用于代码分析的对话式GPT数据处理方法及系统与流程
- 国知局
- 2024-07-31 22:44:25
本发明涉及数据处理,尤其涉及一种用于代码分析的对话式gpt数据处理方法及系统。
背景技术:
1、对话式gpt(generative pre-trained transformer,生成式预训练转换器),如openai公司的chatgpt或谷歌公司的grad等产品,其兴起引发了大量技术人员的关注,这类技术能够为用户提供可视化的对话界面,并根据用户的输入来生成相应的回答,给予了用户智能化的使用体验。目前的对话式gpt技术通过对llm模型的充分训练,已经逐渐具备了代码处理方面的功能,部分技术人员发现对话式gpt模型能够在一定程度上满足用户的代码反编译分析需求,可以用于代码反编译研究或是代码安全测试等场景,但现有技术中对话式gpt仍然需要用户的明确指示才能有效执行反编译代码的任务,其缺乏主动识别和预测用户需求的能力,其代码反编译结果也往往不够精确,无法充分测试代码的安全性,满足测试人员或研究人员的需求。可见,现有技术存在缺陷,亟待解决。
技术实现思路
1、本发明所要解决的技术问题在于,提供一种用于代码分析的对话式gpt数据处理方法及系统,能够有效提高gpt服务的智能化程度,提高用户的代码分析效率,减小用户对代码进行反编译分析的难度,为代码安全性测试和反编译研究提供精确的数据基础。
2、为了解决上述技术问题,本发明第一方面公开了一种用于代码分析的对话式gpt数据处理方法,所述方法包括:
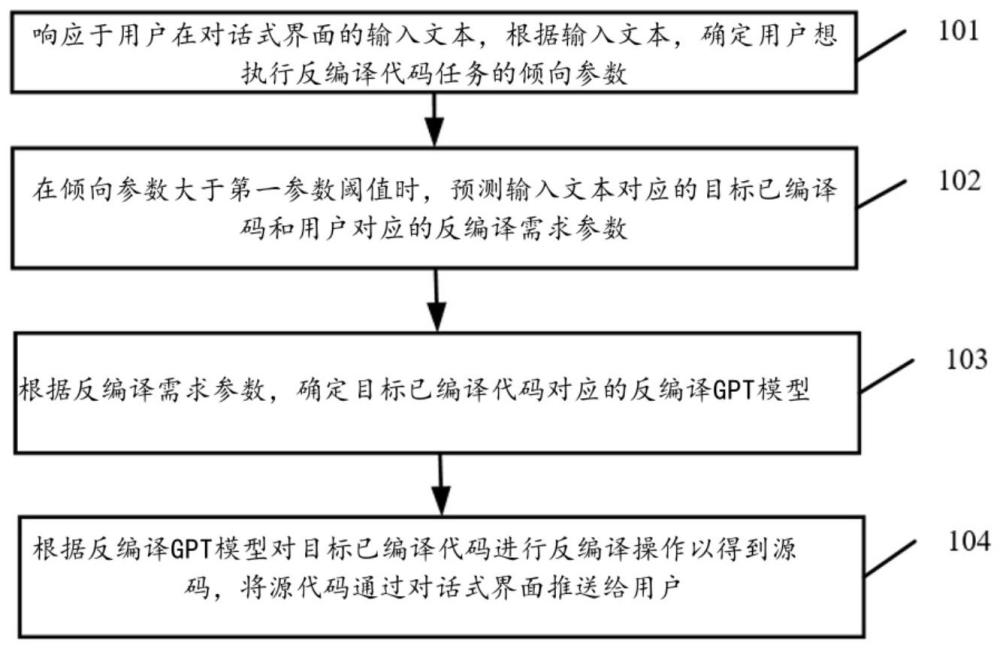
3、响应于用户在对话式界面的输入文本,根据所述输入文本,确定所述用户想要执行反编译代码任务的倾向参数;
4、在所述倾向参数大于第一参数阈值时,预测所述输入文本对应的目标已编译代码和所述用户对应的反编译需求参数;
5、根据所述反编译需求参数,确定所述目标已编译代码对应的反编译gpt模型;
6、根据所述反编译gpt模型对所述目标已编译代码进行反编译操作以得到源代码,将所述源代码通过所述对话式界面推送给所述用户。
7、作为一个可选的实施方式,在本发明第一方面中,所述根据所述输入文本,确定所述用户想要执行反编译代码任务的倾向参数,包括:
8、基于预设的反编译需求关键词集合,对所述输入文本进行识别,以得到所述输入文本对应的多个需求关键词的词数量;
9、将所述输入文本中的不同输入时间点的多个文本段落分别输入至训练好的语气类型识别模型中,以得到每一所述文本段落对应的语气类型;所述语气类型识别模型通过包括有多个训练文本和对应的语气标注的训练数据集训练得到;
10、基于预设的语气类型变化规律,计算所有所述文本段落对应的语气类型对应的规律匹配参数;
11、将所述输入文本输入至训练好的意愿强烈程度识别模型中,以得到所述输入文本对应的意愿强烈程度参数;
12、计算所述词数量、所述规律匹配参数和所述意愿强烈程度参数的加权求和平均值,得到所述用户想要执行反编译代码任务的倾向参数。
13、作为一个可选的实施方式,在本发明第一方面中,所述基于预设的语气类型变化规律,计算所有所述文本段落对应的语气类型对应的规律匹配参数,包括:
14、根据对应的所述输入时间点从早到晚,对所有所述文本段落对应的语气类型进行排序得到语气类型序列;所述语气类型为陈述、请求、询问、假设或感叹;
15、获取预设数据库中的多个标准反编译请求文本对应的文本语气类型序列;
16、计算所有所述文本语气类型序列和所述语气类型序列之间的序列相似度的平均值,得到对应的规律匹配参数。
17、作为一个可选的实施方式,在本发明第一方面中,所述预测所述输入文本对应的目标已编译代码和所述用户对应的反编译需求参数,包括:
18、将所述输入文本输入至训练好的代码区域文本识别算法模型,以得到所述输入文本对应的代码区域文本;
19、基于预设的代码关键词数据库,识别出所述代码区域文本中的所有代码关键词;
20、将所述代码区域文本中第一个所述代码关键词和最后一个所述代码关键词以及中间的所有文本,确定为目标已编译代码;
21、根据所述用户对应的所有相似历史用户记录中的历史反编译需求,以及所述多个需求关键词,确定所述用户对应的反编译需求参数。
22、作为一个可选的实施方式,在本发明第一方面中,所述根据所述用户对应的所有相似历史用户记录中的历史反编译需求,以及所述多个需求关键词,确定所述用户对应的反编译需求参数,包括:
23、对于历史用户数据库中的每一历史用户,计算该历史用户的用户参数和所述用户的用户参数之间的第一参数相似度;所述用户参数包括用户职业、用户性别、用户位置和用户
24、将所述第一参数相似度大于预设的相似度阈值的所有所述历史用户,确定为相似历史用户;
25、对于每一候选需求,计算该候选需求与每一所述相似历史用户的历史反编译需求之间的第一相似度;
26、计算该候选需求对应的所有所述第一相似度的加权求和平均值,得到该候选需求对应的第二相似度;其中,每一所述第一相似度的加权计算权重与对应的所述相似历史用户对应的所述第一参数相似度成正比;
27、计算该候选需求与所述多个需求关键词之间的第三相似度;
28、计算所述第二相似度和所述第三相似度的乘积,得到该候选需求对应的优先参数;
29、将所述优先参数大于预设的优先参数阈值的所有所述候选需求,确定为所述用户对应的反编译需求参数;所述反编译需求参数包括有代码注释信息、代码语言信息、代码用途信息、代码功能信息、代码混淆信息和代码编译工具信息中的至少一种。
30、作为一个可选的实施方式,在本发明第一方面中,所述根据所述反编译需求参数,确定所述目标已编译代码对应的反编译gpt模型,包括:
31、对于每一候选gpt模型,计算该候选gpt模型对应的训练数据集中的编译参数标注和所述反编译需求参数之间的第二参数相似度;
32、计算该候选gpt模型对应的训练数据集中的已编译代码和所述目标已编译代码之间的代码相似度;
33、计算所述第二参数相似度和所述代码相似度之间的加权求和平均值,得到该候选gpt模型对应的模型匹配度;
34、将所述模型匹配度最高的所述候选gpt模型,确定为所述目标已编译代码对应的反编译gpt模型。
35、作为一个可选的实施方式,在本发明第一方面中,所述反编译gpt模型是通过包括有多个训练已编译代码和对应的代码编译参数标注和反编译代码标注的训练数据集,对预训练得到的transformers模型进行微调训练得到的。
36、作为一个可选的实施方式,在本发明第一方面中,所述方法还包括:
37、在预设时间周期内接受到超过预设数量阈值的要求文本时,获取每一所述要求文本对应的输入时间点、用户网络信息、所述倾向参数和所述反编译需求参数;所述要求文本为对应的所述倾向参数大于第二参数阈值的输入文本;所述第二参数阈值大于所述第一参数阈值;
38、计算所有所述要求文本对应的所述输入时间点对应的紧密度参数;
39、计算所有所述要求文本对应的所述倾向参数的参数平均值;
40、计算任意两个所述要求文本对应的所述反编译需求参数之间的第三参数相似度,并计算所有所述要求文本对应的所有所述第三参数相似度的相似度平均值;
41、计算所述紧密度参数、所述参数平均值和所述相似度平均值的加权求和平均值,得到攻击表征参数;
42、在所述攻击表征参数大于预设的第三参数阈值时,将所有所述要求文本对应的所述用户网络信息确定为隔离用户信息。
