一种音视频全方位拟真培训方法及系统与流程
- 国知局
- 2024-06-21 13:48:25
本发明涉及音视频仿真,尤其涉及一种音视频全方位拟真培训方法及系统。
背景技术:
1、音视频全方位拟真培训模型是用于模拟实际场景和活动,提供高度沉浸和交互性的培训体验,使坐席人员能够在虚拟环境中练习和学习,使坐席人员提高技能、获取更多的知识和感受更好的体验,有助于增强培训效果,并扩展使用该培训模型的应用范围。
2、现有的相关培训模型要么通过音频和视频同步感知模型,但没有考虑到如何对学习人员进行仪态行为检测,也没有捕捉数据中的非线性关系;要么相关技术通过虚拟现实(virtual reality,vr)培训学习系统进行拟真,但又没有考虑到结合音视频提高拟真培训模型的效率,也就无法考虑到通过音频数据和视频数据进行同步分析;或者,相关技术通过融合了ai技术和视频技术的师承教学方法进行拟真,但是也没有对学习人员进行仪态行为检测。
3、总之,现有的相关技术的适用性低,只面向同一种业务场景,且无法检测坐席人员的仪态行为,不能根据同步音视频数据对坐席人员进行全方位拟真培训,导致拟真培训的精确度和培训效率低。
技术实现思路
1、本发明的目的是针对上述现有技术的不足,提出一种音视频全方位拟真培训方法及系统,能够提高培训拟真的精确度和培训效率。
2、第一方面,本发明提供了一种音视频全方位拟真培训方法,包括:
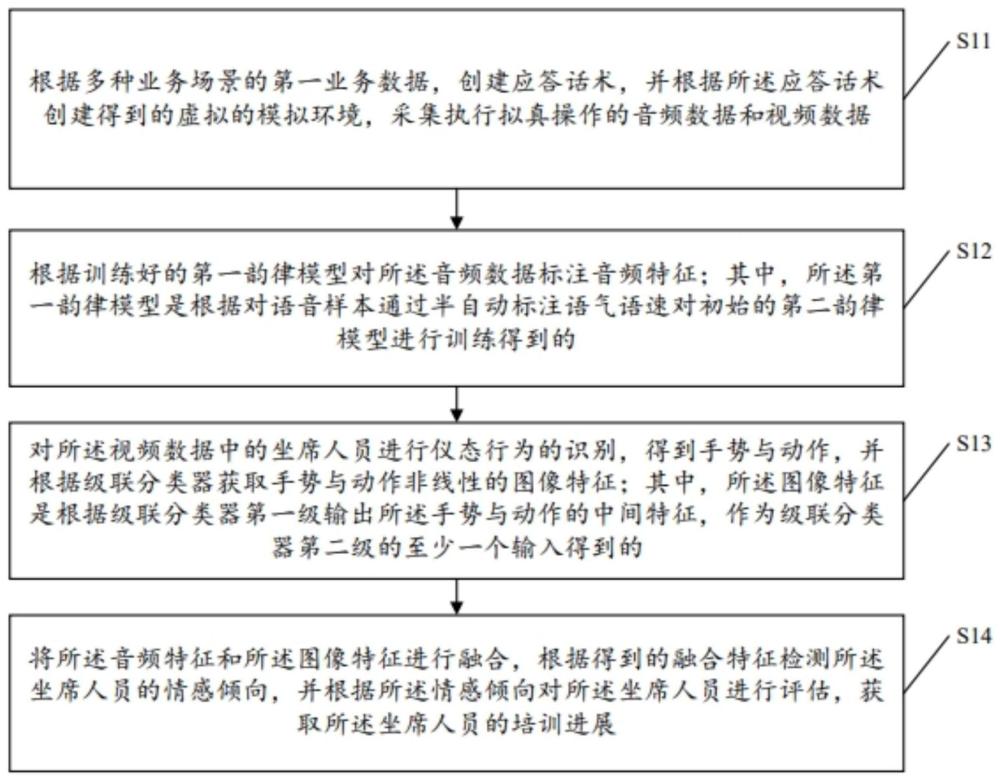
3、根据多种业务场景的第一业务数据,创建应答话术,并根据所述应答话术创建得到的虚拟的模拟环境,采集执行拟真操作的音频数据和视频数据;
4、根据训练好的第一韵律模型对所述音频数据标注音频特征;其中,所述第一韵律模型是根据对语音样本通过半自动标注语气语速对初始的第二韵律模型进行训练得到的;
5、对所述视频数据中的坐席人员进行仪态行为的识别,得到手势与动作,并根据级联分类器获取手势与动作非线性的图像特征;其中,所述图像特征是根据级联分类器第一级输出所述手势与动作的中间特征,作为级联分类器第二级的至少一个输入得到的;
6、将所述音频特征和所述图像特征进行融合,根据得到的融合特征检测所述坐席人员的情感倾向,并根据所述情感倾向对所述坐席人员进行评估,获取所述坐席人员的培训进展。
7、结合第一方面,在一些实施例中,所述图像特征是根据级联分类器第一级输出所述手势与动作的中间特征,作为级联分类器第二级的至少一个输入得到的,包括:
8、分别根据主成分分析法和线性鉴别分析方法,分别获取所述手势与动作的主成分向量和线性鉴别结果;
9、将所述手势与动作作为级联分类器第一级的输入,获取中间特征,并将所述中间特征、所述主成分向量和所述线性鉴别结果作为级联分类器第二级的输入,得到非线性的图像特征。
10、本发明通过训练好的半自动标注语气语速的第一韵律模型对音频数据获取音频特征,便于根据音频特征融合视频特征对坐席人员的情绪进行精准检测,从而能够提高基于情绪的培训评估,进而提高精确度和培训效率;对视频数据深度剖析坐席人员的仪态行为,识别坐席人员在拟真操作时的手势与动作,并通过级联分类器获取手势与动作的非线性特征,从而能够进一步提高培训拟真的精确度,并便于根据非线性特征对坐席人员的仪态行为进行精确评估,进而提高了拟真培训的准确性。总之,本发明采用音频和视频两个数据向方位对坐席人员在模拟环境下的拟真操作进行全方位培训,能够提高培训拟真的精确度和培训效率,并对多种业务进行业务向的全方位培训,能够适用于更多坐席人员的拟真培训,具有更高的适用性。
11、结合第一方面,在一些实施例中,在所述获取所述坐席人员的培训进展之后,还包括:
12、调查多个地区的第二业务数据,构建全业务场景覆盖,并通过配置离散节点对全业务场景进行全量输出。
13、结合第一方面,在一些实施例中,所述通过配置离散节点对全业务场景进行全量输出,包括:
14、将所述图像特征中连续的仪态行为特征作为当前节点的分裂特征,并选取离散节点作为分裂点,将所述分裂点按照所述分裂特征进行分裂,得到子节点,直到每个子节点都达到停止条件时停止分裂,将所有叶子节点的输出作为全业务场景的全量输出;其中,所述叶子节点是不可再分裂的子节点。
