一种基于视频的动态目标高精度三维重建方法
- 国知局
- 2024-07-31 22:58:42
本发明属于计算机视觉,特别涉及一种基于视频的动态目标高精度三维重建方法。
背景技术:
1、随着科技的飞速发展,计算机视觉、深度学习及三维重建技术日益成熟,人们对三维世界的认知与重构能力也获得了前所未有的提升。在工业设计、医学影像、机器人导航等诸多领域,对动态目标的高精度三维重建技术需求日益迫切。
2、传统的三维重建方法,如结构光、激光扫描等,虽然能够在一定程度上实现三维重建,但受限于成本高昂、操作复杂以及难以适应动态目标的实时重建等问题,其应用受到较大限制。近年来,基于神经辐射场(nerf)模型的三维重建方法崭露头角,该方法结合了深度学习和辐射场理论,通过学习场景的先验知识,能够生成高质量的三维模型。然而,面对动态目标的重建,传统的nerf方法仍面临着运动模糊、视角变化、遮挡等挑战,难以实现高精度和实时性的要求。
3、例如,传统的srf技术与本技术的基于优化后的神经辐射场模型(pixelnerf)的三维重建方法相比,在精度与细节捕捉能力、多视图信息融合、计算效率与实时性以及泛化能力等方面存在明显的缺陷
技术实现思路
1、为了克服上述现有技术的不足,本发明的目的在于提供一种基于视频的动态目标高精度三维重建方法,通过设计优化后的pixelnerf神经辐射场模型来准确恢复动态目标的几何形状和表面细节,从而提升基于视频的动态目标三维重建性能。
2、为了实现上述目的,本发明采用的技术方案是:
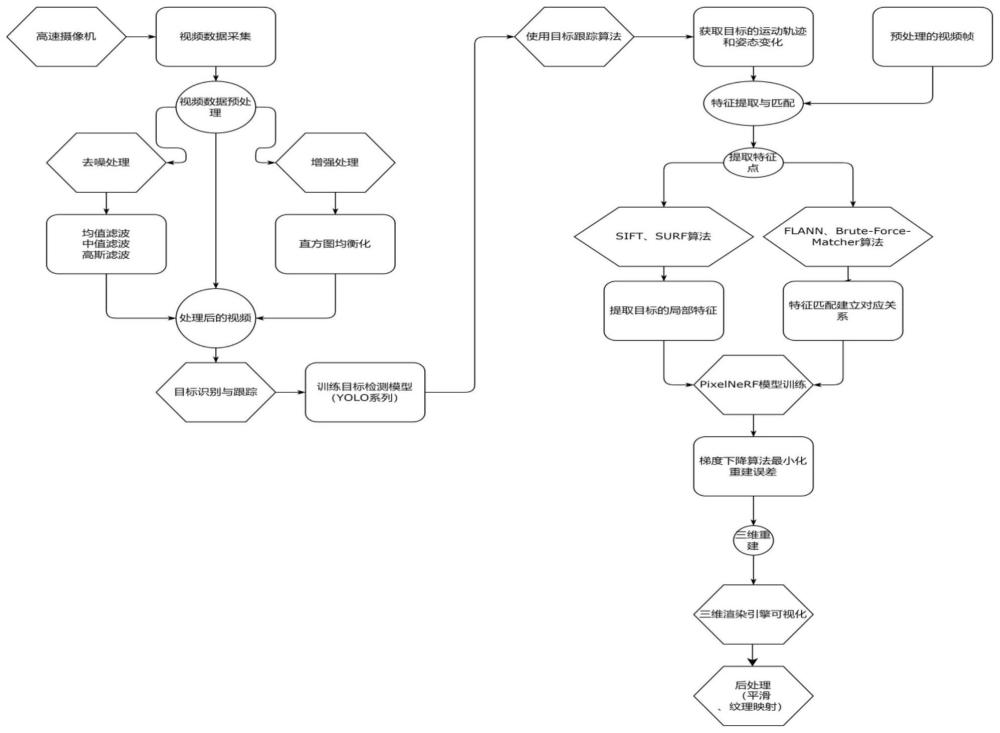
3、一种基于视频的动态目标高精度三维重建方法,包括以下步骤;
4、步骤s1:采集包含动态目标的视频数据,并进行预处理操作,以提高数据质量;
5、步骤s2:利用深度学习算法,对预处理后的视频数据进行处理,实现对动态目标的精确识别,在识别的基础上,对目标进行跨帧跟踪,确保目标在不同视角下的连续性和一致性;
6、步骤s3:在精确识别与跟踪的基础上,采用sift算法从视频帧中提取动态目标的特征点;这些特征点能够代表目标的关键信息;
7、随后,利用特征匹配算法将不同视角下的特征点进行匹配,建立目标在不同视角下的对应关系,通过匹配不同视角下的特征点,确保目标在三维空间中的连续性和一致性,为后续的三维重建提供准确的特征点对应关系;
8、步骤s4:利用卷积神经网络从视频帧中提取目标的底特征,所述底特征包含了场景的先验知识和目标的结构信息,然后,结合步骤s3中建立的特征点对应关系,将底特征映射到三维空间中,形成辐射场的表示,最后,通过体积渲染技术,结合光线追踪和采样策略,生成高质量的三维场景;
9、步骤s5:基于步骤s4三维重建所得到的结果,对模型进行可视化展示,并根据需要进行平滑、纹理映射的后处理操作,从而消除模型表面的不平滑和噪声,使模型更加光滑,为模型添加纹理图像,增强模型的真实感和细节表现,以提高模型的视觉效果和实用性。
10、优选的,所述步骤s1针对所拍的动态目标的视频数据与对应的相机位姿和参数,收集和计算不同相机内参和外参与多图像直接的联系;在采集完成后,进行包括去噪、增强对比度、稳定图像的预处理操作。为后续的目标识别、跟踪和特征提取等步骤提供更为准确和可靠的数据基础。
11、优选的,所述步骤s2中目标识别步骤采用yolo-v8模型进行目标检测,并结合deepsort算法实现目标的连续跟踪;
12、具体步骤为:
