骤s131至s133的操作,直至n=16停止,得到一组维度为16的声纹特征向量;
31、s2、基于该声纹特征向量建立话者识别模型,输入说话人语音进行识别;
32、s21、对不同说话人的语音都重复上述s1的操作,得到代表其声纹特征的声纹特征向量;
33、s22、将所得声纹特征向量分为训练数据和测试数据;
34、s23、使用训练数据建立话者识别模型;
35、s24、使用测试数据验证话者识别模型。
36、本发明与现有技术相比,具有以下优点:
37、第一,本发明在现有等频域分割的声纹特征基础上,考虑了分帧后频谱数据的上下文相关性,提出了基于上下文相关的特征提取算法。利用s13步骤完善了处理后信号本身所具有的上下文相关性特征。
38、第二,本发明采用了动态分割方法,在考虑上下文相关性的同时,加强了向量间的特征相似性比较,使本发明具有更广泛的适应性,且在说话人识别上可以获得更高的识别精度。
39、第三,本发明采用线性相关性作为评价指标,使得本发明具有流程简明,速度快捷,占用计算资源少的优点。
技术特征:1.基于上下文相关频谱系数动态分割的声纹特征提取算法,其特征在于:包括如下步骤:
2.根据权利要求1所述基于上下文相关频谱系数动态分割的声纹特征提取算法,其特征在于:步骤s111中的预加重系数α=0.9。
技术总结本发明公开了一种基于上下文相关频谱系数动态分割的声纹特征提取算法,包括如下步骤:对读取的语音信号分别进行预处理、频谱转换、上下文特征提取;基于声纹特征向量建立话者识别模型,输入说话人语音进行识别。本发明在现有等频域分割的声纹特征基础上,考虑了分帧后频谱数据的上下文相关性,提出了基于上下文相关的特征提取算法。利用S13步骤完善了处理后信号本身所具有的上下文相关性特征。本发明采用了动态分割方法,在考虑上下文相关性的同时,加强了向量间的特征相似性比较,使本发明具有更广泛的适应性,且在说话人识别上可以获得更高的识别精度。本发明采用线性相关性作为评价指标,具有流程简明,速度快捷,占用计算资源少的优点。技术研发人员:左毅,刘君霞,贺培超,李铁山,陈俊龙受保护的技术使用者:大连海事大学技术研发日:技术公布日:2024/6/11本文地址:https://www.jishuxx.com/zhuanli/20240618/24744.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表