一种基于混合比特位宽的稀疏卷积加速器
- 国知局
- 2024-07-31 22:58:39
本发明涉及芯片设计领域,尤其涉及一种基于混合比特位宽的稀疏卷积加速器。
背景技术:
1、卷积神经网络(cnn)作为当下最流行的深度学习模型,已被广泛应用在图像处理、目标检测、音频识别等ai领域。
2、卷积是卷积神经网络的基本算子,硬件上是由乘累加器实现卷积操作,传统的cnn乘法累加器针对处理固定格式的数据乘累加,如int16、int8乘法,而要实现int4、int2乘法时,采用int16、int8乘法器将会浪费大量乘法器位宽,无法高效利用乘法器。此外,随着神经网络模型压缩技术的发展,使用混合精度的稀疏数据格式部署卷积神经网络正成为趋势,卷积运算的数据格式可能混着int8、int4和int2类型,且存在大量的数据或比特位为零值。
3、因此,目前亟需一种灵活的、支持混合精度的稀疏卷积乘累加器。
技术实现思路
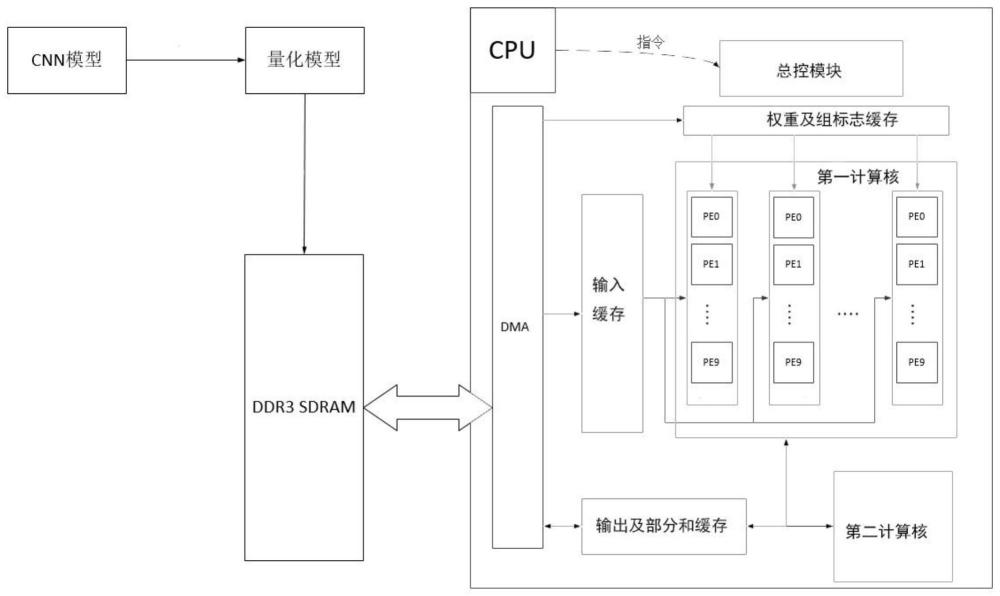
1、有鉴于此,为了解决传统卷积神经网络乘累加器灵活性低、难以高效进行混合数据格式的卷积运算的缺陷,本发明提出一种基于混合比特位宽的稀疏卷积加速器,包括:
2、总控模块,用于控制所述基于混合比特位宽的稀疏卷积加速器的整体运行;
3、直接内存访问(directmemoryaccess,dma),用于执行片内外图像数据和权重的搬运;
4、第一计算核,用于完成混合比特位宽的稀疏卷积层的加速;
5、缓存模块,用于缓存和复用数据。
6、在一些实施例中,还包括:
7、第二计算核,用于完成激活函数以及归一化层的计算。
8、在一些实施例中,所述第一计算核内设有多个计算引擎单元(processingelement,pe),所述计算引擎单元包括有符号乘法器、左移0/2多路选择器、左移0/4多路选择器和可配移位寄存器。
9、通过该优选实施例,提出了一种按位求和再移位累加,权重比特单元串行输入的卷积计算引擎。
10、在一些实施例中,在所述计算引擎单元中,包括32个有符号乘法器,其中:
11、将32个所述有符号乘法器分为4组;
12、当输入激活和权重为8bit时,所述计算引擎单元每次并行计算8输入通道的卷积乘累加。
13、在一些实施例中,所述当输入激活和权重为8bit时,所述计算引擎单元每次并行计算8输入通道的卷积乘累加,其具体包括:
14、在第一个周期,所述计算引擎单元输入8个通道的8bit输入激活以及对应的8个通道权重的最低比特单元,每组的8个所述有符号乘法器接收8个通道数据;
15、在第二个周期,保持所述计算引擎单元的输入激活不变,将对应的8个通道权重的次低比特单元输入至所述计算引擎单元;
16、在第三个周期,保持所述计算引擎单元的输入激活不变,将对应的8个通道权重的次高比特单元输入至所述计算引擎单元;
17、在第四个周期,保持所述计算引擎单元的输入激活不变,将对应的8个通道权重的最高比特单元输入至所述计算引擎单元,完成8个通道的乘累加计算;
18、根据权重串行周期,所述可配移位寄存器在四个周期内分别左移0、2、4、6。
19、本实施例中,为扩展支持混合2、4、8bit的输入激活和权重数据格式,通过对4组有符号乘法器进行灵活的数据映射,可完成总共12种数据格式的激活和权重乘累加计算。
20、在一些实施例中,基于所述计算引擎单元构建乘累加阵列,其中:
21、输入激活按层量化,权重数据按输入通道组量化。
