融合规则与语言模型的端到端文本正则化方法
- 国知局
- 2024-06-21 11:58:34
本发明涉及融合规则与语言模型的端到端文本正则化方法,属于自然语言处理。
背景技术:
1、文本正则化(text normalization,tn)是语音合成(text-to-speech,tts)的前端任务中至关重要的一步。此任务是将书面文本形式的非标准词(nsw,non-standard words)转换为口头形式的可读词(sfw,spokenform words),如将“3.14”转换成“三点一四”和“2023/10/15”转换成“二零二三年十月十五日”。目前,相关技术在语音导航、智能家居、机器人问答和通讯设备等多个领域有着广泛的应用,如baidu dueros、tencent xiaowei、alibaba tmall genie和xiaomi xiao ai等。研究文本正则化任务有助于生成更准确的语音输出,提高语音合成系统的自然度和质量。但该任务目前面临着几个挑战,一是该任务存在大量不需要转换的固定词,使用神经网络模型容易出现将这些固定词预测错误的情况,导致不可恢复性的错误;二是文本中存在大量的非标准词,nsw具有不同的形式,包括数字、数字序列、缩写、分数、数字范围、电子邮件地址、游戏得分、url等。准确识别这些nsw是一项具有挑战性的任务。如将“3/4”转换为“四分之三”或“四月三日”,“2023”转换为“二零二三”或“两千零二十三”。在中文中这种歧义性可能更大,如‘/’就有‘年’、‘月’、‘每’、‘或’、‘及’、‘分数’等多种含义,因此,上下文对于识别这些nsw至关重要。以“2023光年”为例,只有当“光年”一词被正确识别时,“2023”才会被读作数字;否则,如果关键字“年”匹配不准确,则“2023光年”可能被读作年份。
2、目前,tn任务常用基于nsw的传统分类方法,中文的tn任务通常通过基于规则的系统来解决,该系统使用关键字和正则表达式来确定歧义词的sfw。这些系统通常将非标准词分为不同的类别,例如缩写,数字等,然后分成子类别,例如电话号码、年份等,这类方法难以解决非标准词语义歧义问题,且后续还需硬编码从非标准词到可读词的转换规则,每种类别都对应着相应的规则,这些工作往往是耗时耗力的。
3、近年,受神经网络在各种自然语言处理任务中的成功启发,sproat等人提出了基于rnn的文本正则化架构,并在英语和俄语的tn任务上表现良好,然而,序列生成模型直接应用到中文tn任务上有几个缺点,直接从模型输出的序列有时会改变应该保持不变的上下文单词,从而导致不可恢复性的错误,并且这些错误不能由模型本身检测到。在中,规则被应用于两个特定的类别来解决这类的错误,但这种方法很难适用于所有情况。中文的另一个挑战是分词,因为字符不像单词是由空格分隔开的,而分词可能取决于上下文。此外,中文中也存在大量的语言歧义问题,如:“2008年”分别对应着“两千零八年”和“二零零八年”,这使得序列生成模型很难训练。
4、因此,目前多采用神经网络模型应用在nsw的分类任务上,2019年,具有自注意力机制并伴随bi-lstm和bi-gru的端到端模型被提出。2022年,dang的等人使用带有bi-gru的模型在nsw的分类任务上取得了显著的效果。同年,dai等人在中文tn任务上提出了基于中文字符粒度的nsw分类方法,并开源了一个中文nsw分类数据集,但此类模型都依赖大量的标注数据来训练,且后续仍需编码nsw到sfw的语法转换规则。2022年,基于wfst和预训练模型的混合方法被提出。该方法使用wfst系统输出所有的候选项,并通过预训练评分模型选择最优选项,以此解决wfst系统的nsw歧义性问题。
