一种基于大数据的市场数据精准采集方法与流程
- 国知局
- 2024-07-31 22:50:20
本发明涉及数据采集,具体涉及一种基于大数据的市场数据精准采集方法。
背景技术:
1、随着市场竞争的加剧和消费者需求的多样化,企业需要更深入地了解市场情况,以制定更准确、更有针对性的市场营销策略。而市场调研是获取市场信息的重要手段,通过收集和分析市场调研数据,企业可以了解市场的需求、竞争对手、消费者行为等关键信息,从而做出更明智的决策。
2、随着网络销售的不断发展,各大电商平台都具有销售大数据的自动采集功能,不仅方便电商平台对店铺进行管理,也方便店铺对其运营策略的调整,消费者需要在网上购买商品时,输入商品名称,并点开商品详情页面,就能够得到店铺评分、月销量、评论信息和评论数量等销售数据,进而方便消费者进行选择,挑选出更可靠的商品,但是这些销售数据可能存在伪造的情况,例如存在商家雇佣刷单团队,通过对暗号的形式进行刷单来实现对某一商品的销量突增,通过刷单行为,商家可以获取虚假的销量以及在并未发生实际消费的情况下对商品或服务进行评价,隐瞒或伪造关键的交易信息,导致实际采集到的市场销售数据存在虚假信息,以至于市场数据分析的结果失去参考价值。
技术实现思路
1、本发明的目的在于提供一种基于大数据的市场数据精准采集方法,解决以下技术问题:
2、通过刷单行为,商家可以获取虚假的销量以及在并未发生实际消费的情况下对商品或服务进行评价,隐瞒或伪造关键的交易信息,导致实际采集到的市场销售数据存在虚假信息,以至于市场数据分析的结果失去参考价值。
3、本发明的目的可以通过以下技术方案实现:
4、一种基于大数据的市场数据精准采集方法,包括以下步骤:
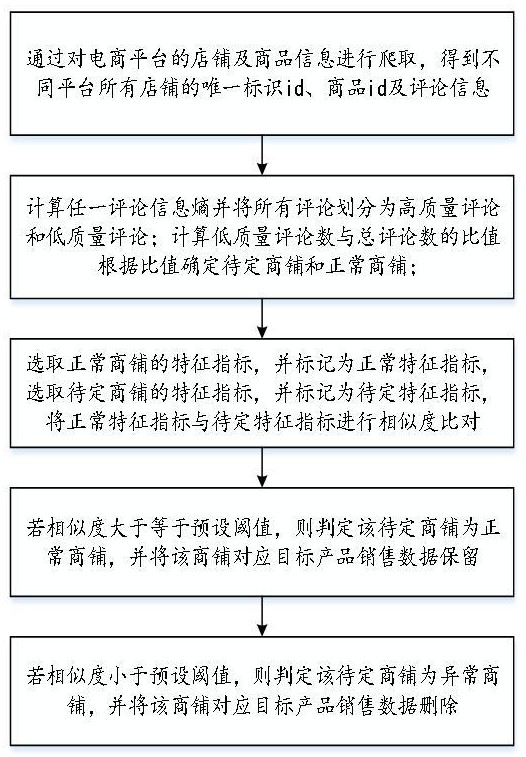
5、s1,通过对电商平台的店铺及商品信息进行爬取,得到不同平台所有店铺的唯一标识id、商品id及评论信息;所述评论信息包括评论者、评论产品和评论内容;
6、s2,选取任一商品并标记为目标商品,对任一商铺目标商品的评论信息进行预处理,对预处理后的评论信息进行二元分词,得到若干二元词组集合,依次计算任一二元词组在评论信息中的概率并标记为p1,p2,...,pn,获取任一评论中所包含的所有二元词组,根据二元词组的概率计算得出任一评论的信息熵,若存在任一评论信息熵大于等于预设阈值,则判定该评论为高质量评论;若存在任一评论信息熵小于预设阈值,则判定该评论为低质量评论;计算低质量评论数n与总评论数m的比值,若比值大于预设阈值,则将该商铺标定为待定商铺;若比值小于等于预设阈值,则将该商铺标定为正常商铺;
7、s3,对任一商铺目标商品的评论信息进行方面词提取,得到目标商品的所有方面词;根据所述方面词对任一评论进行划分,得到若干评论,利用k-means聚类对所述方面词进行分类,得到若干方面特征,根据所述方面特征对所有评论进行划分,得到若干特征集合,依次对任一评论进行情感识别,得到任一特征集合的所有好评评论和差评评论,计算任一特征集合的好评信息熵,将所有特征集合的好评信息熵进行归一化处理,得到对应特征指标;
8、选取正常商铺的特征指标,并标记为正常特征指标,选取任一待定商铺的特征指标,并标记为待定特征指标,将正常特征指标与待定特征指标进行相似度比对,若相似度大于等于预设阈值,则判定该待定商铺为正常商铺,并将该商铺对应的目标商品的销售数据保留;若相似度小于预设阈值,则判定该待定商铺为异常商铺,并将该商铺对应目标商品的销售数据删除。
9、作为本发明进一步的方案:所述s2中,信息熵的计算过程为:
10、;
11、其中,pi为该评论中任一二元词组在评论信息中的概率,n为该评论中所有二元词组的数量。
12、作为本发明进一步的方案:所述s3中,方面词的提取过程为:
13、通过正则表达式将评论内容中的非文本元素进行删除,得到处理文本,将该处理文本带入预先训练的bi-lstm分类模型中,得到目标商品的所有方面词。
14、作为本发明进一步的方案:所述s3中,评论内容划分的具体过程为:
15、提取评论文本中的所有方面词的起始和结束位置,以行文方向为目标方向确定首个方面词的起始位置并作为分割起点,以下一方面词的结束位置作为分割终点,对评论文本进行切割,得到若干评论。
