一种基于状态空间模型的人脸图像复原方法
- 国知局
- 2024-07-31 22:59:51
本发明涉及一种基于状态空间的人脸图像复原方法,属于图像处理。
背景技术:
1、在影音娱乐、安防监控等场景下,高质量的清晰人脸图像不仅能为用户提供良好的视觉观感,还能帮助执法人员搜寻失踪人员等工作。由于拍摄条件存在诸多不稳定性因素,如成像设备对焦失败、相机抖动;成像环境的低光照、高曝光、拍摄对象运动干扰;信道传输有损压缩、编解码格式等,会导致图像存在多重干扰引发不同程度的退化。难以分辨的低质量人脸图像提供的有效身份信息十分有限。因此,人脸图像复原旨在从退化的低质人脸图像中恢复出清晰的高质人脸图像,有助于提升下游任务的鲁棒性,如:人脸超分辨率与识别、老照片恢复、虚拟数字人形象编辑等。
2、目前,人脸复原方法采用的模型架构主要基于卷积神经网络(cnn)和基于transformer网络这两类。现有基于卷积神经网络的方法由于卷积操作的局部特性,导致设计的模型往往无法挖掘全局信息;现有基于transformer网络的方法将图像划分成若干块后,采用计算量较大的自注意力机制把握全局信息,对像素级细节信息的捕捉能力有限。
3、所述方法在人脸复原任务中取得了一定的积极效果,但是在面对尺寸较大、退化更复杂且更严重的人脸图像时,无法同时挖掘并高效整合局部的细节信息与全局的几何信息,导致其复原性能难以满足现有行业需求。
技术实现思路
1、为克服现有技术中的不足,本发明提供一种基于状态空间模型的人脸图像复原方法。
2、状态空间模型架构相比卷积神经网络拥有全局信息挖掘能力;相比transformer模型架构不仅计算开销减少,还具有更强的时序记忆能力。本发明进一步引入多尺度技术,以缓解局部与全局信息互相融合不充分的问题,且能够在保证细节纹理与几何轮廓复原效果的同时,维持人脸身份信息的一致性。在面对复杂的真实退化场景时,本发明所提出的复原方法不仅能够取得较高的指标评分,如峰值信噪比psnr,还能复原出质量较高的清晰人脸图像。
3、为达到所述目的,本发明是采用下述技术方案实现的:
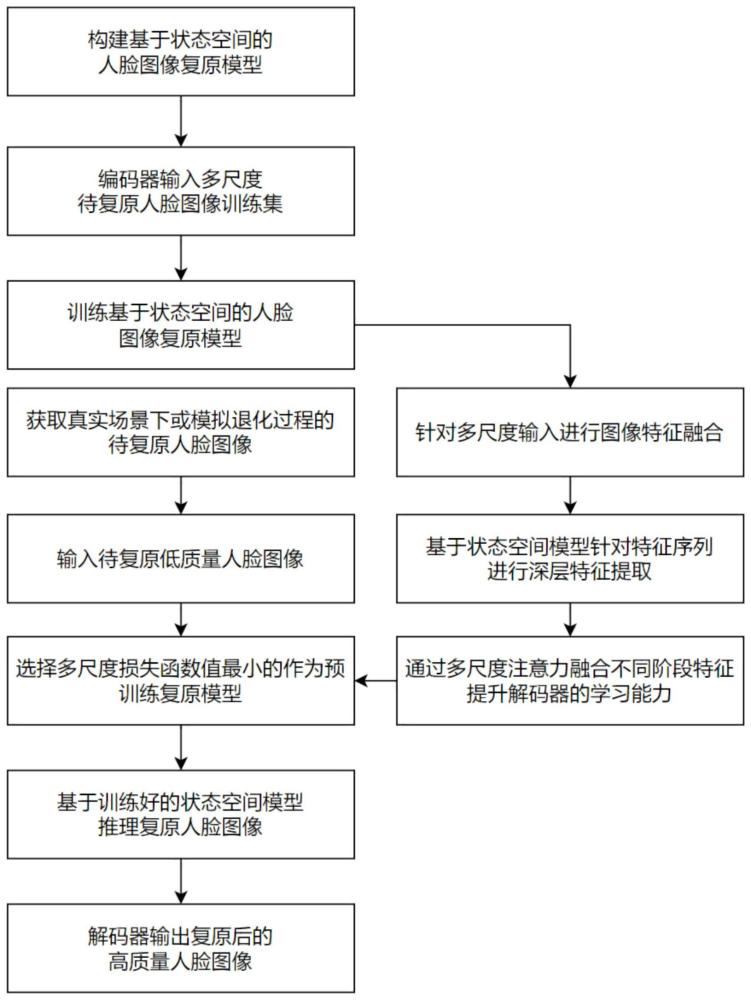
4、第一方面,本发明公开了一种基于状态空间模型的人脸图像复原方法,包括如下步骤:
5、获取待复原的人脸图像;
6、将所述待复原的人脸图像输入至复原模型,得到复原后的人脸图像;
7、其中,所述复原模型包括编码器和解码器;
8、所述编码器依次包括第一图像融合模块、第一多尺度状态空间模块、第二图像融合模块、第二多尺度状态空间模块、第三图像融合模块、第三多尺度状态空间模块;所述待复原的人脸图像与2倍下采样低质人脸图像经过第一图像融合模块融合后、经过第一多尺度状态空间模块提取得到第一阶段特征;第一阶段特征与4倍下采样低质人脸图像经过第二图像融合模块融合后、经过第二多尺度状态空间模块提取得到第二阶段特征;第二阶段特征与8倍下采样低质人脸图像经过第三图像融合模块融合后、经过第三多尺度状态空间模块提取得到第三阶段特征;
9、所述解码器依次包括第四多尺度状态空间模块、第一多尺度注意力融合模块、第五多尺度状态空间模块、第二多尺度注意力融合模块、第六多尺度状态空间模块、第三多尺度注意力融合模块;第三阶段特征经过第四多尺度状态空间模块得到2倍上采样恢复人脸图像,2倍上采样恢复人脸图像经过第一多尺度注意力融合模块与第一阶段特征、第二阶段特征和第三阶段特征进行融合后经过第五多尺度状态空间模块得到4倍上采样恢复人脸图像,4倍上采样恢复人脸图像经过第二多尺度注意力融合模块与第一阶段特征、第二阶段特征和第三阶段特征进行融合后经过第六多尺度状态空间模块得到8倍上采样恢复人脸图像,8倍上采样恢复人脸图像经过第三多尺度注意力融合模块与第一阶段特征、第二阶段特征和第三阶段特征进行融合后解码输出,并与输入低质人脸图像对齐贴合得到复原后的高质人脸图像。