22、在一些实施例中,还包括:
23、增加权重标志处理异步控制数据流。
24、其中,对于权重数据,将权重fifo输入至pe,每列pe复用相同的权重数据,不同列pe计算输出特征图的不同输出通道,由于不同卷积核量化压缩率的差异,导致不同列pe将会异步工作。因此通过增加一个权重标志处理异步控制数据流,助于总控模块完成异步数据流的控制。
25、在一些实施例中,还包括:
26、将待乘数据以2bit单位进行划分。
27、其中,任意8、4、6、2bit位宽数据都可以拆分成多个2bit基本单元的移位相加。
28、在一些实施例中,还包括:
29、在执行有符号乘法前进行符号扩展。
30、在该实施例中,考虑到需要支持输入激活的格式是有符号数或无符号数,权重需要支持有符号数,所以进行有符号乘法前需要进行额外的符号扩展。
31、基于上述方案,本发明提供了一种基于混合比特位宽的稀疏卷积加速器,通过低比特乘法器的灵活拆分组合,对不同数据格式的、不同稀疏性的乘累加计算都能高效支持,保持较高的硬件利用率;进一步地,提出基于该计算引擎单元组合成异步卷积的计算阵列,通过数据映射保持较高的数据复用率和计算阵列的时间、空间利用率;最后,完成了支持混合精度、比特级稀疏的cnn卷积加速器架构设计。
技术特征:1.一种基于混合比特位宽的稀疏卷积加速器,其特征在于,包括:
2.根据权利要求1所述一种基于混合比特位宽的稀疏卷积加速器,其特征在于,还包括:
3.根据权利要求2所述一种基于混合比特位宽的稀疏卷积加速器,其特征在于,所述第一计算核内设有多个计算引擎单元,所述计算引擎单元包括有符号乘法器、左移0/2多路选择器、左移0/4多路选择器和可配移位寄存器。
4.根据权利要求3所述一种基于混合比特位宽的稀疏卷积加速器,其特征在于,在所述计算引擎单元中,包括32个有符号乘法器,其中:
5.根据权利要求4所述一种基于混合比特位宽的稀疏卷积加速器,其特征在于,所述当输入激活和权重为8bit时,所述计算引擎单元每次并行计算8输入通道的卷积乘累加,其具体包括:
6.根据权利要求3所述一种基于混合比特位宽的稀疏卷积加速器,其特征在于,基于所述计算引擎单元构建乘累加阵列,其中:
7.根据权利要求6所述一种基于混合比特位宽的稀疏卷积加速器,其特征在于,还包括:
8.根据权利要求3所述一种基于混合比特位宽的稀疏卷积加速器,其特征在于,还包括。
9.根据权利要求8所述一种基于混合比特位宽的稀疏卷积加速器,其特征在于,还包括:
技术总结本发明公开了一种基于混合比特位宽的稀疏卷积加速器,该稀疏卷积加速器包括:总控模块,用于控制所述基于混合比特位宽的稀疏卷积加速器的整体运行;DMA,用于执行片内外图像数据和权重的搬运;第一计算核,用于完成混合比特位宽的稀疏卷积层的加速;缓存模块,用于缓存和复用数据。本发明提出了一种以低位宽乘法器为基本单元,通过加法、移位及基本单元的灵活组合,以支持混合精度计算的CNN乘法累加器结构,灵活、高效地实现对不同压缩网络模型的卷积算子的硬件加速。本发明可广泛应用于芯片设计领域。技术研发人员:胡湘宏,李荣峰,杨超明,李学铭,蔡述庭,熊晓明受保护的技术使用者:广东工业大学技术研发日:技术公布日:2024/7/29本文地址:https://www.jishuxx.com/zhuanli/20240730/195568.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表