5、在全球范围内的开源tn/itn项目中,目前受众最广泛的是谷歌公司推出的c++框架sparrowhawk(https://github.com/google/sparrowhawk)。该框架的不足之处是它仅仅是一个规则执行引擎,谷歌公司并没有开源相关语言的语法规则。此外,sparrowhawk的实现依赖了许多第三方开源库(包括openfst、thrax、re2、protobuf),导致整体框架不够简便、轻量化。另一个较为成熟的项目是nvidia公司开源的nemo_text_processing(https://github.com/nvidia/nemo/tree/main/nemo_text_processing),该项目依旧使用sparro-whawk作为生产环境下的部署工具。与谷歌不同的是,该项目还开源了诸如英语、德语、俄语等多种语言的规则语法。在中文tn/itn规则领域,jiayu等第三方个人开发者曾开源出一套定制化的中文tn/itn规则库chinese_text_normalization(https://github.com/speechio/chinese_text_normalization)。在上述优秀的开源项目基础之上,2022年,wetextprocessing(https://github.com/wenet-e2e/wetextprocessing)是基于wfst语法规则的新系统,其在应用上具有简单易用,生产高效的特点,它使用pynini来编写和编译规则语法,并为中文专门设计和实现一款开源易用的tn/itn工具,它不仅包含了一套完整的中文规则语法,同时也提供了一个可以一键安装使用的python工具包以及比sparrowhawk依赖项更少(生产环境下仅依赖openfst)的整体更轻量化的c++规则处理引擎。
6、本发明的方法结合了基于规则和神经网络模型两者的优点,一是基于规则模型的灵活性、不依赖大量训练数据,更适用于实际生产中,且不会产生像序列生成模型一样的不可恢复性错误,但该系统难以解决非标准词语言歧义问题,因此,本文通过在nsw分类任务上表现最好的语言模型来解决语言歧义问题。结合两者在不同nsw类别上的预测优势,解决长尾问题,整体提高模型的性能。
技术实现思路
1、本发明提供了融合规则与语言模型的端到端文本正则化方法,用于解决非标准词的歧义性问题和模型之间的长尾问题,实现完整的端到端序列生成。
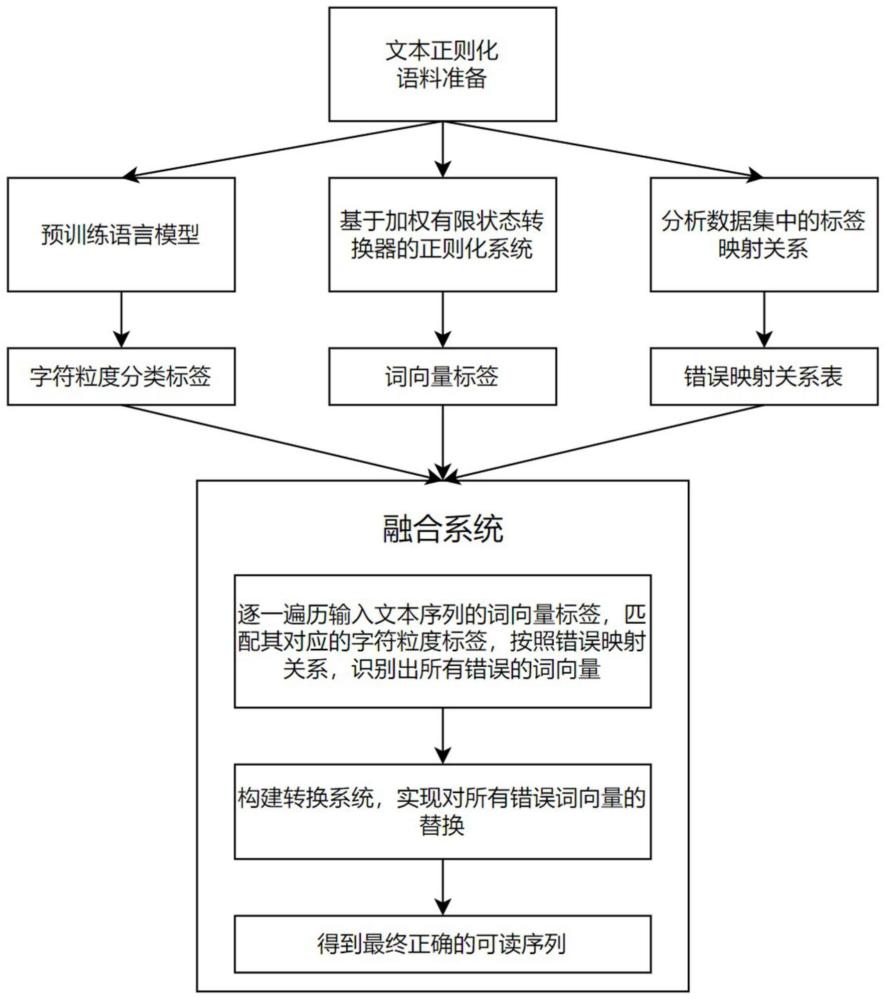
2、本发明的技术方案是:融合规则与语言模型的端到端文本正则化方法,所述方法的步骤为:
3、step1、获取文本正则化语料;在语料准备阶段,使用开源的中文文本正则化数据集,以及开源的今日头条数据集;以此建立了两类数据集用于实验,以验证本文方法的有效性。
4、进一步地,所述step1中,文本正则化语料数据集有两类,一类为中文开源数据集flattn,二类数据集为开源的今日头条中文文本分类数据集,从中选取了7000条含非标准词的数据再结合flattn的测试集合计10000万条,并对此数据集进行人工标注,人工标注包括将所有的非标准词标注为可读词,句子长度分布在10到150之间。
5、进一步地,所述step1中,开源的今日头条数据集选择出含有非标准词的数据,nsw需要具有不同的形式,包括数字、数字序列、缩写、分数、数字范围、电子邮件地址、游戏得分、url;此外,对数据进行规范化处理,删除多余的空格字符、ascii编码、表情符号,html实体等无意义的文本信息;从中选取含非标准词的数据再结合flattn的测试集合计10000万条,由于此数据集下没有符合文本正则化任务的目标集,需要对一万条数据集进行人工标注,人工标注包括将所有的非标准词标注为可读词,并将其划分为训练集、验证集、测试集。
6、step2、预训练语言模型;在预训练语言模型阶段,训练多种bert语言模型,通过分析不同模型之间对训练标签的预测差别,选出最优的语言模型作为建立融合系统的预训练模型;并通过分析总结了flattn数据集与wetextprocessing系统标签之间的正确的对应关系,获取字符粒度分类标签,即flattn正确标签;
7、进一步地,所述step2中,预训练模型最终采用基于bert+linear的模型组合。
8、步骤step2中在形成的预训练模型基础上,测试不同模型对分类标签的预测准确率,通过分析不同模型之间的长尾问题,选择出性能最优的语言模型作为步骤4的预训练模型,才能实现基于规则和语言模型之间的信息共享,解决长尾问题,整体提高模型的性能。