10、在一些实施例中,所述第一图像融合模块、第二图像融合模块和第三图像融合模块的网络结构相同,均包括1个2倍下采样单元、1个特征提取单元和1个通道注意力单元,将不同尺度的低质人脸图像输入通过所述特征提取单元挖掘的浅层特征与编码器的不同阶段输出的深层特征利用所述通道注意力单元进行关键特征融合,推动图像像素与语义特征互相学习。
11、进一步地,所述特征提取单元包括残差卷积块和激活函数;其中所述残差卷积块包括2个卷积层和2个激活函数,采用修正线性函数作为激活函数,输入特征经过2个卷积层提取深层特征后的输出特征,与输入特征相加,得到最终的输出;
12、进一步地,所述通道注意力单元包括1个降维单元、用于为不同通道分配权重的注意力机制操作以及1个升维单元。
13、在一些实施例中,所述第一多尺度状态空间模块、第二多尺度状态空间模块、第三多尺度状态空间模块、第四多尺度状态空间模块、第五多尺度状态空间模块和第六多尺度状态空间模块的网络结构相同,均包括多个多尺度状态空间模型和1个特征提取单元,每个所述多尺度状态空间模型包含2个状态空间分支、1个降维单元、2个线性层、1个层归一化单元和1个升维单元,所述状态空间分支包含1个深度可分卷积、1个层归一化单元和1个状态空间模型;第一状态空间分支的输出与降维单元的输出进行相加后分别经过第一线性层、第二线性层,第二状态空间分支的输出与降维单元的输出进行相加后、与第二线性层的输出进行特征相乘,再与第一线性层的输出进行特征相加,最后经过层归一化单元后升维输出,利用状态空间模型的长序列深层特征提取的能力增强模块特征挖掘与学习能力。
14、进一步地,在一些实施例中,所述状态空间模型包含3个线性层、1个卷积层、2个激活层、1个选择状态空间模型,并通过残差方式连接;第四线性层的输出第一分支依次经过选择状态空间模型、第一激活层、卷积层和第五线性层得到第一特征,第四线性层的输出第二分支依次经过第二激活层和第六线性层得到第二特征,第一特征和第二特征经过残差方式连接进行输出;
15、所述选择状态空间模型的表达式为:
16、
17、式中,u(t)表示输入信号,x(t)表示历史状态,x′(t)表示当前状态,y(t)表示输出信号;a表示状态转移矩阵,b是输入到状态的矩阵,c是状态到输出的矩阵,d是输入到输出的参数。
18、进一步地,由于图像处理的输入数据往往是离散的,通过选取合适的离散时间步长δt,根据双线性变换法将状态空间模型的常微分方程转换为离散时间的差分方程,所述差分方程为:
19、
20、式中,xk表示当前第k个状态,uk表示输入序列的第k个离散值,xk-1表示第k-1个历史状态,通过计算当前输入对前一个状态的影响xk,并预测输出cxk;其中,表示离散化的状态转移矩阵,表示离散化的输入到状态的矩阵;
21、通过调整步长δt,控制状态空间模型对当前输入的关注度,从而实现对状态的选择性遗忘或保留;当增大δt时,模型倾向于关注当前输入并遗忘之前的状态;当减小δt时,模型倾向于保留更多的历史状态,从而实现选择性的状态空间模型。
