一种资源受限条件下民航飞机四舱异常检测方法
- 国知局
- 2024-07-31 22:47:51
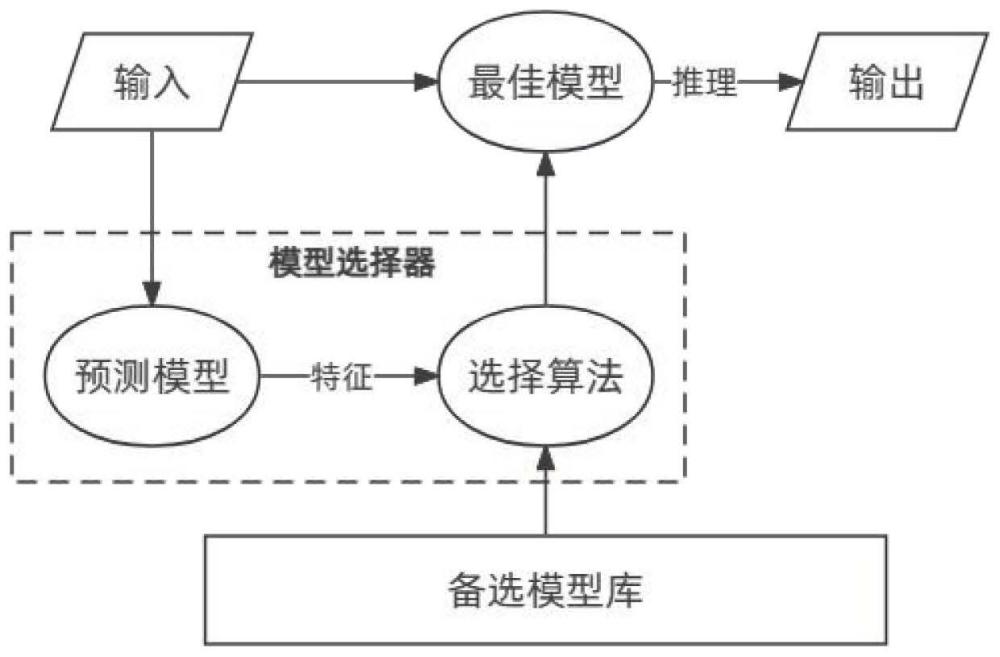
本发明涉及一种资源受限条件下民航飞机四舱异常检测方法。
背景技术:
1、民航机舱软硬件资源受限,电子舱空间狭小、嵌入式设备适航要求高,装机设备算力较低。因此受静动态资源约束、任务优先约束的影响,高精度智能算法难以有效部署,即面临着兼顾智能算法精度与降低系统时延保证算法实时性的挑战,主要问题如下:
2、(1)模型轻量化缺少实际硬件中对于动态资源自适应的考虑
3、模型轻量化技术能够在损失一定精度的情况下进一步降低模型在内存与计算量上的需求,从而使得模型能够部署于算力受限的平台。它致力于降低模型参数和计算量,通常会产生一定的精度损失,且在实际平台中通常部署单个经过轻量化的模型,这缺少实际硬件中对于动态资源自适应的考虑。
4、(2)模型选择对多个预训练模型的需求带来了额外的训练耗时开销
5、以推理结果为依据进行模型选择可能承担无效推理带来的资源开销,模型选择步骤永远在进行了至少一次推理之后。此外,模型选择算法基于网络的输出结果,因此需要适应不同模型的输出表示,例如图像分类与目标检测的网络输出不同,在具体的模型应用场景需要定制具体的选择算法以判断初步推理结果的可信度。
6、(3)计算资源调度方案需要大量离线分析带来沉重的性能分析开销
7、被动式的计算资源缩放并会带来推理运行时额外调度开销。而主动的资源分配与调度优化需要对多负载下的推理性能变化进行一定的判断与预测。但是,它们都需要离线分析大量可能的推理工作负载配置(不同批次大小和并发级别),这会带来沉重的性能分析开销。
8、因此,深度学习算法在资源受限条件下的机载嵌入式设备上如何高效部署与优化成为一个需要解决的问题,本发明涉及一种资源受限条件下民航飞机四舱异常检测方法。
技术实现思路
1、针对现有方法存在的上述问题,本发明提供了一种资源受限条件下民航飞机四舱异常检测方法,其获得了以下效果:1)将模型轻量化部署与模型选择结合,通过轻量化形成备选模型。提取模型输入数据的特征训练模型选择器,通过堆叠多个轻量化的模型,通过模型选择器选择当前输入数据、时延目标下的最佳模型,达到有效避免轻量化导致的精度下降的同时优化推理速度的效果;2)以轻量级方式表征并行模型推理负载的性能变化,作为资源配置策略的基础。通过对计算资源的主动感知,联合输入数据特征,优化调整模型选择、gpu资源分配和批次大小设置,形成对计算资源自适应的模型动态部署优化策略,满足在嵌入式设备资源受限情况下的合理部署。
2、根据本发明的一个方面,提供了一种轻量化备选模型自适应选择算法,其特征在于包括如下步骤:
3、a1)使用剪枝、量化等模型轻量化方法对目标模型mb进行压缩,得到轻量化模型ms;
4、b1)将步骤a1)所述体积不同的两个模型mb、ms进行前向推理,形成map表现数据;
5、c1)将步骤b1)所述map表现数据作为每张图片的标签,构成即将训练的预测模型的训练数据集;
6、d1)利用多任务学习构建预测模型,为每一组大小模型mb、ms构建一个对应的预测模型;
7、e1)将步骤d1)所述预测模型作为建立选择算法的前置步骤,预测模型输出为输入图片对于每个候选模型的map。对于候选模型为小与大两个模型的情况,分别为maps、mapb;
8、f1)设立阈值λ,认为当步骤e1)所述mapb-maps>λ时,可认为大模型对于此特定输入具有更好的表现。反之,以可接受的精度损失为代价,可选择小模型作为最佳推理模型。λ值可从步骤e1)训练所用的数据集中计算优化出最佳值。