16、作为本发明进一步的方案:所述s3中,好评信息熵的计算过程为:
17、pa=a/m;
18、;
19、其中,h为信息熵,a为划分后的任一特征的好评评论数,m为划分后的任一特征集合的总评论数,pa为评论信息为好评概率。
20、作为本发明进一步的方案:所述s3中,特征指标包括外观、质量、价格、服务态度和物流特征指标。
21、作为本发明进一步的方案:所述s3中,相似度对比的过程为:
22、分别以外观特征指标作为底面的宽、以价格特征指标作为底面的长、以质量特征指标作为高,生成对应的正常长方体和待定长方体,计算得到正常长方体的体积v1和待定长方体体积v2,将正常长方体与待定长方体在三维空间中进行叠加,选取当叠加体积为最大时的叠加状态,获取此时叠加区域的体积v0,计算v0/(v1+v2)的数值并将该数值标记为相似度。
23、作为本发明进一步的方案:叠加过程中在三维空间中,正常长方体的长度边与待定长方体的任一对应边保持平行。
24、本发明的有益效果:
25、本发明通过电商平台的店铺及商品信息进行爬取,得到不同平台的商品销售数据,选取任一商品作为目标商品,获取该任一商铺关于目标商品的评论信息并进行二元分词,获取任一评论中包含的所有二元词组,计算评论信息熵,根据信息熵值将评论分为高质量评论和低质量评论,计算低质量评论数n与总评论数m的比值,若比值大于预设阈值,则将该商铺标定为待定商铺,通过与正常商铺目标商品的评价特征进行三维体积叠加对比,计算叠加比例,将选取的指标分别作为图形的参数,由于参数彼此之间独立而又协同,相似度结果具有客观实用性,同时,只有当所有参数都接近时,两个三维图形的叠加体积才会达到最大,当待定商铺存在刷单行为时目标商品的评价特征参数会与正常商铺的评价特征参数产生差异,导致实际生成的三维图形的差异较大,从而能够客观准确的从待定商铺中筛选出异常商铺,将异常商铺对应目标商品的销售数据删除,进而得到精准的目标商品市场销售数据。
技术特征:1.一种基于大数据的市场数据精准采集方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于大数据的市场数据精准采集方法,其特征在于,所述s2中,信息熵的计算过程为:
3.根据权利要求1所述的一种基于大数据的市场数据精准采集方法,其特征在于,所述s3中,方面词的提取过程为:
4.根据权利要求1所述的一种基于大数据的市场数据精准采集方法,其特征在于,所述s3中,评论内容划分的具体过程为:
5.根据权利要求1所述的一种基于大数据的市场数据精准采集方法,其特征在于,所述s3中,好评信息熵的计算过程为:
6.根据权利要求1所述的一种基于大数据的市场数据精准采集方法,其特征在于,所述s3中,特征指标包括外观、质量、价格、服务态度和物流特征指标。
7.根据权利要求1所述的一种基于大数据的市场数据精准采集方法,其特征在于,所述s3中,相似度对比的过程为:
8.根据权利要求7所述的一种基于大数据的市场数据精准采集方法,其特征在于,叠加过程中在三维空间中,正常长方体的长度边与待定长方体的任一对应边保持平行。
技术总结本发明公开了一种基于大数据的市场数据精准采集方法,属于数据采集技术领域,具体包括:通过对电商平台的店铺及商品信息进行爬取;计算任一评论信息熵并将所有评论划分为高质量评论和低质量评论;计算低质量评论数与总评论数的比值,根据比值确定待定商铺和正常商铺;选取正常商铺的特征指标,并标记为正常特征指标,选取任一待定商铺的特征指标,并标记为待定特征指标,将正常特征指标与待定特征指标进行相似度比对,若相似度大于等于预设阈值,则判定该待定商铺为正常商铺,并将该商铺销售数据保留;若相似度小于预设阈值,则判定该待定商铺为异常商铺,并将该商铺销售数据删除;本发明实现了对市场数据的精准采集。技术研发人员:韦晨,陈海玲受保护的技术使用者:广西泛华于成信息科技有限公司技术研发日:技术公布日:2024/7/29本文地址:https://www.jishuxx.com/zhuanli/20240730/194916.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。