一种电商垂直领域大语言模型的训练方法及装置与流程
- 国知局
- 2024-07-31 23:06:15
本发明涉及大语言模型,具体而言,涉及一种电商垂直领域大语言模型训练方法及装置。
背景技术:
1、随着互联网技术的不断进步和电子商务的蓬勃发展,电商领域对于智能化服务的需求日益增长。特别是在大语言模型技术的推动下,电商行业对于高效、智能的处理和生成文本信息的需求变得尤为迫切。然而,现有的技术方案在满足电商领域特定需求方面存在一些客观的不足和挑战。
2、目前,电商领域主要采用两种方式来利用大语言模型技术:使用闭源商用大模型:通过调整提示词(prompt)的方式,使模型生成与电商相关的文本内容。这种方法的优点在于可以直接利用现有的、成熟的大模型,无需从头开始训练模型。但这种方法的缺点在于,这些“通才型”的模型在预训练阶段并未充分吸收电商领域的知识,因此在特定任务上的表现不尽如人意。基于开源模型的微调:通过在特定任务上对开源模型进行微调,使其适应电商领域的特定需求。这种方法的优点是可以针对特定任务进行优化,但缺点在于开源模型本身的电商知识水平有限,且在多个不同任务上需要分别微调,增加了训练和推理的成本和复杂性。
3、现有技术方案存在以下几个主要的不足之处:电商领域知识掌握不足:无论是闭源商用模型还是开源模型,都缺乏对电商领域知识的深入理解和学习,导致在电商特定任务上的表现不佳。模型更新迭代的不可控性:闭源商用模型的更新迭代可能导致用户之前调优的prompt失效,增加了维护成本。使用成本高:闭源商用模型通常按照token使用量收费,对于频繁使用的用户来说,成本较高。数据安全问题:使用闭源商用模型需要将数据传输给模型厂商,可能存在数据泄露的风险。泛化能力和扩展性差:开源模型在电商领域的知识水平不足,且在多个任务上需要分别微调,无法实现知识共享和能力扩展。
4、有鉴于此,申请人在研究了现有的技术后特提出本技术。
技术实现思路
1、本发明提供了一种电商垂直领域大语言模型训练方法及装置,以改善上述技术问题中的至少一个。
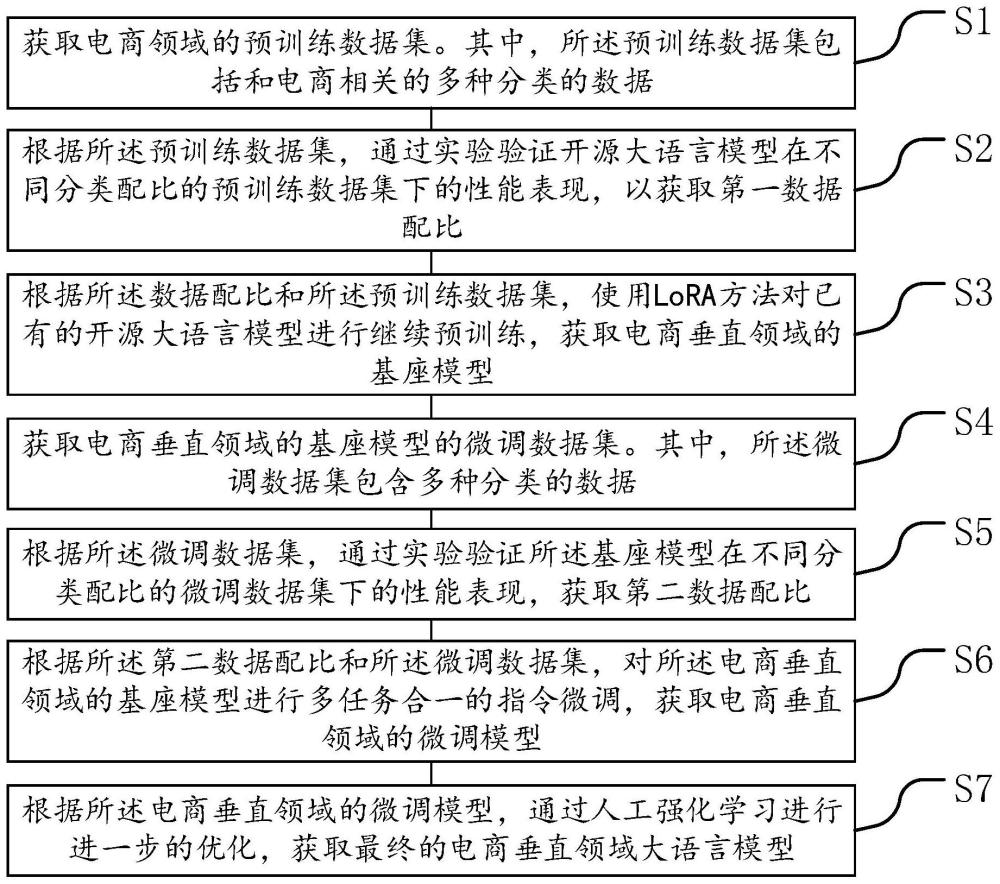
2、第一方面、本发明实施例提供了一种电商垂直领域大语言模型的训练方法,其包含步骤s1至步骤s7。
3、s1、获取电商领域的预训练数据集。其中,所述预训练数据集包括和电商相关的多种分类的数据。
4、s2、根据所述预训练数据集,通过实验验证开源大语言模型在不同分类配比的预训练数据集下的性能表现,以获取第一数据配比。
5、s3、根据所述数据配比和所述预训练数据集,使用lora方法对已有的开源大语言模型进行继续预训练,获取电商垂直领域的基座模型。
6、s4、获取电商垂直领域的基座模型的微调数据集。其中,所述微调数据集包含多种分类的数据。
7、s5、根据所述微调数据集,通过实验验证所述基座模型在不同分类配比的微调数据集下的性能表现,获取第二数据配比。
8、s6、根据所述第二数据配比和所述微调数据集,对所述电商垂直领域的基座模型进行多任务合一的指令微调,获取电商垂直领域的微调模型。
9、s7、根据所述电商垂直领域的微调模型,通过人工强化学习进行进一步的优化,获取最终的电商垂直领域大语言模型。