22、在一些实施例中,第一多尺度注意力融合模块、第二多尺度注意力融合模块和第三多尺度注意力融合模块的网络结构相同,均包括1个通用插值单元、1个2倍下采样单元、1个局部注意力阶段和1个全局注意力阶段;所述通用插值单元将编码器输出的第一阶段特征、第二阶段特征和第三阶段特征进行尺寸统一,与当前解码器阶段输出特征通过2倍下采样单元后的尺寸保持一致,接着通过所述局部注意力阶段与全局注意力阶段进行局部与全局特征的融合。
23、进一步地,所述2倍下采样单元包含池化层与卷积层,所述特征提取单元包含2个残差卷积块与1个激活函数,所述通道注意力单元包含2个残差卷积块与2个激活函数,所述通用插值单元包含1个图像融合单元与卷积层,所述局部注意力阶段包含1个降维单元、注意力机制和1个降维单元,所述全局注意力阶段包含1个沙漏状注意力融合单元和1个通道注意力单元。
24、在一些实施例中,所述复原模型的训练方法包括如下步骤:
25、获取训练集,所述训练集包括公开的高清人脸数据集模拟真实退化过程,生成待复原的低质量人脸训练图像和对应的高清人脸图像;
26、将所述待复原的低质量人脸训练图像输入至状态空间复原模型中,进行模型训练并得到迭代过程中的复原后的人脸训练图像;
27、根据所述复原后的人脸训练图像和对应的高清人脸复原图像,计算复原模型损失函数;
28、基于梯度下降法对所述复原模型进行迭代更新训练直至达到迭代停止条件,得到训练好的复原模型。
29、进一步的,获取训练集包括如下步骤:
30、获取高质人脸图像,将所述高质人脸图像作为高清人脸真实图像;
31、对所述高质人脸图像进行像素调整操作,得到退化后的人脸图像;将所述退化后的人脸图像作为待复原的人脸训练图像;
32、第二方面,本技术提供了一种基于状态空间模型的人脸图像复原系统,包括处理器及存储介质;
33、所述存储介质用于存储指令;
34、所述处理器用于根据所述指令进行操作以执行根据第一方面所述的方法。
35、第三方面,本技术提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现第一方面所述方法的步骤。
36、第四方面,本技术提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现第一方面所述方法的步骤。
37、第五方面,本技术提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现第一方面所述方法的步骤。
38、与现有技术相比,本发明所达到的有益效果:
39、本发明提出了一种基于状态空间模型的人脸图像复原方法,首先,基于图像融合模块,将不同尺度输入图像在编码器不同阶段进行融合,使得图像像素与语义特征互相学习;其次,基于传统状态空间模型引入多尺度状态空间模型,使用具有不同感受野大小的处理分支,挖掘局部和全局信息,辅助模型深层特征提取;最后,多尺度注意力融合模块,相比一般的连接方式采用跳跃连接的编解码结构,充分考虑编码器不同阶段特征的特点,有效提升解码器的学习能力。本发明能够在保证复原结果细节纹理与几何轮廓的同时保证人脸身份信息的一致性,进一步提升人脸复原模型在真实场景下泛化性能,从而满足各类人脸图像相关的任务与应用需求。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195639.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。