数字孪生驱动的热处理炉炉温均匀性健康状态评估方法
- 国知局
- 2024-07-31 22:42:19
本发明属于数字孪生技术与设备故障预测健康管理,尤其涉及一种数字孪生驱动的热处理炉炉温均匀性健康状态评估方法。
背景技术:
1、目前,最接近的现有技术:基于模型的健康评估方法通过对具体对象的机理分析,构建其物理或数学模型,充分利用对象本身的物理规则,通过模型来评判设备的健康状态,但复杂工况条件下设备健康状态评估模型构建及验证困难,需根据实际工况条件对模型进行调整及验证,且时间成本高;基于数据驱动的设备健康评估方法指通过机器学习、深度学习等人工智能技术手段,学习设备历史数据集,发现潜在的设备状态趋势和退化规律,从而训练好一个参数范围固定的复杂模型进行设备健康评估的方法,但是,训练好的模型鲁棒性较差,需要结合领域知识进行有效的特征提取以提升模型的抗噪能力和泛化能力。模型驱动和数据驱动的设备健康评估方法因其自身存在的局限性,利用单一方法对设备进行智能分析时效果不佳。
2、目前构建健康指标的方法可分为两种,一种是基于物理特性的健康指标,一种是基于虚拟的健康指标。物理健康指标与设备退化的物理特性相关,通常采用统计方法和信号处理方法来提取设备健康指标,如振动信号的均方根值,除均方根值外,信号的时域统计特性也能表征设备的劣化程度。虚拟健康指标通常通过融合多个传感器信号并利用相关数据挖掘算法进行构建,用以描述设备退化趋势,因此不具备物理意义。在构建虚拟健康指标的方法中,主成分分析作为一种常见的降维技术,被广泛应用于虚拟健康指标构建。
3、综合上述研究现状及成果,对设备进行健康状态评估方面已经有了诸多成果,并在各个领域得到了广泛的应用。
4、综上所述,现有技术存在的问题是:热处理炉健康状态指标的变化是一种多因素耦合的复杂性能退化现象,其变化趋势表现出一定的不确定性和随机性,因此利用单一学习器对热处理炉进行退化特征提取时,所提取出的特征并不具备所需的泛化能力,在设备运行条件复杂多变的条件下会引起较大误差,训练好的模型鲁棒性差。
5、解决上述技术问题的难度:摆脱专家经验和人为因素的束缚,使算法模型所提取的特征具备所需的泛化能力和抗噪能力,提升模型的鲁棒性,并且能够适用于各种复杂场景。
6、解决上述技术问题的意义:现有技术应用性不广泛,热处理炉健康状态指标的变化趋势呈现的不确定性和随机性难以把握,对于特征提取方面还需改进,现有的设备分析方法仍集中在使用运行监测数据上,对设备本身运行机理及物理特性的结合相对较少,而数字孪生技术的发展可有效克服数据与机理融合不充分的问题,为设备智能高效分析提供了新的解决思路。本发明旨在提出一种基于sae-som的自适应特征提取方法。
技术实现思路
1、针对现有技术存在的问题,本发明提供了一种数字孪生驱动的热处理炉炉温均匀性健康状态评估方法。
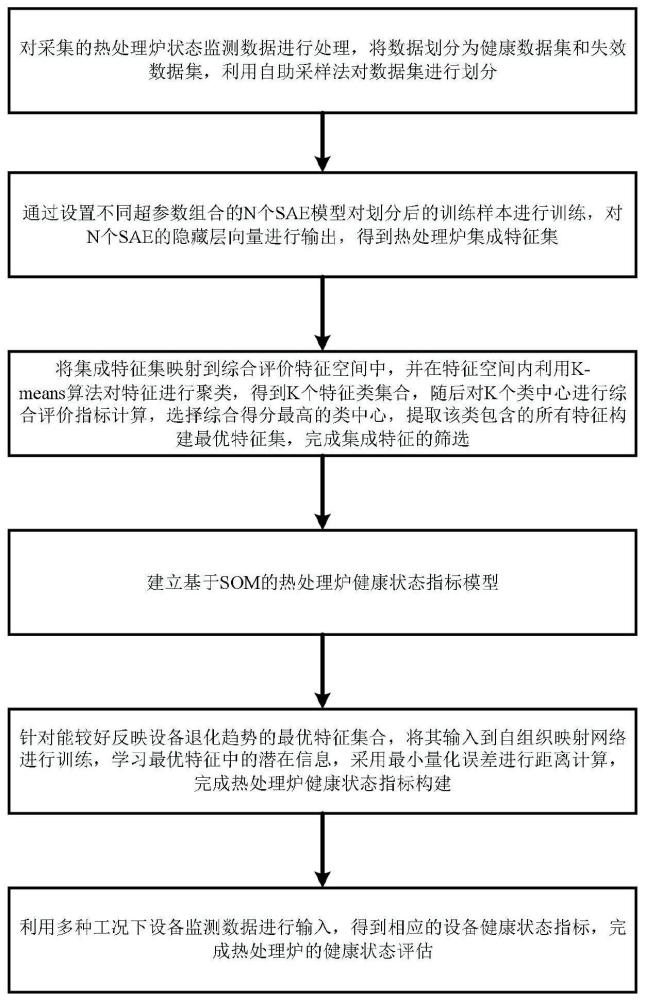
2、本发明是这样实现的,一种数字孪生驱动的热处理炉炉温均匀性健康状态评估方法,所述基于数字孪生驱动的热处理炉炉温均匀性健康状态评估方法包括:
3、第一步,获取热处理炉状态监测数据,利用自助采样法对数据集进行划分,设置不同超参数组合的n个sae模型对划分后的样本进行训练,对n个sae的隐藏层向量进行输出,得到热处理炉性能退化特征集成;
4、第二步,将集成特征集映射到综合评价特征空间中,在特征空间内利用k-means算法对特征进行聚类,得到k个特征类集合,对k个类中心进行综合评价指标计算,选择综合得分最高的类中心,提取该类包含的所有特征构建最优特征集,完成集成特征的筛选;
5、第三步,构建基于集成sae-som的设备健康状态指标模型,将能较好反映设备退化趋势的最优特征集合作为输入向量,利用自组织映射网络进行训练,学习最优特征中的潜在信息,采用最小量化误差进行距离计算,完成热处理炉健康状态指标构建;
6、第四步,利用构建的热处理炉健康状态指标模型,在多种工况下设备监测数据进行输入,得到相应的设备健康状态指标,完成热处理炉的健康状态评估。
7、进一步,所述第一步中基于集成sae的热处理炉性能退化指标提取包括以下步骤:
8、(1)采集热处理炉数据监测数据并进行数据预处理,随后将数据划分为健康数据集和失效数据集;
9、(2)利用自助采样法对设备健康数据集进行n次随机采样,采样比例设置为0.7,获得训练样本1~n,此时训练样本之间各自存在差异性,有利于进行差异化基学习器训练;
10、(3)以不同的超参数设置n个栈式自动编码器,并进行权重随机初始化,随后利用训练集1~n对sae-1~n进行训练,每个sae的隐藏层向量作为输出特征;
11、(4)特征筛选与集成:计算各个退化指标的单调性、相关性、鲁棒性,根据综合评价指标实现特征筛选,从而实现热处理炉性能退化特征集成。
12、进一步,所述第二步中用k-means对集成特征进行聚类筛选包括以下步骤:
13、(1)随机选择k个特征作为聚类中心;
14、(2)对特征集d内所有数据,计算其与各个聚类中心的距离,按照就近原则将特征划分到最近的聚类中心类别;
15、(3)特征集分类完成后,对每个类别进行聚类中心计算,并进行聚类中心更新替换;
16、(4)重复步骤(2)和(3),直至聚类中心不再改变,则完成集成特征的聚类;
17、(5)利用k-means进行特征集进行聚类后得到k个聚类中心,此时根据加权融合的方法进行聚类中心综合评价指标计算,计算方法如下:
18、score=w1·mon+w2·corr+w3·rob
19、式中,w1、w2、w3分别表示单调性、相关性、鲁棒性所对应的权重,mon表示单调性、corr表示相关性、rob表示鲁棒性、score为聚类中心对应的得分,通过计算k个聚类中心的分数,选择最高得分聚类中心及其所包含的类特征作为最终提取的特征,从而完成退化特征的筛选。该算法达到的技术效果是能够对热处理炉服役性能潜在退化模式进行分类,从而提取热处理炉相应的退化信息。
20、进一步,所述第三步中利用自组织映射网络进行训练学习步骤如下:
21、(1)初始化输入层与映射层之间的权值。
22、(2)将数据输入到som的输入层。
23、(3)随机选择一个输入向量为x=(x1,x2,…,xn)t,计算该向量与映射层神经元之间的欧氏距离,计算公式如下:
24、