10、在一个可选的实施例中,步骤s1具体包括步骤s11至步骤s12。
11、s11、获取预训练的初始数据集。其中,所述预训练的初始数据集包括:开源模型公开的原始训练数据、电商领域的网络公开数据、短视频文案数据、直播带货文案数据、电商知识问答数据、商品信息结构化数据、商品评论数据,以及知识型数据。其中,知识型数据包括电商领域书籍、博客和报告数据。
12、s12、对所述预训练的初始数据集进行预处理,获取所述电商领域的预训练数据集。其中,所述预处理包含:文本脏数据去除,通过关键词与语义进行综合筛选,去掉与电商无关的数据。文本去重,利用哈希算法进行去重。文本分词,利用中文分词工具进行分词处理。词向量化,利用开源词向量模型将文本转换为向量表示,以供后续模型训练。
13、在一个可选的实施例中,通过实验验证模型在不同分类配比的数据下的性能表现,以获取数据配比,具体包括步骤a1至步骤a3。
14、a1、根据训练目标设置初始数据配比组合。其中,电商书籍数据、电商知识问答数据、直播带货文案数据的占比高于公开数据。
15、a2、实验验证:根据初始数据配比组合,采用交叉验证比较模型在不同数据配比下的表现,获取最优的配比方案。
16、a3、动态调整:随着模型的训练过程,根据模型的实际效果动态调整数据配比。其中,动态调整的规则为,当发现模型在某领域的表现达不到要求时,增加该领域相关的数据比重,以提升模型在该领域的表现。
17、在一个可选的实施例中,步骤s3具体为:根据所述数据配比和所述预训练数据集,使用lora方法对开源大语言模型llama2-7b进行预训练,获取电商垂直领域的基座模型。
18、在一个可选的实施例中,步骤s4具体包括步骤s41至步骤s44。
19、s41、构造电商知识问答对:根据电商领域的知识型数据向量化构造本地知识库,然后使用检索增强生成技术和大语言模型,以从本地知识库中自动构造电商知识问答对。其中,构造电商知识问答对包括通过prompt提示让大语言模型自动阅读每一段知识并以“问题-答案”的形式进行输出,并用检索增强技术检验问答对的准确性。
20、s42、基于大语言模型的电商营销文案数据蒸馏:利用大语言模型对直播间语音转译出来的文案稿进行清洗与格式化。其中,清洗与格式化包括利用背景杂音去除与多说话人分离技术提取干净的主播说话文本,再利用prompt让大语言模型对说话文本按讲解不同商品的讲解片段进行切分,切分完之后再根据商品库中的商品信息与对应讲解文案进行键值对的组合,形成结构化数据。
21、s43、基于大语言模型+多模态大语言模型的电商营销文案端到端生成:用于多模态大语言模型提取商品主图信息中的商品基本信息及卖点信息,再通过大语言模型+prompt提示词让模型根据提取到的商品及其卖点信息生成电商直播带货文案和/或短视频文案。
22、s44、其他通用自然语言处理任务上的已标注数据:基于过往积累的常规自然语言处理任务已标注的数据,加入到训练数据,用以让模型学习电商基础语义分类与要素抽取任务。其中,常规自然语言处理任务包括文本分类,和/或情感分析,和/或商品信息抽取。