13、步骤201:首先,yolo-v8模型基于深度卷积神经网络进行目标检测,yolo-v8模型预测出边界框(bounding box)的坐标、宽高以及类别概率,其中,预测边界框的坐标通常使用如下公式:
14、tx=gx-cx/pw
15、ty=gy-cy/hw
16、tw=log(gw/pw)
17、th=log(gh/ph)
18、其中,(gx,gy)是实际边界框的中心坐标,(cx,cy)是网格单元的中心坐标,(pw,ph)是先验框(anchor box)的宽和高,(gw,gh)是实际边界框的宽和高。tx,ty,tw,th是模型需要学习的参数;
19、在yolo-v8中,模型还会输出每个边界框的置信度(confidence score),它通常通过以下公式计算:
20、confidence=pr(object)*iou(pred,gt)
21、其中,pr(object)表示该边界框内存在目标的概率,iou(pred,gt)表示预测边界框与实际边界框的交并比(intersection over union),用于衡量预测边界框与实际边界框的重叠程度;
22、步骤202:采用deepsort算法实现目标的连续跟踪;deepsort使用了深度学习模型(如卷积神经网络)来提取目标的特征向量,并通过计算特征向量之间的距离(如余弦距离或欧氏距离)来衡量目标的相似性。这个距离的计算公式根据所使用的距离度量方式而有所不同。当使用余弦距离作为相似度度量时,其数学公式如下:
23、假设有两个目标的特征向量分别为a和b,其中a=[a1,a2,…,an],b=[b1,b2,…,bn],且n是特征向量的维度。
24、余弦距离的计算公式为:
25、
26、其中,a·b是两个向量的点积(内积),即||a||和||b||分别是向量a和b的模(长度),即和
27、余弦距离的值域为[0,2],值越小表示两个向量越相似;在实际应用中,将余弦距离转换为余弦相似度:
28、
29、余弦相似度的值域为[-1,1],值越大表示两个向量越相似。
30、在deepsort算法中,通过计算连续帧之间目标特征向量的余弦相似度(或余弦距离的相反数),评估目标外观的连续性,从而辅助实现目标的稳定跟踪。
31、运动连续性的考虑通常基于目标的运动轨迹,通过计算目标在连续帧之间的位置、速度等运动参数的变化来评估目标的运动一致性。deepsort算法通过结合外观特征相似性和运动连续性,为每个目标分配一个唯一的轨迹id,实现目标的连续跟踪。通过深度学习算法的应用,确保目标在不同视角下的连续性和一致性。
32、yolo-v8模型和deepsort算法的结合使用,能够实现目标在视频帧中的精确识别和连续跟踪。所述yolo-v8模型为deepsort算法提供了准确的检测基础,而deepsort算法则通过利用目标的外观和运动信息,进一步提升了跟踪的鲁棒性和准确性。这种相互依存且互补的关系,使得整个目标识别和跟踪系统能够在不同视角下保持目标的连续性和一致性。优选的,所述步骤s3为了建立目标在不同视角下的对应关系,为后续的三维重建提供准确的匹配数据,采用了sift特征提取算法和lann快速近似最近邻搜索算法。
33、具体操作为:
34、步骤301:首先,利用sift算法从预处理后的视频帧中提取目标的局部特征点,局部特征点是图像中具有独特性和稳定性的区域,如角点、边缘或纹理区域。