25、式中,wij表示输入层第i个神经元与映射层第j个神经元之间的权重。
26、(4)选择计算后欧氏距离最小的神经元,记该神经元为n,则映射层与输入向量之间的最短距离为dn,此时找出所有与该神经元相邻的神经元并给出集合。
27、(5)将获胜神经元n与其相邻神经元之间的权值进行更新,具体更新公式如下:
28、δwij=ηh(j,n)(xi-wij)
29、
30、式中,η为常数,η∈(0,1),而σ2会随着迭代次数的增加而逐渐减小,因此som进行更新时随着迭代次数的增加,权值从大范围调整至小范围微调,最后判断误差或迭代次数是否达到指定值,如果达到则训练结束,否则返回第二步进行反复训练。
31、(6)利用多次特征样本输入进行输入与获胜神经元n之间的距离计算,此时该距离为最小量化误差,记为dmqe,公式如下:
32、dmqe=||x-wn||
33、式中,wn为获胜单元的权值向量。
34、经计算后最小量化误差通常会伴有一部分噪声毛刺,因此可通过进行相应的平滑处理后作为设备健康状态指标。该算法达到的技术效果为能够学习最优特征中的潜在信息,采用最小量化误差进行距离计算,完成热处理炉健康状态指标构建。
35、进一步,所述第四步中热处理炉健康状态评估包括:利用构建的热处理炉健康状态指标模型,在多种工况下设备监测数据进行输入,得到相应的设备健康状态指标,完成热处理炉的健康状态评估。
36、本发明的另一目的在于提供一种应用所述数字孪生驱动的热处理炉炉温均匀性健康状态评估方法的热处理炉健康状态评估系统。
37、本发明的另一目的在于提供一种应用所述数字孪生驱动的热处理炉炉温均匀性健康状态评估方法的状态评估终端。
38、综上所述,本发明的优点及积极效果为:本发明通过集成sae完成设备深度集成特征提取,构成设备深度集成特征集,并通过评价特征的单调性、相关性和鲁棒性,借由k-means聚类筛选得分最高的最优特征集,从而完成特征筛选与提取,利用自组织映射网络,训练学习设备健康数据集中的潜在信息,并用设备最优特征集进行输入,以最小量化误差为输出,得到故障数据与正常运行数据在特征空间内的距离,构建热处理炉健康状态指标,从而完成热处理炉健康状态评估,不仅有效的提升了模型的预测能力,也使模型的应用范围更加广泛,经过调整可以广泛应用于各种热处理炉的健康预测上。通过上述三种方法的结合,能充分发挥各自的独特作用,实现单个神经网络不能实现的效果,单个神经网络需要的数据量大,常用于解决分类问题,在解决此类问题的时候会存在过拟合现象而导致泛化能力不强;本发明在特征层面先利用集成学习的思想,通过设置不同超参数组合的n个sae模型对划分后的训练样本进行训练,同时满足集成学习中样本和基学习器的差异性,有利于提升集成特征的鲁棒性,对n个sae的隐藏层向量进行输出,得到热处理炉集成特征集,将集成特征集映射到综合评价特征空间中,并在特征空间内利用k-means算法对特征进行聚类,选择综合得分最高的类中心,提取该类包含的所有特征构建最优特征集,完成集成特征的筛选,再利用自组织映射网络进行训练,从而学习最优特征中的潜在信息,随后采用最小量化误差进行距离计算,完成热处理炉健康状态指标构建;特点是在设备运行条件复杂多变的条件下避免较大的误差,通过训练多个基学习器,将设备退化的复杂状况分解为多个角度的退化特征提取,相较于单一学习器而言,提升了集成特征的鲁棒性,实现所需的泛化能力。
