一种基于大语言模型的多文档智能问答方法及系统与流程
- 国知局
- 2024-07-31 22:41:54
本发明涉及人工智能,具体涉及一种基于大语言模型的多文档智能问答方法及系统。
背景技术:
1、随着企业数字化进程的深入推进和行业经验的不断积累,用电需求分析预测经验成果库已聚集大量的宝贵信息资料,这些资料包括数据治理、电力电量分析预测、业务机制完善等方面的文档。尽管这些经验和资料对企业决策和业务发展具有极高的价值,但由于资料体量庞大,使得有效检索和利用这些信息变得相对困难。
2、因此需要一种能够从大量信息中进行高效检索并利用检索信息进行智能问答的系统,然而,传统的问答系统在处理和分析大规模、非结构化数据时效果不佳,并且缺乏灵活性,这些系统通常依赖预设的规则和有限的知识库,例如知识图谱,知识图谱的构建取决于已有的电力信息经验成果库,已有的经验成果库内容有限,如果库中的内容已经更新,可能导致知识图谱的覆盖范围受限,无法涵盖最新的电力信息,难以适应电网运维中不断变化和日益增长的信息需求。
3、其次,传统的问答系统在理解复杂查询和提供精准、个性化答案方面能力有限,例如faq检索系统,faq检索系统需要依赖预设的规则基于经验成果库提前制作好通用性问答,只能针对制作好的通用性问答进行解答,无法提供精准和个性化的答案,因此可能输出错误信息,进而导致错误的决策,影响电网的安全和稳定。
技术实现思路
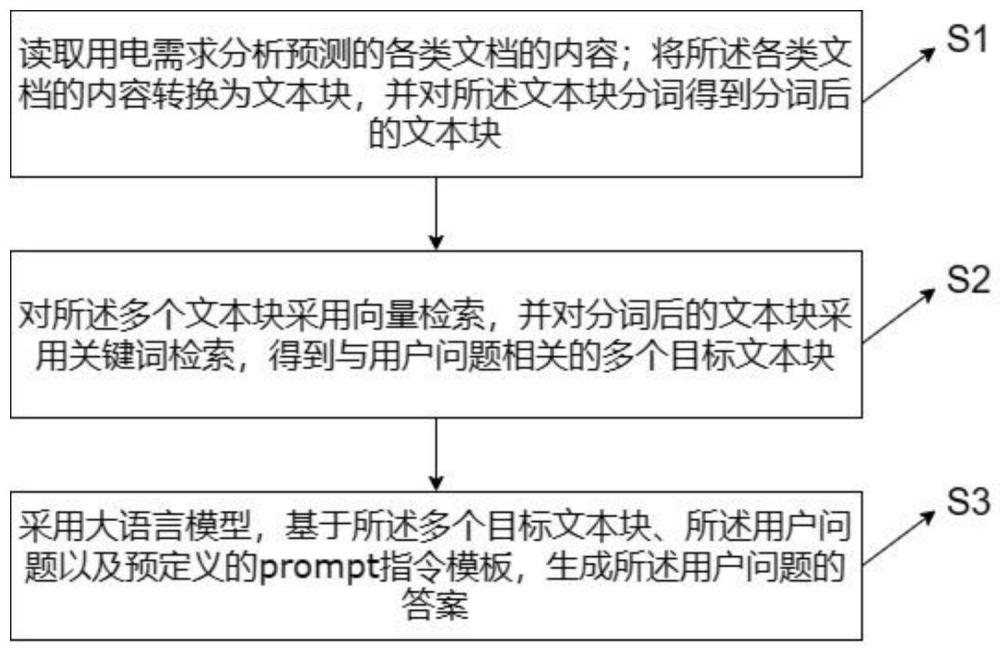
1、为克服上述现有技术的不足,本发明提出一种基于大语言模型的多文档智能问答方法,包括:
2、读取用电需求分析预测的各类文档的内容;将所述各类文档的内容转换为文本块,并对所述文本块分词得到分词后的文本块;
3、对所述多个文本块采用向量检索,并对分词后的文本块采用关键词检索,得到与用户问题相关的多个目标文本块;
4、采用大语言模型,基于所述多个目标文本块、所述用户问题以及预定义的prompt指令模板,生成所述用户问题的答案。
5、可选的,所述将所述各类文档的内容转换为文本块,并对所述文本块分词得到分词后的文本块,包括:
6、将所述各类文档的内容根据预设的字符数量分割为多个分块,根据预设的拼接数量将分块拼接为多个文本块;
7、利用jieba分词技术将每个文本块进行分词,得到分词后的文本块。
8、可选的,所述对所述多个文本块采用向量检索,并对分词后的文本块采用关键词检索,得到与用户问题相关的多个目标文本块,包括:
9、计算每个文本块与所述用户问题之间的向量相似度,基于向量相似度对所述每个文本块排名,并获取与所述用户问题的向量相似度最高的m个文本块;
10、计算每个分词后的文本块与所述用户问题之间的关键词检索分数,基于关键词检索分数对所述每个分词后的文本块排名,并获取关键词检索分数最高的w个分词后的文本块;
11、汇总所述m个文本块和w个分词后的文本块得到t个文本块,其中t≤m+w;
12、基于所述m个文本块的排名和所述w个分词后的文本块的排名,采用倒数排序融合算法重新排序,确定与用户问题相关度最高的多个目标文本块。
13、可选的,所述计算每个文本块与所述用户问题之间的向量相似度,包括,
14、基于bge嵌入模型分别对所述用户问题和所述每个文本块进行向量表征,得到所述用户问题的嵌入向量,以及所述每个文本块的嵌入向量;
15、根据所述每个文本块的嵌入向量和所述用户问题的嵌入向量,结合向量相似度计算式,得到所述每个文本块与所述用户问题的向量相似度。
16、可选的,所述向量相似度计算式为:
17、