35、对于sift算法中的描述子生成,首先对关键点周围的邻域进行采样,即在以关键点为中心的一个特定大小的区域进行采样,这个区域的大小通常根据尺度空间中的尺度值来确定,以确保在不同尺度的图像上都能有效地提取特征,再计算每个采样点的梯度,然后,统计这些梯度的方向直方图,生成一个描述子向量。这个过程表示为:
36、d=hist({grad(i(x,y,σ))|(x,y)∈neighborhood of keypoint})
37、其中:d是描述子向量,hist表示直方图统计操作,用于将梯度信息转换为描述子,grad(i(x,y,σ))表示在尺度σ下图像i在点(x,y)处的梯度,neighborhood of keypoint表示关键点周围的邻域;
38、步骤302:采用特征匹配算法:lann快速近似最近邻搜索算法对提取的特征点进行匹配;采用欧氏距离或余弦相似度,以确定匹配的准确性,欧式距离的计算方法为:
39、
40、dist(d1,d2)表示描述子d1和d2之间的欧氏距离,d1和d2是两个描述子向量,由sift、surf算法从图像中提取出来的,n是描述子向量的维度,即描述子中元素的数量,d1[i]和d2[i]分别表示d1和d2向量中第i个元素的值。
41、优选的,所述步骤s4在三维重建过程中采用pixelnerf模型进行实现。
42、具体步骤为:
43、步骤401:像素级编码与特征网络生成
44、在pixelnerf框架中,图像通过全卷积图像编码器进行像素级的编码。这个过程表示为:
45、f=encoder(image)
46、其中,encoder是全卷积图像编码器,image是输入的图像,f是生成的沿像素对齐的特征网络;
47、步骤402:nerf网络的颜色和密度值输出
48、将编码后的特征网络f与空间坐标信息(包括目标观察方向d和位置x)一起输入到nerf网络中,得到对应位置的颜色c和密度σ:
49、(c,σ)=nerf(f,x,d)
50、步骤403:体渲染
51、利用nerf网络输出的颜色c和密度σ,结合体渲染技术,对目标场景进行体渲染;体渲染的目标是生成一个二维图像,该图像反映了从相机视角通过三维场景的光线所携带的信息。在nerf中,每个点(x,y,z)在三维空间中都有一个对应的颜色和密度,给定相机光线r(t)=o+td(其中o是相机原点,d是光线的方向,t是参数化的距离),体渲染的目标是估计这条光线上的像素颜色c(r)。
52、体渲染的积分公式如下:
53、
54、其中:
55、·tn和tf分别是近平面和远平面的距离。
56、·是光线在t之前的累积透明度(即光线从tn到t没有被任何物质遮挡的概率)。
57、·σ(r(t))是点r(t)处的体积密度。
58、·c(r(t),d)是点r(t)处沿光线方向d的颜色;
59、步骤404:渲染损失计算
60、给定合成图像中的像素颜色csyn(ri)和原始图像中对应像素的颜色cgt(ri),渲染损失计算为:
61、
62、其中n是像素的数量,||·||表示颜色空间中的距离度量(例如rgb空间的欧氏距离),这个损失函数鼓励nerf网络生成与原始图像更接近的合成图像;
63、在训练过程中,通过最小化这个渲染损失(以及其他可能的损失项,如正则化损失),可以优化nerf网络的参数,从而提高体渲染的精度和三维重建的质量;
64、步骤405:网络优化与权重更新
65、通过反向传播算法,根据计算出的渲染损失lrender更新pixelnerf网络的权重,这个过程表示为:
66、
67、其中,optimizer是优化算法(如adam、sgd等),weightsold是更新前的网络权重,weightsnew是更新后的网络权重,是渲染损失关于网络权重的梯度;
