一种基于能效曲线的锅炉负荷分配方法与流程
- 国知局
- 2024-08-01 02:16:08
本发明涉及热电生产,尤其涉及一种基于能效曲线的锅炉负荷分配方法。
背景技术:
1、母管制锅炉的蒸汽压力是机组运行的主要控制参数,直接影响到机组的安全及经济运行,在母管制运行方式下,需根据母管压力与给定值的偏差,向各并列运行的锅炉发出增减负荷的信号,各锅炉接收信号并调节燃料量与风量,以快速满足负荷要求,进而响应母管压力的调整。
2、现有锅炉机组负荷分配方式有按锅炉机组的负荷比例分配、按机组总效率最高的原则分配、按燃料消耗量微增率相等的原则分配,这些分配方式,通常都要基于锅炉的能效数据进行。
3、锅炉能效一般需要通过能效测试机构到现场进行测试确定,或基于历史运行数据利用正平衡法或反平衡法计算,其中正平衡法没有考虑蒸汽湿度、锅炉热损失等带来的影响,计算所得能效数据受运行参数及噪声数据影响太大,而反平衡法中的各项热损失需要较多的测量且数据采集难度大,某些损失无法直接测量只能通过估计得到。
4、现有的锅炉负荷分配方法,基于上述锅炉能效的获取方式,存在锅炉能效计算误差较大、锅炉之间的负荷分配经济性较差,或者计算过程难度较大导致的实用性不高的问题。
技术实现思路
1、(一)要解决的技术问题
2、鉴于现有技术的上述缺点、不足,本发明提供了一种基于能效曲线的锅炉负荷分配方法。
3、(二)技术方案
4、为了达到上述目的,本发明采用的主要技术方案包括:
5、第一方面,本发明实施例提供一种基于能效曲线的锅炉负荷分配方法,包括以下步骤:
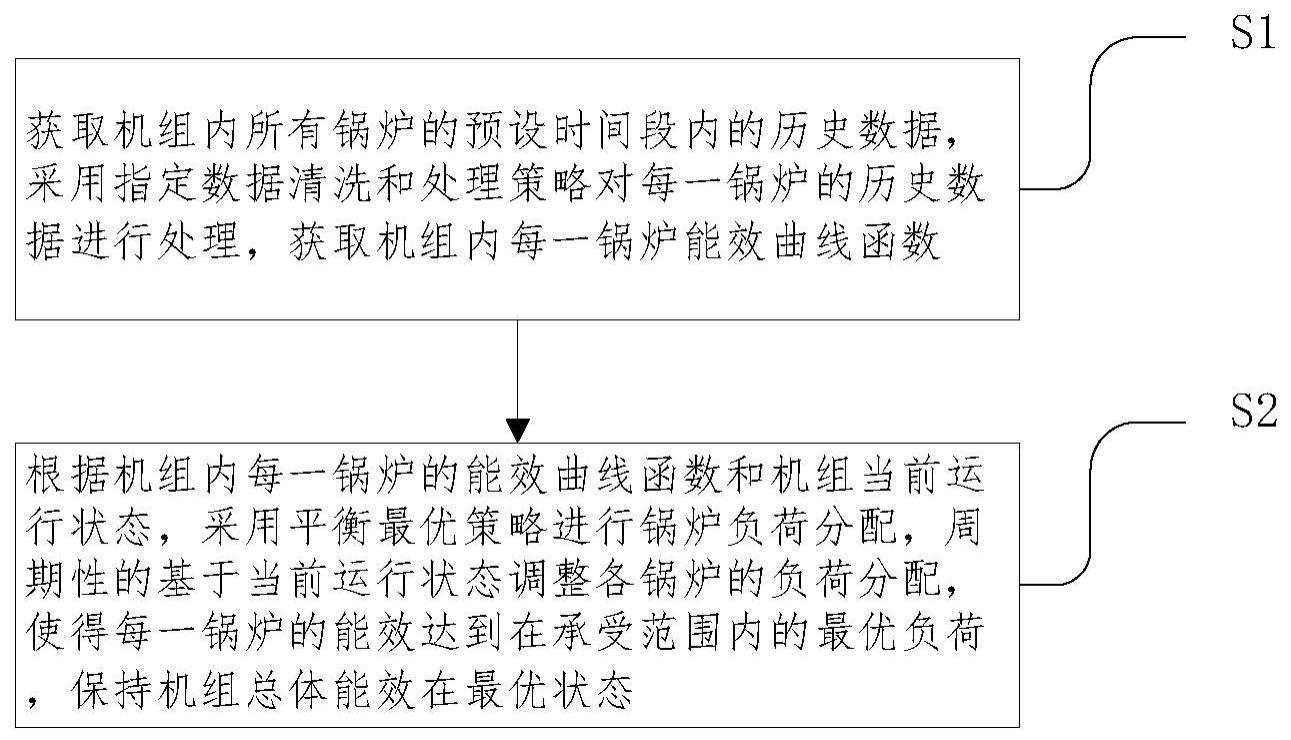
6、s1,获取机组内所有锅炉的预设时间段内的历史数据,采用指定数据清洗和处理策略对每一锅炉的历史数据进行处理,获取机组内每一锅炉能效曲线函数;
7、s2,根据机组内每一锅炉的能效曲线函数和机组当前运行状态,采用平衡最优策略进行锅炉负荷分配,周期性的基于当前运行状态调整各锅炉的负荷分配,使得每一锅炉的能效达到在承受范围内的最优负荷,保持机组总体能效在最优状态;
8、所述机组当前运行状态包括:机组内所有锅炉的当前运行负荷、额定负荷,机组总待分配负荷量,负荷最小调整量;所述机组内锅炉数量大于1。
9、可选地,所述s1获取机组内所有锅炉的预设时间段内的历史数据包括:
10、以分钟为单位获取锅炉历史运行数据,包含时间戳、燃料消耗量、锅炉负荷、蒸汽压力、蒸汽温度、给水压力、给水温度;
11、以天或班组为单位获取燃料化验报表数据,包含时间戳、燃料低位发热量;
12、以分钟为单位获取热损失衡量指标数据,包含时间戳、烟气量、烟气温度、排烟氧含量、煤粉细度、炉膛温度、烟气中不同气体的含量。
13、可选地,所述s1包括:
14、s101,以时间戳为索引对所述历史数据进行横向拼接,并滑动过滤选择锅炉负荷波动幅度小于工况稳定预设阈值的运行数据段作为工况稳定能效数据集;
15、s102,基于工况稳定能效数据集,根据热损失衡量指标利用箱线图法进行过滤,选择满足热损失衡量指标预设阈值的有效数据段作为第一预处理数据集;
16、其中,所述热损失衡量指标包括下述的一种或多种:烟气量、烟气温度、排烟氧含量、煤粉细度、炉膛温度和烟气中不同气体的含量;
17、s103,根据第一预处理数据集计算得到锅炉能效e,并合入第一预处理数据,得到第二预处理数据集;
18、其中,锅炉能效e计算公式如下:
19、
20、其中,
21、h给水=h(p给水,t给水),
22、h蒸汽=h(p蒸汽,t蒸汽),
23、q为锅炉负荷,c为燃料消耗量,qnet为燃料低位发热量,p给水、t给水分别为给水压力与给水温度,p蒸汽、t蒸汽分别为蒸汽压力与蒸汽温度,h为计算水和水蒸气焓值的函数;
24、s104,对第二预处理数据集进行异常点处理,生成能效模型数据集;
25、s105,对能效模型数据集拟合二次多项式曲线,得到锅炉能效曲线函数:
26、e=f(q),
27、其中,以q为锅炉负荷,e为锅炉能效。
28、可选地,所述滑动过滤选择锅炉负荷波动幅度小于工况稳定预设阈值的运行数据段包括:
29、以长度大于10分钟的窗口沿时间戳滑动,选择锅炉负荷波动幅度小于工况稳定预设阈值的运行数据段作为有效数据;
30、其中,工况稳定预设阈值为1%。
31、可选地,所述s102利用箱线图法进行过滤,包括:
32、确定热损失衡量指标上四分位数q1,下四分位数q3,四分位间距iqr=q1-q3,则有效数据上限为q1+1.5*iqr,有效数据下限为q3-1.5*iqr。
33、可选地,所述s104包括以下步骤:
34、ss1,以预设步长值为间隔将锅炉负荷q划分为等长区间,根据锅炉负荷q的区间分布将第二预处理数据集划分为不同的区间;
35、ss2,针对每一区间,利用bp神经网络预测模型进行异常点处理,生成区间有效数据;
36、ss3,合并各区间有效数据,得到能效模型数据集;
37、其中,预设步长值为1。
38、可选地,所述ss2包括:
39、所述bp神经网络预测模型以热损失衡量指标为自变量,以锅炉能效e为因变量,包含输入层、隐藏层、输出层,并选择tanh作为神经元激活函数;
40、所述bp神经网络预测模型利用所在区间内数据进行训练,获得区间预测模型;
41、利用区间预测模型对区间内数据进行预测,得到预测值,并根据以下公式计算绝对误差百分比:
42、
43、将绝对误差百分比大于误差阈值预设值的数据作为异常点剔除,其余有效数据保存为该区间有效数据;
44、其中,所述误差阈值预设值σ的取值范围为:
45、0.1≥σ≥0.01。
