基于类间生成数据扩增的掌静脉特征提取网络训练方法
- 国知局
- 2024-07-31 22:42:12
本发明涉及生物特征识别,更具体地说,涉及一种基于类间生成数据扩增的掌静脉特征提取网络训练方法。
背景技术:
1、在当今数字化时代,身份认证技术是确保信息安全、防止未授权访问和保护个人隐私的关键。随着技术的发展和应用领域的扩展,传统的身份验证方法,如密码和pin码,由于易于被破解和伪造,越来越不能满足人们对高安全性的需求。因此,生物特征识别技术凭借其独一无二和难以复制的特点,成为了身份认证领域的研究热点。
2、掌静脉识别技术是目前一种先进的生物特征识别技术,其利用个体手掌内部的静脉图案进行身份验证,该技术的原理基于一种简单而又深刻的观察:每个人的掌静脉图案都是独一无二的,掌静脉图案取决于手掌中静脉的大小、形状以及它们在手掌中的分布情况,掌静脉识别技术通过分析这些图案来验证个人身份,相比与其他生物特征识别技术,掌静脉识别技术在准确性和稳定性方面表现出色,这得益于掌静脉图案的复杂性和独特性,以及其相对稳定的特性(不易因外界因素如伤疤或皮肤状况变化而改变),同时由于掌静脉图案位于体内,不易受到外部伤害或伪造,并且难以被外人观察到,掌静脉识别技术也具有较高的安全性。
3、目前最新的掌静脉识别技术主要通过利用深度学习网络来提取用户掌静脉特征,进而实现精准的身份认证,而深度学习网络的性能极大依赖于大量、高质量的训练数据。然而在目前的掌静脉识别技术的研究中,公开可用的掌静脉数据集在规模和多样性上都相对有限,限制了算法优化和性能提升的空间,并且由于涉及到隐私问题,公开数据集不能直接用于实际产品的开发和优化,此外掌静脉数据的采集过程是一项需要耗费大量时间和人力成本的工作,因此训练数据量不足是目前掌静脉识别技术研究中存在的重点问题,该问题限制了掌静脉识别技术在实践中的应用和发展。
技术实现思路
1、本发明的目的在于克服现有技术中的缺点与不足,提供一种基于类间生成数据扩增的掌静脉特征提取网络训练方法,该方法可解决掌静脉识别类间样本数据量不足的问题,实现提高掌静脉特征提取网络模型的泛化性能。
2、为了达到上述目的,本发明通过下述技术方案予以实现:一种基于类间生成数据扩增的掌静脉特征提取网络训练方法,其特征在于:包括以下步骤:
3、s1、采用真实掌静脉数据集训练得到掌静脉图像生成模型,同时采用真实掌静脉数据集训练得到预训练掌静脉征提取模型;
4、s2、采用预训练掌静脉征提取模型对真实掌静脉数据集中的所有样本进行特征提取,得到真实特征集;
5、使用在s1中训练完成的掌静脉图像生成模型生成掌静脉图像,得到掌静脉数据集;将掌静脉数据集通过预训练掌静脉征提取模型进行特征提取,得到特征集;
6、获取若干个与真实掌静脉数据集类别不同的掌静脉数据集样本,同时将类别不同的掌静脉数据集样本的特征加入到特征集中,得到具有若干个全新类别样本的生成掌静脉数据集,并且保存该类别不同的掌静脉数据集样本对应输入给掌静脉图像生成模型的风格隐向量;
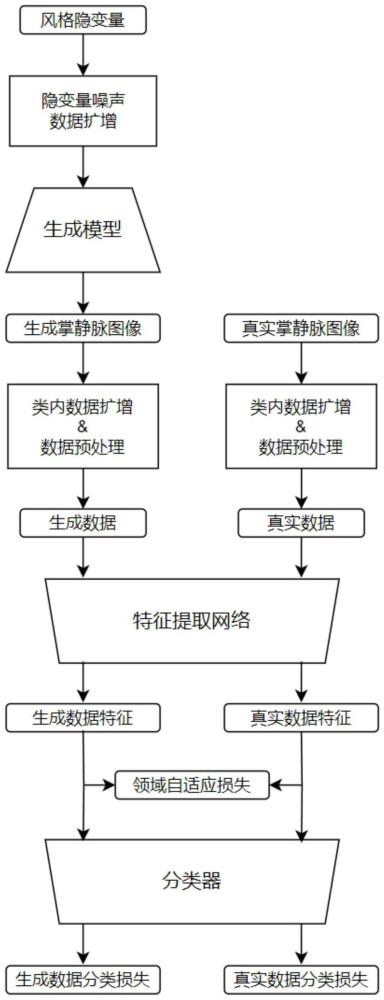
7、s3、建立掌静脉特征提取模型,同时对真实掌静脉数据集和在s2中得到的生成掌静脉数据集进行类内数据扩增变换和数据预处理,分别得到真实数据和生成数据;
8、采用领域自适应方法,同时用真实数据和生成数据对掌静脉特征提取模型进行训练,其中,掌静脉特征提取模型的损失函数包括分别在真实数据和生成数据上的分类损失以及领域自适应损失,最后得到训练完成的掌静脉特征提取模型。
9、步骤s1中,所述掌静脉图像生成模型采用stylegan2模型。
10、步骤s2包括以下步骤:
11、s21、采用预训练特掌静脉征提取模型对真实掌静脉训练数据集中的所有样本进行特征提取,得到真实特征集;
12、s22、不断重复以下过程直到生成样本达到目标数量:随机生成一个输入隐向量z,输入隐向量z通过stylegan2特征映射网络得到初始风格隐向量w,初始风格隐向量w输入掌静脉图像生成模型生成掌静脉图像,得到掌静脉数据;将掌静脉数据通过预训练掌静脉征提取模型进行特征提取,得到特征;
13、将特征在真实特征集中检索,如果该特征与最近真实特征的距离大于阈值,那么则认为该特征对应的掌静脉图像是一个全新的类别,同时将该特征加入到真实特征集中,并且保存生成该掌静脉图像的风格隐向量w;