18、其中,d(a,b)表示文本块a与用户问题b之间的向量相似度;n表示用户问题b和文本块a的嵌入向量为n维向量;文本块a的嵌入向量为a=(a1,a2,…,ai,…,an);用户问题b的嵌入向量为b=(b1,b2,…,bi,…,bn)。
19、可选的,所述计算所述每个分词后的文本块与所述用户问题之间的关键词检索分数,包括:
20、将所述用户问题分词后得到多个关键词,针对每个关键词,获取所述关键词在每个分词后的文本块中的词频;
21、获取所述每个关键词的逆文档频率;
22、基于所述每个关键词的逆文档频率以及所述每个关键词在分词后文本块中的词频,结合bm25算法表达式,得到每个分词后的文本块与所述用户问题之间的关键词检索分数。
23、可选的,所述bm25算法表达式为:
24、
25、其中,score(d,q)表示分词后的文本块d与用户问题q的关键词检索分数;qj表示用户问题q中的第j个关键词;α表示用户问题中关键词的数量;idf(qj)表示用户问题q中的第j个关键词的逆文档频率;f(qj,d)表示用户问题q中的第j个关键词在分词后的文本块d中的词频;k和β均表示可调参数,用于平衡词频影响;d|表示分词后的文本块d中的总词数;avgdl表示所有文本块的长度均值。
26、可选的,所述倒数排序融合算法的表达式为:
27、
28、其中,score表示文本块的倒数排序融合分数;c表示检索方式的总数,所述检索方式包括向量检索和关键词检索;g为常数,用于调节排名的影响力;rankh表示文本块在第h个检索方式中的排名。
29、可选的,所述采用大语言模型,基于所述多个目标文本块、用户问题以及预定义的prompt指令模板,生成所述用户问题的答案之后,还包括返回所述答案的所在文档来源。
30、基于同一发明构思,本发明提出一种基于大语言模型的多文档智能问答系统,包括:
31、文档预处理模块:用于将用电需求分析经验成果库中的每个文档分割为多个文本块,并对所述文本块进行分词得到分词后的文本块;
32、相关度筛选模块:用于根据用户问题对所述多个文本块进行向量检索,并基于分词后的用户问题对分词后的文本块进行关键词检索,得到与用户问题相关的多个目标文本块;
33、答案生成模块:用于采用大语言模型,基于所述多个目标文本块、用户问题以及预定义的prompt指令,生成所述用户问题的答案。
34、可选的,所述文档预处理模块中,将所述各类文档的内容转换为文本块,并对所述文本块分词得到分词后的文本块,包括:
35、将所述各类文档的内容根据预设的字符数量分割为多个分块,根据预设的拼接数量将分块拼接为多个文本块;
36、利用jieba分词技术将每个文本块进行分词,得到分词后的文本块。
37、可选的,所述相关度筛选模块中,对所述多个文本块采用向量检索,并对分词后的文本块采用关键词检索,得到与用户问题相关的多个目标文本块,包括:
38、计算每个文本块与所述用户问题之间的向量相似度,基于向量相似度对所述每个文本块排名,并获取与所述用户问题的向量相似度最高的m个文本块;
39、计算每个分词后的文本块与所述用户问题之间的关键词检索分数,基于关键词检索分数对所述每个分词后的文本块排名,并获取关键词检索分数最高的w个分词后的文本块;
40、汇总所述m个文本块和w个分词后的文本块得到t个文本块,其中t≤m+w;
41、基于所述m个文本块的排名和所述w个分词后的文本块的排名,采用倒数排序融合算法重新排序,确定与用户问题相关度最高的多个目标文本块。
42、可选的,所述相关度筛选模块中,计算每个文本块与所述用户问题之间的向量相似度,包括,