46、可选地,所述采用平衡最优策略进行锅炉负荷分配,包括以下具体步骤:
47、s2-1,根据每一锅炉的能效曲线函数,得到使得每一锅炉的能效达到最大值的每一锅炉的最优负荷;
48、s2-2,根据每一锅炉的最优负荷、当前运行负荷、额定负荷得到每一锅炉的负荷分配因子;
49、s2-3,根据机组内所有锅炉的负荷分配因子,以及机组总待分配负荷量、负荷最小调整量进行负荷分配:
50、若机组总待分配负荷量>0,对负荷分配因子最小的锅炉分配增加负荷最小调整量的负荷;
51、若机组总待分配负荷量<0,对负荷分配因子最大的锅炉分配减少负荷最小调整量的负荷;
52、s2-4,若机组总待分配负荷量=0,锅炉负荷分配结束;否,则更新机组当前运行状态,并重复s2-2和s2-3。
53、可选地,所述s2-2包括:
54、根据以下公式计算负荷分配因子:
55、
56、其中,κi为锅炉i的负荷分配因子,qi为锅炉i的当前运行负荷,为锅炉i的额定负荷,qi,best为锅炉i的最优负荷。
57、第二方面,本发明提供一种计算机装置,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述基于能效曲线的锅炉负荷分配方法的步骤。
58、(三)有益效果
59、与现有技术相比,本发明基于机组内每一锅炉的能效曲线函数和机组当前运行状态,采用平衡最优策略进行锅炉负荷分配,周期性的基于当前运行状态调整各锅炉的负荷分配,使得每一锅炉的能效达到在承受范围内的最优负荷,保持机组总体能效在最优状态,实现多炉之间的协调优化控制,为机组的经济、安全运行提供精准支撑。提高了可靠性,安全性,稳定性,效率更高,准确性更好。
60、进一步地,本发明利用大量的锅炉历史数据,通过有效的数据清洗和过滤手段,包括通过滑动过滤选择锅炉负荷波动幅度小的工况稳定数据,以及利用热损失衡量指标基于箱线图法对数据的预处理,在降低能效计算过程中热损失影响的同时,避免了数据采集难度及测量精度带来的影响,提高了所获得能效曲线的准确性和有效性。
61、同时,在锅炉机组的负荷分配过程中,本发明利用拟合得到的能效曲线函数以及锅炉当前运行状态计算负荷分配因子,当负荷需求增加时优先分配给负荷分配因子最小的锅炉,当负荷需求减小时优先分配给负荷分配因子最大的锅炉,以保证各个锅炉运行负荷距离最优运行状态的相对距离大致相当;本发明所述分配方法兼顾经济性与安全运行的同时,摆脱了对运行人员技术水平的限制,实时的负荷分配计算结果指导实现多炉之间的协调优化控制,为机组的经济、安全运行提供精准支撑。
本文地址:https://www.jishuxx.com/zhuanli/20240724/208204.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。