14、s23、根据s22得到具有若干个全新类别样本的生成掌静脉数据集,并且保存该类别不同的掌静脉数据集样本对应输入给掌静脉图像生成模型的风格隐向量w。
15、步骤s3中,采用领域自适应方法,同时用真实数据和生成数据对掌静脉特征提取模型进行训练过程中,均设置完成迭代次数、批量大小和学习率,每一次迭代过程为:
16、s31、对真实掌静脉数据集经过一系列类内数据扩增变换和数据预处理,得到真实数据;
17、s32、对步骤s23的风格隐向量w添加随机微弱噪声实现类内数据扩增,将加噪后的风格隐向量代替步骤s22的初始风格隐向量w,作为掌静脉图像生成模型的输入;
18、对生成掌静脉数据集经过一系列类内数据扩增变换和数据预处理,得到生成数据;
19、s33、将真实数据和生成数据分别通过掌静脉特征提取模型得到真实数据特征和生成数据特征,计算二者之间的领域自适应损失;
20、s34、将真实数据特征和生成数据特征分别通过分类器计算真实数据分类损失和生成数据分类损失;
21、s35、通过领域自适应损失、真实数据分类损失和生成数据分类损失进行反向传播,更新梯度,得到训练完成的掌静脉特征提取模型。
22、对风格隐向量w添加随机微弱噪声的方式为:获取分布范围为(-1,1)且与风格隐向量w维度相同的噪声,然后将噪声乘以一个缩放因子,添加到风格隐向量w上。
23、真实掌静脉数据集和生成掌静脉数据集采用的类内数据扩增变换包括:随机透视变换、随机旋转、随机平移、尺度抖动和亮度抖动。
24、在每次训练迭代中,分别从真实掌静脉数据集和生成掌静脉数据集中采样相同数量的样本。具体通过两个批量样本采样器获取当前批次的批量数据,批量样本采样器能够在数据集内的样本都被采样一次后再开启新一轮的采样,从而保证每个样本被采样的次数几乎相同。
25、领域自适应损失采用多核最大均值差异计算得到,计算公式为:
26、
27、其中,n为样本批量的大小,和分别为批量中来自真实数据和生成数据的第i个样本,k为多个特征核函数的凸组合;
28、分类器由全连接层和dropout层构成,同时用于真实数据的分类器和生成数据的分类器是相互独立的,真实数据分类损失和生成数据分类损失均采用arcface损失函数计算得到,公式为:
29、
30、其中s,m为预设参数,θj为真实数据样本(xi,yi)特征向量或生成数据样本(xi,yi)特征向量与分类器中对应类别j权重向量的夹角。
31、最终总损失函数的计算公式为:
32、
33、本发明基于类间生成数据扩增的掌静脉特征提取网络训练方法,主要解决掌静脉识别类间样本数据量不足的问题,本发明通过利用生成模型生成全新身份的掌静脉图像,同时采用基于风格隐变量地数据扩增生成的全新类别有一定的类内多样性,并且能够结合常用的类内数据扩增技术进一步提升类内多样性,然后通过结合生成数据集和真实数据集对特征提取模型进行训练,以提高模型的泛化性能。另外由于生成数据集和真实数据集存在分布上差异,如果直接将生成数据集和真实数据集合并为一个数据集进行训练,会出现生成数据集污染高质量的真实数据集导致特征提取模型的性能反而下降的现象,本发明针对这个问题采用领域自适应方法训练框架进行解决。
34、与现有技术相比,本发明具有如下优点与有益效果:
35、1、本发明在采用生成模型生成全新掌静脉身份类间数据的基础上,采用风格隐变量加噪方式实现生成样本的类内数据扩增,同时结合常用的类内数据扩增进一步增加生成样本和真实样本的类内多样性,然后采用领域自适应方法同时在生成数据集和真实数据集上对特征提取网络进行训练,为针对掌静脉识别技术研究中数据量不足的问题提供一种新的类间数据扩增的解决方案。
36、2、本发明采用实时生成训练数据的方法,只需要预先保存类间样本的风格隐向量,同时采用基于风格隐变量的类内数据扩增,大幅降低了生成数据集占用的空间,同时增加了生成数据的类内多样性。
37、3、本发明能够在只使用类内数据扩增的基础上进一步提升掌静脉特征提取网络的泛化性能,同时本发明可以应用于任意的掌静脉特征提取网络。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194182.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表