一种基于细粒度语义和双塔模型的NFT关联舆情判定方法
- 国知局
- 2024-07-31 22:43:58
本发明属于本发明涉及舆情分析,尤其涉及一种基于细粒度语义和双塔模型的nft关联舆情判定方法。
背景技术:
1、nft(non-fungible token)是存储在区块链上数字资产,随着web3.0的发展,越来越多的去中心化应用受到人们关注,nft的表现形式也层出不穷。多条公链ethereum、polygon上的nft以图片、视频、音乐等多元表现形式依托区块链智能合约创建,并通过区块链交易。nft交易市场与社交媒体之间存在着紧密的联系。nft交易本质是一项链上交易活动,但是通常伴随着活跃的链下社交媒体活动。nft发行方通过社交媒体平台宣传其nft作品,社交媒体用户在舆情发展下能够助推nft热度,扩大其影响力。nft兼具有资产属性和内容属性。借助社交媒体舆情态势,nft市场也暗藏着资产炒作风险。与此同时,nft继承了区块链去中心化、数据不可篡改、交易隐私保护的特性,不少未经审核的nft内容在社交媒体上的传播将造成较大舆情风险。
2、在传统的文本关键词检索中,理解词语的分词语义信息相对困难。在与nft相关的社交媒体推文数据流中,口语宣传表达和大量缩略写法给关键词检索带来了巨大的挑战。与此同时,社交媒体上的推文可能采用来自nft基本信息的某几个分词组合来重新指代该nft。为了准确并及时定位nft在社交媒体上的对应表现,促进nft链下活动的可靠监管,亟需提出一种解决nft链下活动的安全性以及监控nft舆情风险技术问题的方法。
技术实现思路
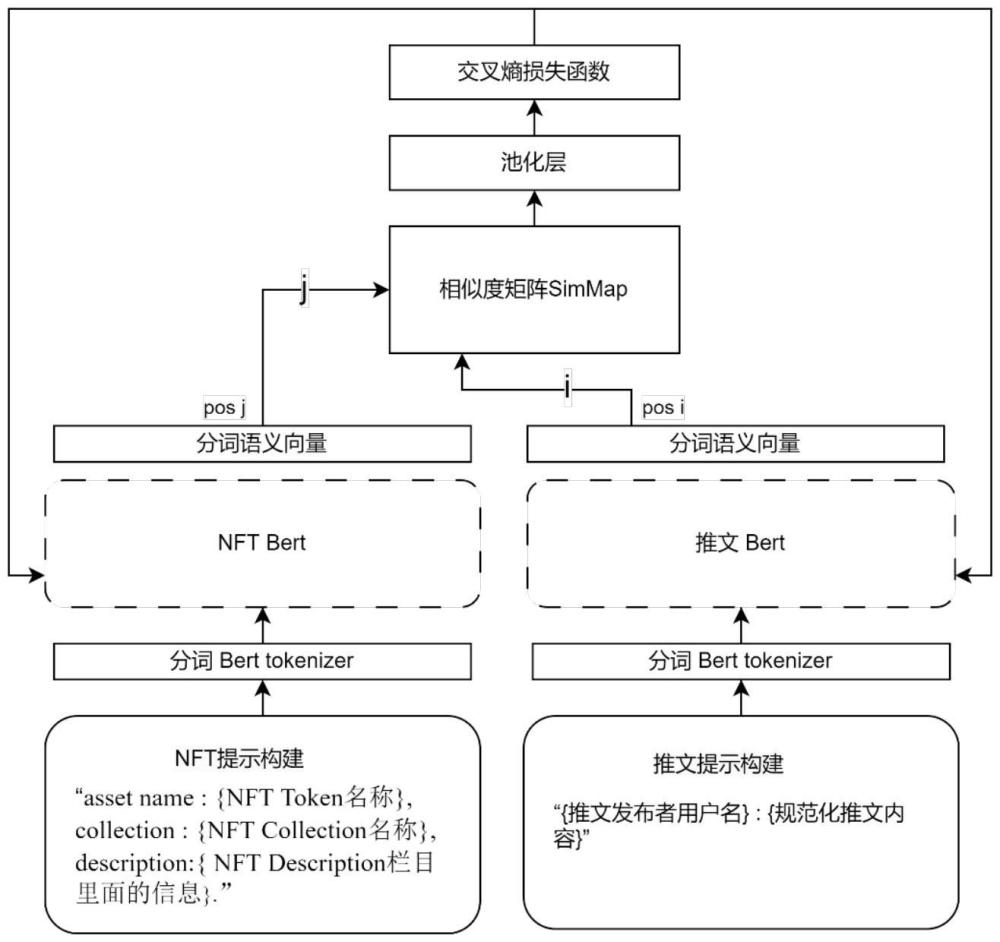
1、针对现有技术的不足,本发明提出了一种基于双塔模型的nft关联舆情发现方法。该方法针对输入的nft基本信息,以及社交媒体上推文发布者的用户名、推文内容等文本信息,基于bert(bidirectional encoder representation from transformers)双塔模型提取各文本分词在序列中的细粒度语义并在双塔间进行分词级别的相似度度量,输出推文与nft是否关联的判断,从而确定nft的关联舆情。
2、一种基于细粒度语义和双塔模型的nft关联舆情判定方法,包括以下步骤:
3、(1)获取推文数据并规范化推文内容,构建推文提示句和nft提示句;
4、(2)利用bert预训练分词器对推文提示句和nft提示句进行分词,并对分别得到词序列添加标签;
5、(3)构建bert双塔模型,即推文bert和nft bert;将步骤(2)分别得到词序列输入推文bert和nft bert中,分别得到词序列的分词表示;
6、(4)构建bert双塔模型的细粒度语义度量模块,并聚合所有双塔模型交互阶段结果,构造得到分词语义级别的相似度矩阵并对其池化;
7、(5)将推文提示句的两种二元样本组合进入双塔模型训练,并使使用sigmoid函数将池化结果映射到(0,1)区间内,采用交叉熵损失函数优化模型损失完成对模型的调整。
8、进一步地,所述步骤(1)包括如下子步骤:
9、(1.1)通过爬虫或api获取社交媒体上推文数据,文字内容包含推文内容、推文发布者用户名;
10、(2.2)规范化推文内容,处理推文内容中的非英文字符,将所有字母转换为小写,替换外部链接为httpurl,保留以@符号开头的用户名,@和用户名之前使用空格隔开;以#符号开头的主题标签,#和主题之间使用空格隔开;对于推文中的标点符号将它们作为独立的单词;
11、(3.3)构建推文提示句,格式为“{推文发布者用户名}:{规范化推文内容}”;
12、(3.4)构建nft提示句,格式为“asset name:{nft token名称},collection:{nftcollection名称},description:{nft description栏目里面的信息}”。
13、进一步地,所述步骤(2)包括如下子步骤:
14、(2.1)针对每一对推文提示句st和nft提示句sn,使用bert预训练分词器berttokenizer进行分词,分别得到词序列vt,vn,其中vt的长度为256,vn的长度为32,超出部分将进行截断处理,不足部分将进行填充处理;
15、(2.2)分别在词序列vn、vt的首部添加[cls]标签,以便于模型学习到句子的整体语义,表示为:
16、vt={[cls],t1,t2,…,t255};
17、vn={[cls],n1,n2,…,n31}。
18、进一步地,所述步骤(3)包括如下子步骤:
19、(3.3)构建bert双塔模型,分别记作推文bert和nft bert,使用bert预训练模型的参数进行初始化;
20、(3.4)将vt,vn分别输入到bert双塔模型的推文bert和nft bert中,每一个分词标签都将对应一个特征表示,最终得到词序列的分词表示表示为:
21、pt={pt[cls],pt1,pt2,...,pt255};
22、pn={pn[cls],pn1,pn2,...,pn31}。
23、进一步地,所述步骤(4)包括如下子步骤:
24、(4.1)构建bert双塔模型的细粒度语义度量模块,实现nft信息和推文信息每一个分词细粒度语义级别的交互simi,j;
25、
26、(4.2)聚合所有双塔模型交互阶段结果构造得到分词语义级别的相似度矩阵
27、(4.3)构建adaptiveavgpool2d池化层,将simmap相似度矩阵数据池化到
28、具体地,所述步骤(4)中双塔模型交互阶段,若对分词对应的语义向量再进行一次全连接层计算;针对推文bert每一个分词pti,通过在nftbert中最相似的分词语义向量pnj,将它们的相似度simi,j作为该推文分词的得分,最终计算所有分词得分的加和表示该推文和nft的关联程度;也能够单独使用推文bert和nftbert的[cls]对应语义向量的比较,代表两句提示句从句子语义级别的相似度,也代表nft和推文的关联程度。
29、进一步地,所述步骤(5)包括如下子步骤:
30、(5.1)针对每一个推文提示句st,在训练样本筛选过程中选择一个关联nft提示句sn+和一个非关联nft提示句sn-;因此,训练过程中每一个推文提示句st,有两种二元样本组合<st,sn+>,<st,sn->能够进入双塔模型训练,实现样本正负例平衡;