23、在一个可选的实施例中,步骤s6具体为:根据所述第二数据配比对所述微调数据集进行配比混合,并将混合后的数据处理成统一格式后输入电商垂直领域的基座模型,进行多任务合一的指令微调,获取电商垂直领域的微调模型。
24、在一个可选的实施例中,步骤s7具体包括步骤s71至步骤s75。
25、s71、基于人工强化学习技术,设置奖励函数。
26、s72、从微调数据集中抽取数据作为人工强化学习的训练集,输入到所述电商垂直领域的微调模型,获取模型输出。
27、s73、标注团队根据奖励函数的标准,对模型输出进行人工标注,获取反馈数据。
28、s74、根据所述人工标注的反馈数据,通过强化学习算法调整基础模型的参数,以使模型根据奖励函数的反馈进行自我优化,以提高获得更高奖励的概率。
29、s75、通过多次增加反馈、迭代模型,不断收集新的用户反馈和标注数据,持续优化奖励函数和模型参数,获取最终的电商垂直领域大语言模型。
30、第二方面、本发明实施例提供了一种电商垂直领域大语言模型训练装置,其包含第一数据获取模块,第一配比验证模块,第一训练模块,第二数据获取模块,第二配比验证模块,第二训练模块和第三训练模块。
31、第一数据获取模块,用于获取电商领域的预训练数据集。其中,所述预训练数据集包括和电商相关的多种分类的数据。
32、第一配比验证模块,用于根据所述预训练数据集,通过实验验证开源大语言模型在不同分类配比的预训练数据集下的性能表现,以获取第一数据配比。
33、第一训练模块,用于根据所述数据配比和所述预训练数据集,使用lora方法对已有的开源大语言模型进行继续预训练,获取电商垂直领域的基座模型。
34、第二数据获取模块,用于获取电商垂直领域的基座模型的微调数据集。其中,所述微调数据集包含多种分类的数据。
35、第二配比验证模块,用于根据所述微调数据集,通过实验验证所述基座模型在不同分类配比的微调数据集下的性能表现,获取第二数据配比。
36、第二训练模块,用于根据所述第二数据配比和所述微调数据集,对所述电商垂直领域的基座模型进行多任务合一的指令微调,获取电商垂直领域的微调模型。
37、第三训练模块,用于根据所述电商垂直领域的微调模型,通过人工强化学习进行进一步的优化,获取最终的电商垂直领域大语言模型。
38、通过采用上述技术方案,本发明可以取得以下技术效果:
39、本发明实施例的一种电商垂直领域大语言模型的训练方法使得电商垂域模型学习到电商领域的专门知识,能更好地理解电商场景需求,能更好地完成常见电商场景任务。对比开源模型与闭源商业模型在电商文案生成、电商知识问答等任务上效果要更好。模型成本收益方面,通过本方法训练的自研模型,能有效替代闭源商业模型的使用,在ap i调用等方面节约了成本,同时小参数量的垂域模型也能达到大参数量通用开源模型的专项能力,同等能力需求下节约了部署成本。数据安全与商业秘密保护收益方面部署自研垂域模型,业务数据不再需要外传到第三方,保证了公司业务数据安全,在一定程度上保护了本公司新业务发展的商业秘密。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195966.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。