基于边缘设备的离线语音关键词识别方法及装置
- 国知局
- 2024-06-21 11:56:08
本发明涉及语音识别,尤其是指一种基于边缘设备的离线语音关键词识别方法及装置。
背景技术:
1、深度学习的发展,为计算机视觉、自然语言处理、语音识别等人工智能领域带来了革新。而语音识别的发展,打破了人与智能机器设备的距离,让机器能听懂人的语言。其中,语言关键词检测是实现人机语音交互的重要技术,智能音箱、语音助手的基础原理便是使用的关键词识别技术,通过关键词识别技术,对用户输入的语音进行识别,再通过识别后的结果去做下游的任务应用,比如与智能家居相结合,通过语音指令的识别结果去控制相应的设备。
2、现有解决此类问题的方法主要分为两种。一是通过云端部署识别算法或模型来做关键词识别,首先语音识别本地处理模块和音频解码模块对输入的语音进行降噪处理,而后将语音信号转换为数字信号上传到云端服务器进行编码识别和语义理解,再将处理结果通过网络反馈回智能音箱。显然这是一种高成本的方案,并且对于网络带宽也有很大的需求以及会造成不可避免的网络传输延迟。二是直接在边缘设备的处理器上进行关键词检测技术的部署,但是对于传统技术直接在设备上的部署,需要占据较大的资源和算力,不仅功耗较大,识别速度也不理想。因此,在边缘设备关键词识别的应用场景中如何同时实现资源、算力友好的离线高效识别的目标成为本领域研究人员亟需解决的问题。
技术实现思路
1、本发明所要解决的技术问题是:如何在离线环境下,对语音关键词进行高效识别。
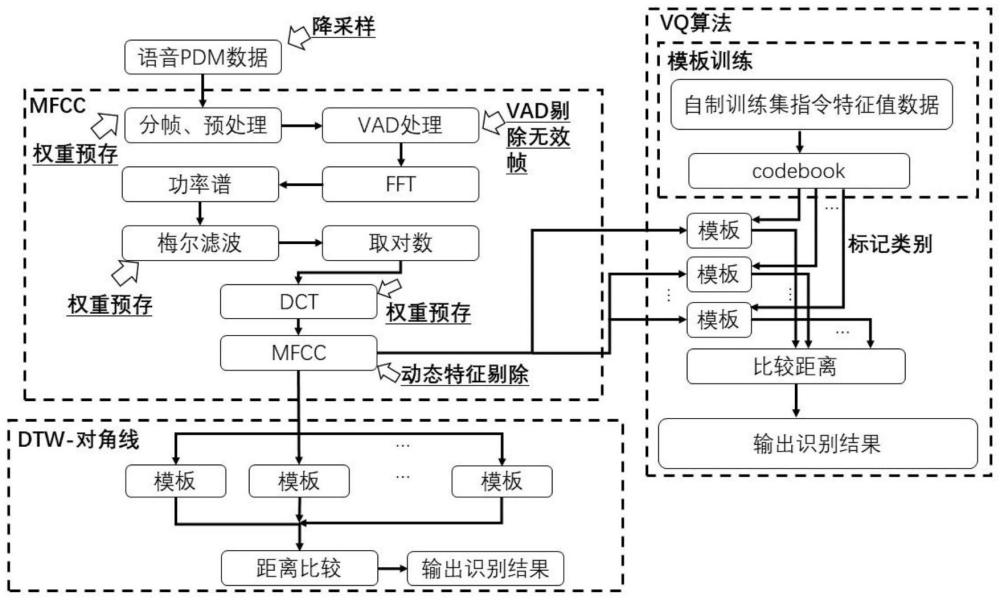
2、为了解决上述技术问题,本发明采用的技术方案为:一种基于边缘设备的离线语音关键词识别方法,包括步骤:
3、通过降采样策略对语音pdm数据进行降采样处理;
4、通过权重预存策略中的窗函数权重预存,将预加重的语音pdm数据与预先生成的窗函数离散值进行查找表乘积,得到预处理后的输出;
5、通过vad剔除无效帧策略对降采样处理的语音pdm数据中的分帧后的每帧数据进行能量提取和过零提取,并根据阈值剔除掉无效的语音帧;
6、通过权重预存策略中的梅尔滤波器组权重预存,将每一帧的频谱能量数据通过与预存好的梅尔滤波器组数组进行查找表运算求和,得到梅尔频谱输出,之后通过对梅尔频谱输出进行对数运算,得到梅尔能量特征;
7、通过权重预存策略中的离散余弦变换运算中的权重预存,将每一帧的梅尔能量特征与余弦权重进行对应点的查找表运算得到mfcc特征系数;
8、通过动态特征剔除策略将mfcc特征系数对应的一阶差分和二阶差分数据进行剔除,得到输出的mfcc特征数据;
9、通过dtw识别算法对角线策略运算输入语音和模板间对应帧的mfcc特征系数的距离,再通过阈值判别得到最后的识别结果;
10、通过机器学习提升识别精度策略提升语音识别精度,最后经阈值判别得到最后的语音关键词识别结果。
11、进一步的,通过降采样策略对语音pdm数据进行降采样处理具体为,
12、通过将不同采样率的语音pdm数据进行抽样,调整成4k采样率的每帧为128点的pdm数据,作为mfcc特征提取算法的输入。
13、进一步的,通过权重预存策略中的窗函数权重预存,将预加重的语音pdm数据与预先生成的窗函数离散值进行查找表乘积,得到预处理后的输出具体为,
14、通过权重预存策略中的窗函数权重预存,将预加重的语音pdm数据与预先生成的128点窗函数离散值进行查找表乘积,得到预处理后的输出。
15、进一步的,通过vad剔除无效帧策略对降采样处理的语音pdm数据中的分帧后的每帧数据进行能量提取和过零提取,并根据阈值剔除掉无效的语音帧具体为,
16、通过预处理后语音序列中的每帧数据中的数据进行平方谱能量求和以及数据正负跳变值求和,从而剔除过程中的噪声帧,得到语音序列的有效帧,之后语音数据序列中的有效帧通过128点快速傅里叶运算和65点的功率谱运算得到每一帧的65点频谱能量输出。