68、经过多次迭代和优化,最终得到高精度的三维重建模型。
69、优选的,所述步骤s5使用三维渲染引擎,如opengl或directx,对重建得到的三维模型进行可视化展示,以便用户观察和评估模型效果。
70、具体步骤为:
71、步骤501:初始化渲染引擎。根据所选的渲染引擎(opengl或directx),进行相应的初始化工作。这包括创建渲染上下文、设置渲染参数、加载必要的库和插件。初始化完成后,渲染引擎将准备好接收并处理三维模型数据。
72、步骤502:加载三维模型。将重建得到的三维模型数据加载到渲染引擎中。这通常涉及将模型数据转换为渲染引擎可以理解的格式(如.obj、fbx等),并加载到渲染引擎的场景中。加载完成后,模型将出现在渲染引擎的虚拟场景中,准备进行渲染。
73、步骤503:设置渲染参数。根据需要设置渲染参数,以控制模型的外观和效果。这些参数可能包括光照模型、材质属性、纹理贴图等。通过调整这些参数,可以模拟不同的光照条件、实现不同的材质效果,并增强模型的视觉效果。
74、步骤504:进行渲染。使用渲染引擎的渲染函数对场景进行渲染。这通常涉及将相机的位置和方向设置为用户指定的视角,然后计算场景中每个物体的可见性和光照效果,并最终生成图像或视频帧。渲染过程可以实时进行,以便用户可以从不同角度观察模型。
75、同时,根据需要对模型进行优化和修正,包括平滑处理、纹理映射和可能的几何校正,以提高模型的精度和实用性。这一步骤能够进一步提升三维模型的质量和视觉效果,满足实际应用的需求。
76、本发明的有益效果:
77、1、高精度三维重建:步骤s4通过采用优化后的pixelnerf神经辐射场模型,本发明能够更准确地恢复动态目标的几何形状和表面细节。pixelnerf结合了像素级建模和神经辐射场的优点,使得重建结果更为精细和逼真。这极大地提升了基于视频的动态目标三维重建的性能和精度。
78、2、连续性与一致性保障:在步骤s2目标识别和跟踪阶段,本发明利用yolo-v8模型和deepsort算法,确保了目标在不同视角下的连续性和一致性。这种跨帧跟踪能力有效减少了因视角变化导致的目标断裂或混淆问题,为后续的三维重建提供了稳定可靠的目标信息。
79、3、特征匹配准确性提升:步骤s3采用sift算法和lann快速近似最近邻搜索算法进行特征提取和匹配,能够建立目标在不同视角下的准确对应关系。这一过程不仅提高了特征匹配的准确性,还为后续的三维重建提供了可靠的匹配数据,进一步提升了重建结果的精确性。
80、4、可视化展示与后处理优化:步骤s5通过三维渲染引擎对重建得到的三维模型进行可视化展示,用户能够直观地观察和评估模型效果。同时,根据需要进行平滑、纹理映射等后处理操作,能够消除模型表面的不平滑和噪声,增强模型的真实感和细节表现。这不仅提高了模型的视觉效果,还增强了其在实际应用中的实用性。
81、综上所述,本发明通过结合深度学习算法、特征提取与匹配技术、pixelnerf神经辐射场模型以及三维渲染引擎,实现了一种基于视频的动态目标高精度三维重建方法。该方法不仅提高了重建的精度和效率,还保证了重建结果的连续性和一致性,为动态目标的三维重建领域带来了显著的进步和实用价值。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195574.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表