15、结合第一方面,在一些实施例中,所述对所述视频数据中的坐席人员进行仪态行为的识别,得到手势与动作,包括:
16、从所述视频数据中获取与手势相关的深度图像,并从所述深度图像中提取手势特征;其中,所述手势特征包括:手的形状、轮廓、关节的关键点和运动轨迹;
17、根据图像卷积和边缘检测方法对所述手势特征检测手势信息,并跟踪所述手势信息,捕获多个手势动作,将所述多个手势动作进行手势分类,识别出手势与动作。
18、结合第一方面,在一些实施例中,所述第一韵律模型是根据对语音样本通过半自动标注语气语速对初始的第二韵律模型进行训练得到的,包括:
19、对初始的第一语音样本进行降噪、归一化和分帧的预处理,并分别对得到的第二语音样本提取训练语速数据和训练语气数据;
20、对所述第二语音样本进行半自动标注,得到半自动标注数据;其中,所述半自动标注数据包括:快、慢与正常三种语速标注,以及愉快、生气与平静三种语气标注;
21、根据所述训练语速数据、所述训练语气数据和所述半自动标注数据,对初始的第二韵律模型进行训练,得到训练好的第一韵律模型。
22、本发明通过在训练时,通过半自动标注语气语速,并建立语气语速的韵律模型分析坐席人员的语气和语速,便于从语气和语速评测坐席人员的能力,从而根据语气和语速的模态对音频数据和视频数据进行同步分析,进而提高分析培训拟真的精确度和培训效率。
23、结合第一方面,在一些实施例中,所述分别对得到的第二语音样本提取训练语速数据和训练语气数据,包括:
24、通过计算所述第二语音样本在每分钟的音节数和词数来衡量语速的快慢程度,得到训练语速数据;
25、通过获取所述第二语音样本在基频、能量、时长和声带振动上的声学特征来,得到训练语气数据。
26、结合第一方面,在一些实施例中,所述根据多种业务场景的第一业务数据,创建应答话术,包括:
27、采集同一地区的多种业务场景初始的年业务数据,并对所述年业务数据进行提取概括,获取多种业务场景的第一业务数据,并根据第一业务数据创建应答话术;其中,所述提取概括是根据对年业务数据的统计数据、趋势、关联性和模式进行检测得到的概括性信息。
28、本发明通过提取概括多种业务场景的年业务数据,能够形成覆盖面广、培训效果好的应答话术,从而提高了应答话术的灵活性。
29、结合第一方面,在一些实施例中,所述多种业务场景包括:常见业务场景和特殊业务场景;其中,
30、所述常见业务场景包括:教育培训模拟、医疗医学模拟、游戏娱乐模拟和体育训练;
31、所述特殊业务场景包括:飞行模拟、船舶航海培训模拟、建筑施工培训模拟、药物研发模拟和艺术文化模拟。
32、第二方面,本发明提供了一种音视频全方位拟真培训系统,包括:数据采集模块、音频特征获取模块、视频特征获取模块和评价模块;其中,
33、所述数据采集模块,用于根据多种业务场景的第一业务数据,创建应答话术,并根据所述应答话术创建得到的虚拟的模拟环境,采集执行拟真操作的音频数据和视频数据;
34、所述音频特征获取模块,用于根据训练好的第一韵律模型对所述音频数据标注音频特征;其中,所述第一韵律模型是根据对语音样本通过半自动标注语气语速对初始的第二韵律模型进行训练得到的;
35、所述视频特征获取模块,用于对所述视频数据中的坐席人员进行仪态行为的识别,得到手势与动作,并根据级联分类器获取手势与动作非线性的图像特征;其中,所述图像特征是根据级联分类器第一级输出所述手势与动作的中间特征,作为级联分类器第二级的至少一个输入得到的;
36、所述评价模块,用于将所述音频特征和所述图像特征进行融合,根据得到的融合特征检测所述坐席人员的情感倾向,并根据所述情感倾向对所述坐席人员进行评估,获取所述坐席人员的培训进展。
本文地址:https://www.jishuxx.com/zhuanli/20240618/34584.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表