9、根据本发明的一个方面,提供了一种并行负载性能变化分析算法,其特征在于包括如下步骤:
10、a2)对目标推理模型进行基准测试,利用nsight system等gpu性能分析工具与nvidia-smi接口等获得负载参数:推理输入数据大小与输出数据大小、推理负载的核函数数量与推理负载调度延迟;
11、b2)为推理负载单独运行时的gpu活跃时间受到推理负的gpu资源与批次大小的影响关系进行建模。gpu活跃时间与分配的gpu资源大致成反比,且gpu活跃时间随批次大小的增加可以用二次函数表示;
12、c2)启动多个1到5个目标推理模型相同的推理负获得共置时的gpu执行延迟数据,经过分析获得描述推理负载由于gpu二级缓存争用导致gpu活跃时间延长的参数、描述gpu功率需求和gpu工作频率之间的关系的参数,表示增长调度延迟与推理负载共置数量之间的关系的参数。推理负载的活跃时间参数,通过最小二乘法对9种不同批次大小与分配gpu资源的数据进行拟合获得;
13、d2)对gpu功率、gpu二级缓存利用率和gpu处理能力之间的关系进行建模,相关参数使用最小二乘法拟合获得;
14、e2)通过nvidia-smi获取gpu功率上限与gpu频率上限,在空载时获得空闲功率;
15、f2)将一定量数据从cpu内存传输到gpu内存获得pcie带宽;
16、g2)根据步骤d2)所述功率参数与步骤e2)所述空闲功率计算gpu设备上的总功率需求;
17、h2)根据步骤e2)糊功率上限、步骤c2)所述gpu活跃时间延长参数、步骤e2)所述gpu功率上限与步骤g2)所述设备总功率需求,对gpu设备上的gpu工作频率进行建模;
18、i2)根据步骤b2)所述gpu活跃时间、步骤c2)所述gpu活跃时间延长的参数和步骤d2)所述gpu二级缓存利用率,对推理负载运行在gpu设备上的gpu活跃时间进行建模;
19、j2)根据步骤c2)所述表示增长调度延迟与推理负载共置数量之间的关系的参数计算推理工作负载增加的调度延迟;
20、k2)根据步骤a2)所述推理负载调度延迟与步骤j2)所述推理工作负载增加的调度延迟计算推理工作负载的核函数总调度延迟;
21、l2)计算gpu的执行延迟、数据加载延迟和结果反馈延迟;
22、m2)计算最终的推理工作负载的吞吐量和推理工作负载延迟;
23、n2)根据步骤m2)所述计算结果,在给定请求到达率和延迟服务级别目标的基础上,计算最佳gpu资源和批次大小配置,最小化gpu资源成本。
24、根据本发明的一个方面,提供了一种算力资源自感知模型动态部署框架,其特征在于包括如下步骤:
25、a3)结合本发明的轻量化备选模型自适应选择算法,对于特定的网络输入,进行模型选择的优化;结合本发明的并行负载性能变化分析算法,计算在给定请求到达率和延迟服务级别目标的基础上最佳gpu资源和批次大小配置;
26、b3)context模块为每个ai任务创建对应的模型后台进程,当任务句有多段模型推理的需求时,会相应的创建多个模型后台,例如检测+分类等;
27、c3)batching模块在给定批次大小设置参数的基础上,对数据进行缓存与合并后传入gpu进行前向推理。其中模型的推理线程对应每个模型负载在mps下的gpu资源配置。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194662.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。