数据闭环中基于自动驾驶世界模型的数据价值挖掘方法与流程
- 国知局
- 2024-07-31 22:43:56
本发明属于自动驾驶,具体为数据闭环中基于自动驾驶世界模型的数据价值挖掘方法。
背景技术:
1、随着人工智能模型能力的迅猛发展和其在自动驾驶场景中的应用,如何高效的迭代自动驾驶模型一直是关注重点。由于自动驾驶系统对生产环境算法稳定性及安全性的高要求以及当前自动驾驶模型整体的优异表现能力,通过筛选高质量的数据对模型进行迭代已经被验证是最高效的迭代方法。然而,由于自动驾驶数据集中场景分布的不同,模型往往更关注于常见场景的表现,导致模型应对罕见场景时表现不如预期,甚至会引发危险。因此,如何找到大量数据中的罕见场景并应用于模型迭代就成为了模型迭代的瓶颈。随着通用生成式模型的发展以及对世界模型的探讨,自动驾驶领域的众多研究者也开发了针对自动驾驶场景的世界模型,它旨在利用对过去的观测,对环境进行建模,并利用生成式模型的技术生成将来可能的环境,并给出相应的行动指导。该功能的实现证明世界模型对整体环境有着远高于传统感知模型的深刻理解,并具备了场景的生成能力,因此具备了罕见场景难例发现的潜力。
2、与该方案最接近的方案为论文《towards corner case detection forautonomous driving》中提到的方案,该方案在离线环境下,通过对图像进行语义分割以及利用一个图像预测模型预测未来时刻的图像数据,综合模型生成结果和真值,计算数据分数。该方法使用语义分割算法为每一个像素提供标签,同时利用基于lstm的自编码器,参考历史数据生成未来的图像。在离线场景下,比对生成的图像与真实图像之间的误差,同时利用语义分割的结果提取与驾驶任务相关的像素位置,赋予相关位置更高的权重,最终,通过加权平均计算得出该图像的价值分数。
3、但是现有技术存在以下缺点:
4、语义分割的泛化性能:已有方案使用的语义分割模型为deeplabv3,2016年出品,模型年代较早,且使用的训练数据集为pascalvoc 2012,共1000多张图片,数据量较小,与自动驾驶场景相关性不高,模型泛化性能不足。
5、图像生成模型的建模能力:已有方案使用的图像生成模型为一个由纯卷积模块构造的自动编码器网络。卷积模块作为局部的特征提取器,会更加关注于图像的纹理信息颜色信息等,而无法关注图像的全局信息,导致卷积模块对图像内所呈现的空间建模能力不足;同时生成图像的任务需要以历史图像为参考,而注重于局部信息的卷积也无法提供强大的时间信息建模能力
6、生成的数据可控性差:已有方案使用的图像生成网络只使用历史帧这一个单一引导作为生成的输入,缺乏可控性,并未考虑驾驶场景所提供的补充信息:如道路结构,自车运动参数等,导致生成的数据难以进行准确控制
7、缺乏3d信息:真实的驾驶场景是在3d世界进行的,因此当评判数据价值时与应该引入3d信息作为一个重要的距离权重(相比于远距离物体,近距离的物体更应该被优先考虑),然而,提供定位信息的语义分割模型仅仅可以提供像素坐标的2d信息,缺乏真实的3d信息。
技术实现思路
1、本发明的目的在于:为了解决上述提出的问题,提供数据闭环中基于自动驾驶世界模型的数据价值挖掘方法。
2、本发明采用的技术方案如下:数据闭环中基于自动驾驶世界模型的数据价值挖掘方法,所述方法包括以下步骤:
3、s1:对输入的历史图像进行目标检测,这个模块将输出图像范围内物体的3d框;
4、s2:在世界模型生成图像时,编码的3d框信息可以提供当前帧下物体几个位置以及类别信息;
5、s3:对输入的历史图像进行矢量化建图可以生成路面的道路信息,它将图像包含的道路信息编码为3d空间下的一个二个坐标,这部分信息同样也会经过一个编码器被编码至世界模型的输入向量空间;
