一种基于FPGA的通用流水型卷积结构实现方法
- 国知局
- 2024-07-31 23:06:15
本发明属于卷积神经网络硬件加速领域,可应用于实时目标检测系统,特别提供一种基于fpga的通用流水型卷积结构实现方法。
背景技术:
1、近年来,以卷积神经网络为代表的深度学习技术在各个领域都得到了广泛的应用。卷积神经网络以独特的局部感知和权值共享结构能够更好地进行特征提取,能够处理多种复杂场景的目标检测与识别任务。传统的卷积神经网络一般部署在cpu(中央处理器)或gpu(图像处理器)平台上,然而cpu运算速度慢,无法达到目标检测系统的高实时性要求;gpu虽然是专用的图像处理器,拥有大量的计算资源,但是在一些特定的应用领域中,需要将卷积神经网络部署到移动端嵌入式设备上,高性能的gpu体积大、功耗高,难以应用,而低性能的gpu计算慢、实时性差,所以需要实时性更好、功耗更低、体积更小的硬件加速技术。fpga(现场可编辑逻辑阵列技术)是一种半定制、可重构的专用逻辑电路,具有丰富的逻辑资源,具有灵活性高、并行处理能力强、低功耗、低延迟、高可靠性和开发周期短等优点。应用fpga实现卷积神经网络,可以在小体积、低功耗的前提下实现更快的检测速度。
2、目前的fpga卷积加速器主要被应用于特定网络结构中的单一卷积层计算加速,其工作依赖于与计算机、arm等系统的协作以实现完整的卷积神经网络的功能。这些加速器通常采用全图片数据缓存策略,在单层计算中数据带宽大,也导致了极大的存储资源占用。这种卷积加速器虽然能加速卷积计算,但是对实时目标检测系统的实时性没有显著提升,且不能适用于所有类型的卷积神经网络,限制了其通用性。
技术实现思路
1、本发明的目的在于提供一种基于fpga的通用流水型卷积结构实现方法。
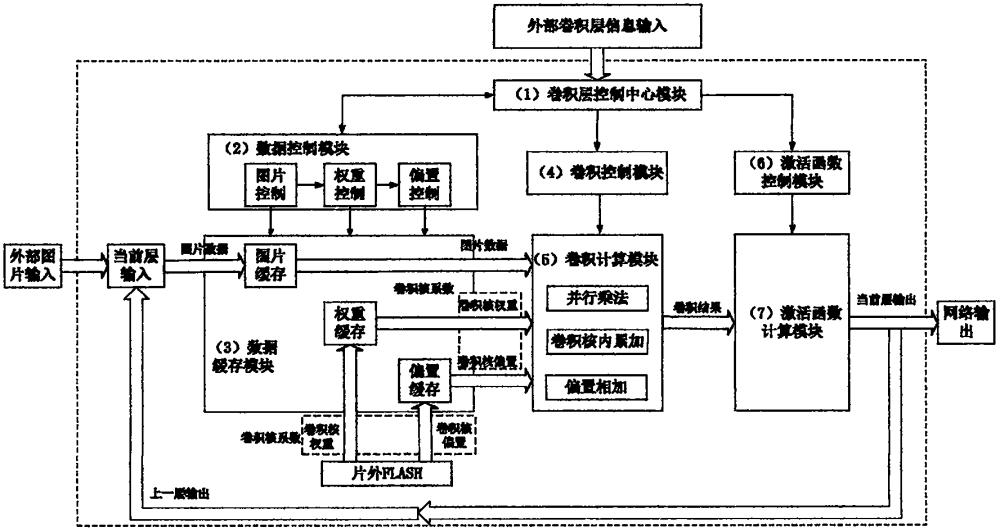
2、实现本发明目的的解决方法为:一种基于fpga的通用流水型卷积结构实现方法,所述方法包括(1)卷积层控制中心模块、(2)数据控制模块、(3)数据缓存模块、(4)卷积控制模块、(5)卷积计算模块、(6)激活函数控制模块、(7)激活函数计算模块:
3、(1)卷积层控制中心模块:卷积层的总控制中心,根据外部输入的卷积神经网络的结构、总并行度(r),完成对当前卷积层的总体控制,输出包括卷积核尺寸(ch1*k*k*ch2)、步长(s)、输入图片尺寸(ch1*wi*hi)、卷积核并行数(p)、输入通道并行数(q)、补零模式(padding)、工作状态信息(运行或休眠)的数据控制信号到数据控制模块,接收数据控制模块返回的数据准备完成信号;在接收到数据控制模块返回的数据准备完成信号后输出包含卷积核并行数(p)、输入通道并行数(q)和卷积核尺寸信息(ch1*k*k*ch2)的卷积控制信号和卷积启动信号到卷积控制模块,输出包含激活函数种类信息(f)的激活函数控制信号到激活函数控制模块。
4、(2)数据控制模块:数据控制模块接收卷积层控制中心模块发出的数据控制信号,得到卷积核尺寸(ch1*k*k*ch2)、步长(s)、输入图片尺寸(ch1*wi*hi)、补零模式(padding)、卷积核并行数(p)、输入通道并行数(q)、工作状态等信息,包括三个子模块:图片控制子模块将按输入通道-行-列(ch1-wi-hi)顺序输入的图片数据,分别存入k(卷积核高)组ram(fpga上的随机存储器),在k行数据的有效信号到来时,按行逐次写入k组ram;根据卷积层控制中心发送的图片控制信号,按照当前层的并行方式读出k行数据,并根据步长s进行行和列的数据滑窗;将图片读写使能信号发送到图片缓存子模块,在用于卷积的图片数据开始读出时将控制权重同步的权重读启动信号发送到权重控制子模块,在读出k*q个可用于计算的数据后返回数据准备完成信号至卷积层控制中心模块。