43、本发明实施例第二方面公开了一种用于代码分析的对话式gpt数据处理系统,所述系统包括:
44、第一确定模块,用于响应于用户在对话式界面的输入文本,根据所述输入文本,确定所述用户想要执行反编译代码任务的倾向参数;
45、预测模块,用于在所述倾向参数大于第一参数阈值时,预测所述输入文本对应的目标已编译代码和所述用户对应的反编译需求参数;
46、第二确定模块,用于根据所述反编译需求参数,确定所述目标已编译代码对应的反编译gpt模型;
47、反编译模块,用于根据所述反编译gpt模型对所述目标已编译代码进行反编译操作以得到源代码,将所述源代码通过所述对话式界面推送给所述用户。
48、作为一个可选的实施方式,在本发明第二方面中,所述根据所述输入文本,确定所述用户想要执行反编译代码任务的倾向参数,包括:
49、基于预设的反编译需求关键词集合,对所述输入文本进行识别,以得到所述输入文本对应的多个需求关键词的词数量;
50、将所述输入文本中的不同输入时间点的多个文本段落分别输入至训练好的语气类型识别模型中,以得到每一所述文本段落对应的语气类型;所述语气类型识别模型通过包括有多个训练文本和对应的语气标注的训练数据集训练得到;
51、基于预设的语气类型变化规律,计算所有所述文本段落对应的语气类型对应的规律匹配参数;
52、将所述输入文本输入至训练好的意愿强烈程度识别模型中,以得到所述输入文本对应的意愿强烈程度参数;
53、计算所述词数量、所述规律匹配参数和所述意愿强烈程度参数的加权求和平均值,得到所述用户想要执行反编译代码任务的倾向参数。
54、作为一个可选的实施方式,在本发明第二方面中,所述第一确定模块基于预设的语气类型变化规律,计算所有所述文本段落对应的语气类型对应的规律匹配参数的具体方式,包括:
55、根据对应的所述输入时间点从早到晚,对所有所述文本段落对应的语气类型进行排序得到语气类型序列;所述语气类型为陈述、请求、询问、假设或感叹;
56、获取预设数据库中的多个标准反编译请求文本对应的文本语气类型序列;
57、计算所有所述文本语气类型序列和所述语气类型序列之间的序列相似度的平均值,得到对应的规律匹配参数。
58、作为一个可选的实施方式,在本发明第二方面中,所述预测模块预测所述输入文本对应的目标已编译代码和所述用户对应的反编译需求参数的具体方式,包括:
59、将所述输入文本输入至训练好的代码区域文本识别算法模型,以得到所述输入文本对应的代码区域文本;
60、基于预设的代码关键词数据库,识别出所述代码区域文本中的所有代码关键词;
61、将所述代码区域文本中第一个所述代码关键词和最后一个所述代码关键词以及中间的所有文本,确定为目标已编译代码;
62、根据所述用户对应的所有相似历史用户记录中的历史反编译需求,以及所述多个需求关键词,确定所述用户对应的反编译需求参数。
63、作为一个可选的实施方式,在本发明第二方面中,所述预测模块根据所述用户对应的所有相似历史用户记录中的历史反编译需求,以及所述多个需求关键词,确定所述用户对应的反编译需求参数的具体方式,包括:
64、对于历史用户数据库中的每一历史用户,计算该历史用户的用户参数和所述用户的用户参数之间的第一参数相似度;所述用户参数包括用户职业、用户性别、用户位置和用户
65、将所述第一参数相似度大于预设的相似度阈值的所有所述历史用户,确定为相似历史用户;
66、对于每一候选需求,计算该候选需求与每一所述相似历史用户的历史反编译需求之间的第一相似度;
67、计算该候选需求对应的所有所述第一相似度的加权求和平均值,得到该候选需求对应的第二相似度;其中,每一所述第一相似度的加权计算权重与对应的所述相似历史用户对应的所述第一参数相似度成正比;