6、s4:对输入图像同样需要将其编码至世界模型输入的向量空间,因此,需要一个合适的编码器。vq-vae是目前图像生成领域的先进架构,它是自编码器的变体,它将图像编码为离散的向量集合,然后通过一个神经网络生成图像;
7、s5:将文本信息作为额外的模态输入输入至世界模型当中,文本作为极度精炼的信息可以在少量输入的情况下提供大量背景知识,之后对文本信息做嵌入将文字提示与图像对齐;
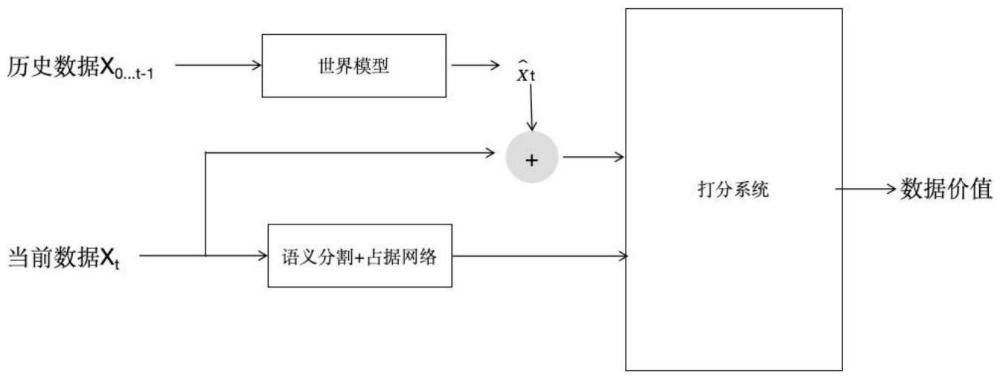
8、s6:在离线的场景下,系统除了拥有世界模型生成的图像,还可以获取当前时刻的真实图像,将二者相减即可获得t时刻下像素级别的预测误差
9、et=xt-x_hat t
10、et将作为打分系统的输入之一在后文被使用;
11、s7:通过对t时刻的图像做2d语义分割获取像素分类信息;
12、s8:进行3d占用预测,通过图像输入,预测当前状态下的体素表达和每个体素的类别;
13、s9:系统同时获得了2d像素的类别以及3d体素的类别,将两个结果进行融合,通过传感器之间的外参以及相机内参,通过光线追踪算法获取像素以及体素之间的对应关系,当像素及对应体素类别不同时,选择置信度更高的类别,并将体素坐标赋值给与其对应的像素点上,从而实现了2d和3d信息的融合;
14、s10:将与驾驶无关的像素类别(如图中的sky,ground等)所对应的生成误差设为0,确保最终升成的数据价值仅与会影响到驾驶的物体有关,
15、其次,通过3d坐标计算有关类别所对应的像素距离原点的欧式距离d,将欧式距离通过min-max归一化方法将其归一化至0-1的范围内作为距离权重。对于每一个像素的距离d,其对应的权重为
16、
17、再将权重赋给生成图像的误差et,并最终计算t时刻的数据价值δ
18、
19、s11:对于离线场景的连续帧数据,当计算获得每一个时刻的δ之后,就可以通过min-max归一化的方法,将所有时刻的数据价值归一化到0-1的区间之内,并根据人为设定的阈值,挑选最有价值的数据,并对数据进行记录保存,即可结束整个数据闭环中基于自动驾驶世界模型的数据价值挖掘流程。
20、在一优选的实施方式中,所述步骤s1中,3d框信息包含物体中心点坐标,物体的长宽以及朝向角,以及物体的类别。3d框包含了丰富的物体级别几何信息。
21、在一优选的实施方式中,所述步骤s2中,世界模型可以参考3d框的先验信息,从而确保生成的数据与历史真实数据中所包含的物体信息的一致性。
22、在一优选的实施方式中,所述步骤s3中,世界模型在生成未来图像时,可以参考经过提炼的道路信息的输入,从而确保生成图像的道路结构的一致性,增加生成数据的质量与真实性。
23、在一优选的实施方式中,所述步骤s4中,vq-vae所编码的离散的向量集合中,所包含的图像原始信息是十分丰富的。参考vq-vae的图像编码器对输入图像进行编码,并映射至世界模型的输入向量空间,这部分内容将作为世界模型生成未来图像时的重要参考。
24、在一优选的实施方式中,所述步骤s5中,clip是一个视觉-语言预训练模型,它通过对比学习的训练设置,建立了一种图像与文本之间的关联性,并通过对图像和文本之间相似性的度量,来实现它们之间更好地相互理解。使用clip所提供的文本编码器,即可将文本编码至相似图像的向量空间,从而实现了文本与图像之间的对齐,输入至世界模型当中。