43、基于bge嵌入模型分别对所述用户问题和所述每个文本块进行向量表征,得到所述用户问题的嵌入向量,以及所述每个文本块的嵌入向量;
44、根据所述每个文本块的嵌入向量和所述用户问题的嵌入向量,结合向量相似度计算式,得到所述每个文本块与所述用户问题的向量相似度。
45、可选的,所述相关度筛选模块中,向量相似度计算式为:
46、
47、其中,d(a,b)表示文本块a与用户问题b之间的向量相似度;n表示用户问题b和文本块a的嵌入向量为n维向量;文本块a的嵌入向量为a=(a1,a2,…,ai,…,an);用户问题b的嵌入向量为b=(b1,b2,…,bi,…,bn)。
48、可选的,所述相关度筛选模块中,计算所述每个分词后的文本块与所述用户问题之间的关键词检索分数,包括:
49、将所述用户问题分词后得到多个关键词,针对每个关键词,获取所述关键词在每个分词后的文本块中的词频;
50、获取所述每个关键词的逆文档频率;
51、基于所述每个关键词的逆文档频率以及所述每个关键词在分词后文本块中的词频,结合bm25算法表达式,得到每个分词后的文本块与所述用户问题之间的关键词检索分数。
52、可选的,所述相关度筛选模块中bm25算法表达式为:
53、
54、其中,score(d,q)表示分词后的文本块d与用户问题q的关键词检索分数;qj表示用户问题q中的第j个关键词;α表示用户问题中关键词的数量;idf(qj)表示用户问题q中的第j个关键词的逆文档频率;f(qj,d)表示用户问题q中的第j个关键词在分词后的文本块d中的词频;k和β均表示可调参数,用于平衡词频影响;d|表示分词后的文本块d中的总词数;avgdl表示所有文本块的长度均值。
55、可选的,所述相关度筛选模块中,倒数排序融合算法的表达式为:
56、
57、其中,score表示文本块的倒数排序融合分数;c表示检索方式的总数,所述检索方式包括向量检索和关键词检索;g为常数,用于调节排名的影响力;rankh表示文本块在第h个检索方式中的排名。
58、可选的,所述答案生成模块中,采用大语言模型,基于所述多个目标文本块、用户问题以及预定义的prompt指令模板,生成所述用户问题的答案之后,还包括返回所述答案的所在文档来源。
59、与最接近的现有技术相比,本发明具有的有益效果如下:
60、本发明提供的一种基于大语言模型的多文档智能问答方法及系统,包括:将用电需求分析经验成果库中的每个文档分割为多个文本块,并对所述文本块进行分词得到分词后的文本块;根据用户问题对所述多个文本块进行向量检索,并基于分词后的用户问题对分词后的文本块进行关键词检索,得到与用户问题相关的多个目标文本块;采用大语言模型,基于所述多个目标文本块、用户问题以及预定义的prompt指令模板,生成所述用户问题的答案。本发明中获取电力分析经验数据库中的大量信息(即多个文档),通过对所述多个文本块进行向量检索,并基于分词后的用户问题对分词后的文本块进行关键词检索,能够确定出与用户问题匹配度较高的多个目标文本块,实现从大量信息中的高效检索,将检索到的匹配度较高的目标文本块输入大语言模型中,prompt指令模板将根据用户问题和目标文本块的关联性,将不同部分组织在一起,形成一个完整的问题描述,用于引导大语言模型回答问题,即通过大语言模型的分析和总结能力能实现用户问题的针对性的、精准的回答,有助于增强用户体验。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194158.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表