权重控制子模块根据卷积层控制中心模块发送的卷积核并行数(p)信息,将尺寸为输入通道*卷积核宽*卷积核高*输出通道(ch1*k*k*ch2)的卷积核权重分别存入p组ram,按照输出通道(ch2)排序,按照序号顺序依次写入p组ram;在接收到图片控制子模块发送的权重读启动信号后,根据卷积层控制中心模块发送的权重控制信号包含的卷积核尺寸(ch1*k*k*ch2)、步长(s)、输入通道并行数(q)等信息,同步读出与图片数据时序和通道对应的卷积核权重数据;将权重读写使能信号发送到权重缓存子模块,在用于卷积的权重数据开始读出时将控制偏置同步的偏置读启动信号发送到偏置控制子模块。偏置控制子模块将卷积核偏置顺序写入ram;在接收到权重控制子模块发送的偏置读启动信号后,根据卷积层控制中心模块发送的偏置控制信号包含的卷积核尺寸(ch1*k*k*ch2)信息,同步读出与输出通道对应的卷积核偏置数据;将偏置读写使能信号发送到偏置缓存子模块。
5、(3)数据缓存模块:数据缓存模块接收数据控制模块发送的数据读写使能(包括图片读写使能、权重读写使能、偏置读写使能)信号,将片外flash中存储的卷积核系数(即权重和偏置)与输入的每k行图片数据(来源于外部输入或者上一层的卷积层输出)缓存到片上ram,从存储器中取出要用于卷积计算的图片数据和卷积核系数,输出至卷积计算模块。
6、(4)卷积控制模块:卷积控制模块接收卷积层控制中心模块发送的卷积控制信号和卷积启动信号,得到卷积核并行数(p)、输入通道并行数(q)和卷积核尺寸(ch1*k*k*ch2)信息,分配乘法并行次数和累加次数,启动卷积计算,将卷积计算配置信号输出到卷积计算模块。并行乘加次数分配方法为:并行乘法次数为卷积核高*卷积核并行数*输入通道并行数(q*k*p),其中输入通道并行数为一个周期内读出的图片数据的输入通道个数,将完整的输入通道ch1分为ch1/q个部分;卷积核高(k)维度上采用全并行乘法;并且有p个不同的卷积核在并行计算。p个三维卷积核在k*ch1/q个周期内完成ch1*k*k*q次乘法运算,得到一个输出像素点的p个输出通道的并行乘法结果。累加次数为并行乘法结果在k*ch1/q个周期内的累加和q*k个并行乘法结果的累加。
7、(5)卷积计算模块:卷积计算模块接收卷积控制模块发送的卷积计算配置信号和数据缓存模块发送的数据,由三个子模块完成运算:并行乘法子模块卷积计算信号包含的乘法并行次数信息,将图片数据和卷积核权重一一对应相乘;卷积核内累加子模块将每行的并行乘法结果,在卷积核内进行相加,先将k*ch1/q个周期的卷积结果相加,再将q*k个并行的乘法结果相加,得到三维卷积的初步计算结果,对应输出图片的某个点的p个输出通道;偏置相加子模块在卷积核内累加之后,将计算结果与偏置数据按照输出通道数顺序对应相加,得到三维卷积结果
8、(6)激活函数控制模块:激活函数控制模块接收卷积层控制中心模块发送的激活函数控制信号,选择激活函数种类,配置激活函数系数,将激活函数选择信号发送到激活函数计算模块。
9、(7)激活函数计算模块:激活函数计算模块接收卷积计算模块发送的卷积计算结果和激活函数控制模块发送的激活函数选择信号,对卷积后的数据按照选择的激活函数进行激活处理,将通过激活函数的卷积数据作为当前层的输出,送至下一层或作为网络输出。
10、有益效果:与现有技术相比,本发明优点为:
11、(1)整体结构具有通用性,图片尺寸可配置,并行次数可配置,卷积核尺寸可配置,激活函数类型可配置,可以根据fpga芯片资源和应用场景,选择合适的卷积神经网络。
12、(2)所述方法的图片输入之后,中间结果只需按行缓存一部分到片上存储器,可以直接供下一层计算;系数固定存储在片外的flash上,可随时调用,省去了和其他系统的数据交互通道;卷积计算采用多路并行乘加器,并行次数可根据芯片资源和输入数据特征灵活配置。卷积神经网络所有层都在同时计算,这种基于行缓存的层间流水架构、固定的系数存储方案和多路并行计算结构,都极大提高了实时性,可用于卷积加速计算,也可直接应用于多种场景的目标检测系统。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195964.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表