17、进一步的,通过权重预存策略中的梅尔滤波器组权重预存,将每一帧的频谱能量数据通过与预存好的梅尔滤波器组数组进行查找表运算求和,得到梅尔频谱输出,之后通过对梅尔频谱输出进行对数运算,得到梅尔能量特征具体为,
18、通过权重预存策略中的梅尔滤波器组权重预存,将每一帧的65点频谱能量数据通过与预存好的梅尔滤波器组数组进行查找表运算求和,得到20维的梅尔频谱输出,之后通过对梅尔频谱输出进行对数运算,得到20维的梅尔能量特征。
19、进一步的,通过权重预存策略中的离散余弦变换运算中的权重预存,将每一帧的梅尔能量特征与余弦权重进行对应点的查找表运算得到mfcc特征系数具体为,
20、通过权重预存策略中的离散余弦变换运算中的权重预存,将每一帧20点的梅尔能量特征与余弦权重进行对应点的查找表运算得到13维的mfcc特征系数。
21、进一步的,通过动态特征剔除策略将mfcc特征系数对应的一阶差分和二阶差分数据进行剔除,得到输出的mfcc特征数据具体为,
22、通过动态特征剔除策略将mfcc特征系数对应的一阶差分和二阶差分数据进行剔除,得到13维输出的mfcc特征数据。
23、进一步的,通过机器学习提升识别精度策略提升语音识别精度,最后经阈值判别得到最后的识别结果具体为,
24、通过对语音训练集提取特征数据,并将特征数据训练集通过机器学习聚类的方式,学习出每个聚类中心的特征数据,得到多个类别模板的mfcc特征数据,之后计算输入语音序列的mfcc特征系数和模板mfcc特征数据的距离,再通过阈值判别得到最后的识别结果。
25、本发明还提供了一种基于边缘设备的离线语音关键词识别装置,包括:
26、降采样模块,用于通过降采样策略对语音pdm数据进行降采样处理;
27、预处理模块,用于通过权重预存策略中的窗函数权重预存,将预加重的语音pdm数据与预先生成的窗函数离散值进行查找表乘积,得到预处理后的输出;
28、无效帧剔除模块,用于通过vad剔除无效帧策略对降采样处理的语音pdm数据中的分帧后的每帧数据进行能量提取和过零提取,并根据阈值剔除掉无效的语音帧;
29、梅尔能量特征计算模块,用于通过权重预存策略中的梅尔滤波器组权重预存,将每一帧的频谱能量数据通过与预存好的梅尔滤波器组数组进行查找表运算求和,得到梅尔频谱输出,之后通过对梅尔频谱输出进行对数运算,得到梅尔能量特征;
30、mfcc特征系数计算模块,用于通过权重预存策略中的离散余弦变换运算中的权重预存,将每一帧的梅尔能量特征与余弦权重进行对应点的查找表运算得到mfcc特征系数;
31、mfcc特征计算模块,用于通过动态特征剔除策略将mfcc特征系数对应的一阶差分和二阶差分数据进行剔除,得到输出的mfcc特征数据;
32、阈值判别模块,用于通过dtw识别算法对角线策略运算输入语音和模板间对应帧的mfcc特征系数的距离,再通过阈值判别得到最后的识别结果;
33、识别精度提升模块,用于通过机器学习提升识别精度策略提升语音识别精度,最后经阈值判别得到最后的语音关键词识别结果。
34、本发明还提供了一种计算机设备,所述计算机设备包括存储器及处理器,所述存储器上存储有计算机程序,所述处理器执行所述计算机程序时实现如上所述的基于边缘设备的离线语音关键词识别方法。
35、本发明的有益效果在于:方案包括降采样策略,vad剔除无效帧策略,权重预存策略,动态特征剔除策略,对角线策略,自制训练集的vq算法策略。本技术方案能够实现在算力和资源有限的边缘端进行部署,并能在不依靠云服务器的情况下,对外部语音pdm数据进行快速特征提取以及高效实时的关键词识别,并能通过外接智能设备,根据不同识别结果对外界智能设备进行控制。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24570.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表