25、在一优选的实施方式中,所述步骤s5中,世界模型的内部设置有生成式模型。生成式模型采用扩散模型的u-net基本结构,对于一个普通的扩散模型,它包含前向过程和反向过程,在前向过程中缓慢并且顺序地向样本中添加随机噪声,然后在反向过程中学习参数并拟合噪声,从噪声中恢复样本。对于本发明中所采用的扩散模型,除了常规的图像和文本输入外,还有3d框以及道路信息的输入。为了让模型在生成过程中综合考量全部的输入信息,在常规的扩散过程中加入多个注意力机制:时序注意力,自注意力以及交叉注意力。时序注意力可以让模型学习到时序前后一致性的相关信息,自注意力则可以训练模型自行选择关注的重点,而交叉注意力则可以融合多个输入信息,并让模型自行学习重要的部分。注意力的引入大幅度增强了模型对于多个输入信息的理解能力,从而模型学习每个输入。
26、在一优选的实施方式中,所述步骤s7中,选择目前性能较为先进的internimage-h模型,这是一个基于多任务学习的通用视觉大模型,多任务学习的核心思想是通过共享模型参数来学习多个相关任务。相比于传统的单任务学习中为每个任务单独训练一个模型的方法,多任务学习使用一个模型同时训练多个任务的数据,共享一部分或全部的模型参数。这样一来,不同任务之间可以通过共享的参数相互影响,这种共享和传递可以使得模型能够更好地适应不同的任务。以此提升在不同数据和任务上的泛化性能。通过使用先进的模型对图像做语义分割,保证语义分割的准确性,获取各个像素的类别信息。
27、在一优选的实施方式中,所述步骤s8中,3d占用预测可以提供3d空间下每个体素的位置信息,从而为视觉感知提供更全面的理解。使用fb-occ作为3d占用预测网络模型,该模型结合两种不同的方法初始化体素空间,并将两部分的特征进行融合,使网络对于3d空间有更好的精细化描述;在最后,作者利用了多尺度的预测融合的预测方式,来设计占据检测头。该网络还在深度估计和2d语义分割联合任务中进行预训练,以提升预训练模型感知能力的效果。
28、在一优选的实施方式中,所述步骤s9中,具体步骤包括:
29、1.通过雷达-相机间外参将雷达坐标系下的3d体素转至相机坐标系;
30、2.从相机原点发出射线,在射线上找到与之相交的第一个体素,利用相机内参将体素投影到成像平面上,构建像素与3d体素的对应关系;
31、3.若二者类别不同,则选择置信度分数更高的结果作为类别,通过上述方法,获取t时刻图像的像素级别分类结果以及像素对应的3d坐标,输入至打分系统中。
32、综上所述,由于采用了上述技术方案,本发明的有益效果是:
33、1、本发明中,利用了传统感知算法的分类定位能力以及新兴自动驾驶世界模型的环境建模能力,构建了一种全新的无需人为标注的数据打分及难例发现系统;在世界模型生成未来场景的过程中添加道路信息、物体信息、文字说明等多个模态的输入,增加了生成数据的可控性、前后一致性;分析图像时,同时参考了2d语义分割和3d占用预测的结果,实现了3d空间向2d图像的对齐,在图像维度补充了3d坐标信息;最终的打分系统中,参考了世界模型生成的结果的同时,以语义分割结果为权重进行最终打分,从而提高了整体过程的精确高效性。
34、2、本发明中,使用自动驾驶世界模型的图像生成模块作为生成器,模型能力远大于传统的生成模型;在生成过程中引入其它模态信息并进行空间对齐,保证了生成的质量和可控性,更加确保了最终的打分只受数据本身影响而不受模型能力的影响;使用语义分割对图像进行分析的时候参考了3d占据网络的结果,为每个像素点赋予更可信的类别以及对应的3d坐标,丰富了图像理解的维度,增加了结果的可信性;在最终打分的过程中,以像素点对应物体与原点的距离为误差添加权重,增加了打分的客观性,使打分有选择的更倾向于近处物体,排除了远处物体带来的误差。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194347.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表