31、(5.2)使用sigmoid函数将双塔模型交互阶段输出的池化结果p映射到(0,1)区间内,p′=sigmoid(p);其中p′代表由模型计算出的推文提示句st和nft提示句sn的关联程度;
32、(5.3)y∈{0,1}代表真实状况下的标签,代表推文提示句st和nft提示句sn是否关联,采用交叉熵损失函数优化模型损失:
33、loss(p′)=-y(1-p′)log(p′)-(1-y)p′log(1-p′)。
34、本发明还提供了一种基于细粒度语义和双塔模型的nft关联舆情判定装置,包括以下模块:
35、构建模块:获取推文数据并规范化推文内容,构建推文提示句和nft提示句;
36、加标签模块:利用bert预训练分词器对推文提示句和nft提示句进行分词,并对分别得到词序列添加标签;
37、输入模块:构建bert双塔模型,即推文bert和nft bert;将加标签模块分别得到词序列输入推文bert和nft bert中,分别得到词序列的分词表示;
38、构造池化模块:构建bert双塔模型的细粒度语义度量模块,并聚合所有双塔模型交互阶段结果,构造得到分词语义级别的相似度矩阵并对其池化;
39、优化调整模块:将推文提示句的两种二元样本组合进入双塔模型训练,并使使用sigmoid函数将池化结果映射到(0,1)区间内,采用交叉熵损失函数优化模型损失完成对模型的调整。
40、本发明又提供了一种电子设备,包括:
41、一个或多个处理器;
42、存储器,用于存储一个或多个程序;
43、当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现所述的基于细粒度语义和双塔模型的nft关联舆情判定方法。
44、以及一种计算机可读存储介质,其上存储有计算机指令,该指令被处理器执行时实现所述基于细粒度语义和双塔模型的nft关联舆情判定方法的步骤。
45、本发明的有益效果如下:
46、1.从bert文本分词的细粒度语义入手,契合nft关联舆情的特点(缩略、简写词汇较多),通过添加[cls]分词标签,利用双塔模型从分词语义级别进行两两交互,融合了分词的局部语义和全局语义信息,构建分词语义级别的相似度矩阵,实现nft关联舆情的判定。
47、2.提示句构建额外考虑了潜在的带有语义信息的文本,包括nft description、推文发布者账户用户名。双塔模型的架构减少了自注意力机制带来的计算量,比起单一bert输入nft和推文提示句两个句子的拼接,双塔模型能够处理更长的推文,解耦推文数据源和nft数据源,更适合模型在线上实时运行。
48、由上述实施例可知,本技术
49、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本技术。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194350.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表