68、计算该候选需求与所述多个需求关键词之间的第三相似度;
69、计算所述第二相似度和所述第三相似度的乘积,得到该候选需求对应的优先参数;
70、将所述优先参数大于预设的优先参数阈值的所有所述候选需求,确定为所述用户对应的反编译需求参数;所述反编译需求参数包括有代码注释信息、代码语言信息、代码用途信息、代码功能信息、代码混淆信息和代码编译工具信息中的至少一种。
71、作为一个可选的实施方式,在本发明第二方面中,所述第二确定模块根据所述反编译需求参数,确定所述目标已编译代码对应的反编译gpt模型的具体方式,包括:
72、对于每一候选gpt模型,计算该候选gpt模型对应的训练数据集中的编译参数标注和所述反编译需求参数之间的第二参数相似度;
73、计算该候选gpt模型对应的训练数据集中的已编译代码和所述目标已编译代码之间的代码相似度;
74、计算所述第二参数相似度和所述代码相似度之间的加权求和平均值,得到该候选gpt模型对应的模型匹配度;
75、将所述模型匹配度最高的所述候选gpt模型,确定为所述目标已编译代码对应的反编译gpt模型。
76、作为一个可选的实施方式,在本发明第二方面中,所述反编译gpt模型是通过包括有多个训练已编译代码和对应的代码编译参数标注和反编译代码标注的训练数据集,对预训练得到的transformers模型进行微调训练得到的。
77、作为一个可选的实施方式,在本发明第二方面中,所述系统还用于执行以下步骤:
78、在预设时间周期内接受到超过预设数量阈值的要求文本时,获取每一所述要求文本对应的输入时间点、用户网络信息、所述倾向参数和所述反编译需求参数;所述要求文本为对应的所述倾向参数大于第二参数阈值的输入文本;所述第二参数阈值大于所述第一参数阈值;
79、计算所有所述要求文本对应的所述输入时间点对应的紧密度参数;
80、计算所有所述要求文本对应的所述倾向参数的参数平均值;
81、计算任意两个所述要求文本对应的所述反编译需求参数之间的第三参数相似度,并计算所有所述要求文本对应的所有所述第三参数相似度的相似度平均值;
82、计算所述紧密度参数、所述参数平均值和所述相似度平均值的加权求和平均值,得到攻击表征参数;
83、在所述攻击表征参数大于预设的第三参数阈值时,将所有所述要求文本对应的所述用户网络信息确定为隔离用户信息。
84、本发明第三方面公开了另一种用于代码分析的对话式gpt数据处理系统,所述系统包括:
85、存储有可执行程序代码的存储器;
86、与所述存储器耦合的处理器;
87、所述处理器调用所述存储器中存储的所述可执行程序代码,执行本发明第一方面公开的用于代码分析的对话式gpt数据处理方法中的部分或全部步骤。
88、本发明第四方面公开了一种计算机存储介质,所述计算机存储介质存储有计算机指令,所述计算机指令被调用时,用于执行本发明第一方面公开的用于代码分析的对话式gpt数据处理方法中的部分或全部步骤。
89、与现有技术相比,本发明实施例具有以下有益效果:
90、本发明能够基于用户的输入文本识别出用户的反编译倾向,再在倾向较高时预测出代码和反编译需求,以确定出反编译gpt模型进行精确的代码反编译操作,从而能够有效提高gpt服务的智能化程度,提高用户的代码分析效率,减小用户对代码进行反编译分析的难度,为代码安全性测试和反编译研究提供精确的数据基础。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194396.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。