39、与现有技术与方法对比,本发明具有以下优势:
40、第一,本发明提出的数字孪生驱动的热处理炉炉温均匀性健康状态评估方法有机结合了sae、k-means和som三种算法,充分发挥了各自的优势。相比于单种算法或网络,本发明具有更强的特征提取和筛选能力,能充分挖掘输入数据中的特征,提高模型的预测能力。
41、本发明考虑到了热处理炉健康状态指标的变化趋势的不确定性和随机性,利用集成学习训练多个基学习器,将设备退化的复杂状况分解为多个角度的退化特征提取,据此构建的设备退化特征库将具备更强的鲁棒性;在设备健康状态指标构建方法中,充分发挥了自组织映射网络的灵活多变,能较好适用于各种复杂场景,能广泛应用到各种热处理炉的健康状态预测中。在热处理炉的健康状态预测领域,本发明首次提出由k-means和sae-som神经网络处理加工数据、特征提取筛选的方法,本发明具有较强的创新型和实用性。
42、第二,本发明实施例提供的基于数字孪生驱动的热处理炉炉温均匀性健康状态评估方法,解决了现有技术在热处理炉健康状态评估方面存在的几个关键问题,并实现了显著的技术进步。
43、首先,本发明解决了热处理炉状态监测数据的复杂性和不确定性问题。通过对采集的数据进行预处理,划分健康数据集和失效数据集,并利用自助采样法对数据集进行划分,提高了数据的可靠性和有效性。这一步骤为后续的特征提取和模型训练提供了高质量的数据基础。
44、其次,本发明通过集成多个具有不同超参数组合的sae模型,提取了热处理炉的集成特征集。这种方法克服了单一模型存在的局限性,提高了特征提取的准确性和鲁棒性。同时,利用k-means算法对特征进行聚类,选择综合得分最高的类中心构建最优特征集,进一步筛选出了对热处理炉健康状态评估最具代表性的特征。
45、再次,本发明建立了基于som的热处理炉健康状态指标模型。通过自组织映射网络学习最优特征中的潜在信息,并采用最小量化误差进行距离计算,构建了能够反映设备退化趋势的健康状态指标。这一模型不仅具有较强的泛化能力,还能够适应多种工况下的设备监测数据,提高了热处理炉健康状态评估的准确性和可靠性。
46、最后,本发明的方法在热处理炉健康状态评估方面实现了显著的技术进步。通过对热处理炉的集成特征进行筛选和优化,提高了特征提取的效率和质量;同时,利用som模型构建了具有实际应用价值的健康状态指标,为热处理炉的维护和管理提供了有力的技术支持。
47、本发明实施例提供的基于数字孪生驱动的热处理炉炉温均匀性健康状态评估方法,在数据处理、特征提取、模型构建和实际应用等方面均取得了显著的技术进步,为热处理炉的健康状态评估提供了一种新的有效方法。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194190.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表