基于选择性反投影特征融合的端到端语音编码方法和系统
- 国知局
- 2024-06-21 11:56:17
本发明属于语音处理领域,涉及基于选择性反投影特征融合的端到端语音编码方法和系统。
背景技术:
1、语音通信中,输入语音经过编码端从中提取出语音信号的特征参数,然后利用量化器对提取的特征参数进行量化,达到压缩数据量的目的。解码端对特征参数进行解量化并重建语音信号。随着编码码率的降低,量化比特数减少,导致量化误差增大,进而影响重建语音的质量。尤其是在编码码率低至1.2kbps及以下时,传统语音编码方法的重建语音质量受损更为严重,通常表现为重建语音自然度低并伴随着机械音,严重影响通信质量。
2、近些年来,深度学习在语音编码领域取得了长足的进步,端到端的语音编码方法相比于传统的语音编码方法在质量上取得了较大的提升。现有的端到端语音编码方法在编码端对输入的原始语音信号或者语音声学特征进行下采样,提取中间隐变量特征,并且对其进行矢量量化;在解码端对解量化的中间隐变量特征进行上采样,重建语音信号或者声学特征。现有的端到端语音编码方案一般采用序列式组成的多层下采样卷积模块和多层上采样转置卷积模块用来提取中间隐变量特征和重建语音信号。但是,由于直接使用层级式的卷积模块对输入信号进行下采样会丢失较多输入语音信号中需要保留的信息,同样直接使用层级式的转置卷积模块不能很好地学习到重建语音信号需要的信息,从而导致现有的端到端语音编码算法性能受限。
技术实现思路
1、本发明提供了一种基于选择性反投影特征融合的端到端语音编码方法,可以在编码端下采样过程中更好地保留原始语音的信息,在解码端上采样过程中更好地学习重建语音需要的信息,能够较好地提升重建语音质量。该方法包括以下步骤:
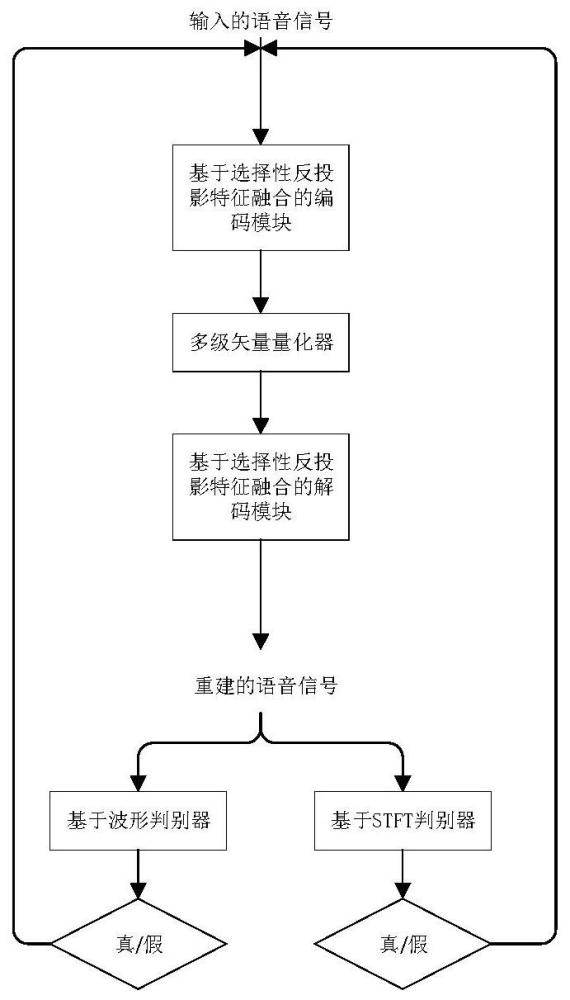
2、步骤1,在编码端,利用基于选择性反投影特征融合的编码模块,从输入语音信号中提取出中间隐变量特征向量e,基于选择性反投影特征融合的编码模块包括多个一维因果卷积和编码模块;
3、所述编码模块包括残差网络和选择性反投影特征融合下采样模块,选择性反投影特征融合下采样模块包括第一下采样卷积、第一上采样卷积、残差网络和第一选择性特征融合模块;
4、步骤2,将步骤1所得的中间隐变量特征向量e进行多级残差矢量量化,并对量化值进行编码;
5、步骤3,将步骤2所得到的量化值进行解量化操作,再将解量化后的中间隐变量特征送入解码端,利用基于选择性反投影特征融合的解码模块得到重建的语音信号,基于选择性反投影特征融合的解码模块包括多个一维因果卷积和解码模块;
6、所述解码模块包括残差网络和选择性反投影特征融合上采样模块,选择性反投影特征融合上采样模块包括第二上采样卷积、第二下采样卷积、残差网络和第二选择性特征融合模块。
7、进一步的,选择性反投影特征融合下采样模块的处理过程如下:
8、输入中间隐变量特征向量x经过一层第一下采样卷积得到中间隐变量特征x1,将中间隐变量特征x1经过一层第一上采样卷积得到中间隐变量特征x2;再将中间隐变量特征x2与输入特征向量x求差,将求差的结果经过残差网络和一层第一下采样卷积得到中间隐变量特征向量x3;将同样维度大小的下采样后的中间隐变量特征x1和中间隐变量特征x3输入第一选择性特征融合模块,得到融合后的中间隐变量特征x4;最后,将融合得到的中间隐变量特征x4经过残差网络得到下采样的中间隐变量特征。
9、进一步的,残差网络包含3个不同膨胀率的残差单元,膨胀率为分别为1,3和9,残差单元由一个一维膨胀卷积和一维因果卷积构成。
10、进一步的,第一选择性特征融合模块的处理过程为:
11、中间隐变量特征x1和中间隐变量特征x3先经过按元素相加得到中间隐变量特征x5,将中间隐变量特征x5经过全局平均池化、一层卷积层、激活函数relu得到特征变量s;将特征变量s经过分别经过两个不同的卷积层得到两个特征变量v1、v3,经过一层softmax得到特征权重矩阵s1和s3;再将特征权重矩阵s1和s3与输入中间隐变量特征x1和x1分别进行元素相乘,对元素相乘后的结果进行相加,得到融合的中间隐变量特征。
12、进一步的,选择性反投影特征融合上采样模块的处理过程如下:
13、输入中间隐变量特征向量y经过一层第二上采样卷积得到中间隐变量特征向量y1。将中间隐变量特征向量y1经过一层第二下采样卷积得到中间隐变量特征向量y2,再将中间隐变量特征向量y2与输入的中间隐变量特征向量y求差;将求差得到的结果经过残差网络和一层第二上采样卷积得到中间隐变量特征向量y3;将同样维度大小的上采样后的中间隐变量特征y1和中间隐变量特征向量y3输入选择性特征融合模块,得到融合后的中间隐变量特征向量y4;最后,将融合得到的中间隐变量特征向量y4经过残差网络,得到上采样的中间隐变量特征。
14、进一步的,第二选择性特征融合模块的处理过程如下;
15、中间隐变量特征向量y1和中间隐变量特征向量y3先按元素相加得到中间隐变量特征向量z1。将中间隐变量特征向量z1经过全局平均池化、一层卷积层、激活函数relu得到特征变量s,将特征变量s经过分别经过两个不同的卷积层得到两个特征变量v1、v3,再经过一层softmax得到特征权重矩阵s1和s3;最后,将对应的特征权重矩阵s1和sc与输入隐变量特征y1和y3分别进行元素相乘,对元素相乘后的结果进行相加,得到融合后的中间隐变量特征。
16、进一步的,还包括步骤4,将步骤3生成的语音信号和原始的语音信号一起输入至基于波形和基于stft的判别器,进行真假判别,在训练过程中使得生成器更好地还原语音信号,所述生成器即步骤1-步骤3构成的整体模型。步骤4仅在训练阶段使用,测试阶段直接经过步骤1-步骤3得到重建的语音信号。
17、进一步的,基于波形的判别器首先对输入的语音信号进行下采样处理,分别得到不同的下采样语音信号:原始语音信号、2倍下采样语音信号和4倍下采样语音信号。然后对下采样语音信号分别进行如下处理:先经过普通卷积处理,然后是四层下采样层,每层下采样都是一维卷积,下采样后的结果将经过一层卷积得到特征图,再经过一层卷积得到最终结果;该判别器通过计算生成语音信号与原始语音信号在不同频带上的差异,以优化训练结果。
18、进一步的,基于stft的判别器是在一个单一的尺度上运行,stft的窗长和窗高分别为w和h,判别器包含2个二维卷积和6个残差单元,每个残差单元包含两层二维卷积层;在最后一个残差单元的输出处,激活的形状为t/(h-23)×f/26,其中t是时域中的样本数,f=w/2是频率维的数目,最后一层通过卷积核为1×f/26的二维卷积将不同频率维的值进行聚合,以在时域中获得与原始输入语音数量相同的一维信号;最后,将基于stft判别器的输出结果输入hinge loss形式的损失函数,进行真假二分类处理,使原始语音的分类结果更接近于1,而生成语音的分类结果更接近于0。
19、本发明还提供一种基于选择性反投影特征融合的端到端语音编码系统,包括如下单元:
20、编码单元,用于在编码端,利用基于选择性反投影特征融合的编码模块,从输入语音信号中提取出中间隐变量特征向量e,基于选择性反投影特征融合的编码模块包括多个一维因果卷积和编码模块;
21、所述编码模块包括残差网络和选择性反投影特征融合下采样模块,选择性反投影特征融合下采样模块包括第一下采样卷积、第一上采样卷积、残差网络和第一选择性特征融合模块;
22、量化单元,用于将的中间隐变量特征向量e进行多级残差矢量量化,并对量化值进行编码;
23、解码单元,用于将得到的量化值进行解量化操作,并将解量化后的中间隐变量特征向量送入解码端,利用基于选择性反投影特征融合的解码模块得到重建的语音信号,基于选择性反投影特征融合的解码模块包括多个一维因果卷积和解码模块;
24、所述解码模块包括残差网络和选择性反投影特征融合上采样模块,选择性反投影特征融合上采样模块包括第二上采样卷积、第二下采样卷积、残差网络和第二选择性特征融合模块。
25、与现有技术相比,本发明解决现有端到端语音编码方案中编码端无法很好保留所需信息,解码端无法还原原始信息的问题,提高重建语音质量。
26、本方法在相同码率下,可以较大提升重建语音质量。在相同码率下,例如在1kbps的码率下,本方法可懂度指标stoi达到0.882,客观visqol指标达到3.465,超过facebook的encodec可懂度0.869,客观visqol指标3.036。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24584.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。