9、step3、构建基于加权有限状态转换器的文本正则化系统,具体的实现了wetextproccessing文本正则化系统,再统计wetextprocessing系统中的错误标签类型;
10、进一步地,所述step3中,wetextprocessing系统产生准确的分类标签来修正原错误token,修正内容包括分类标签cardinal和具体值value,一是需要判断那些token类型需要修正,二是依赖预训练模型生成的分类标签将value值转换正确。
11、步骤step3中tagger阶段输出的错误token为cardinal{value:“三零零人”},只有将“300人”识别为measure类型并将value值转换为“六百人”时推理才完全正确。因为系统无法充分考虑上下文信息,所以容易产生这种推理错误,为了解决该系统的歧义性问题,提出解决方案。
12、step4、分析标签映射关系;分析并总结了wetextprocessing系统的各种错误类型,总结出错误标签与flattn正确标签的对应关系表;
13、步骤step4中每个wetextprocessing错误标签对应的字符粒度标签存在多样性,同一错误类型对应不同的字符粒度标签,导致同一类型错误下的转换策略有所不同,需要根据具体的字符粒度标签情况设计不同的转换策略。
14、进一步地,所述step4中包括:
15、首先通过wetextprocessing中的tagger阶段获得全部token,统计所有易错的标签,找到其对应的预训练模型标签,根据一定的映射关系构建错误映射关系表。
16、step5、构建融合系统;结合基于规则和语言模型的优势,建立融合架构的端到端文本正则化系统,将预训练模型融入wetextprocessing系统中,通过预训练模型生成的字符粒度标签实现对wetextprocessing生成的错误token的替换,从而降低模型的推理错误,构建实现端到端的文本正则化方案。
17、进一步地,所述step5中包括:
18、wetextprocessing系统在tagger阶段输出错误token;所有token都会经过映射表关系进行一次判定,在推理阶段,通过遍历token标签与其内部对应的预训练标签,识别出所有的错误token,错误token将放入转换系统作进一步修正,所有的正确token不作处理;
19、转换系统包括正则化tn与逆正则化itn两个模块,要将token中的value口语词修正;
20、tn模块的内部方法to_cardinal和to_digit调用根据tag值采取不同的策略,而转换系统的内部设计通过分析token和预训练标签的对应关系采取不同策略;
21、待全部token修正完成后继续通过后续的reorder和verbalizer过程完成正则化。
22、进一步地,step5中通过语言模型产生准确的字符粒度标签来修正原wetextprocessing系统产生的错误token,修正内容包括分类标签cardinal和具体值value,一是需要判断那些token类型需要修正,二是依赖预训练模型生成的分类标签按照正确策略将value值转换正确。
23、本发明的有益效果是:本发明结合了基于规则和神经网络模型两者的优点,一是基于规则模型的灵活性、不依赖大量训练数据,更适用于实际生产中,且不会产生像序列生成模型一样的不可恢复性错误,但该系统难以解决非标准词语言歧义问题,因此,本发明通过在nsw分类任务上表现最好的语言模型来解决语言歧义问题。结合两者在不同nsw类别上的预测优势,解决长尾问题,整体提高模型的性能。
24、本发明通过语言模型与基于规则的wfst系统之间共享信息,在标记阶段优化规则系统的错误转换,通过构建新的正则化模块精准处理错误实体从而提高系统的整体性能。实验结果在开源数据集上达到了99.7%的准确率,有效解决规则系统的语言歧义与长尾问题。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24829.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。