一种基于超图注意力机制的人格检测方法
- 国知局
- 2024-07-31 23:12:33
本发明属于面相个性化推荐,涉及一种基于超图注意力机制的人格检测方法。
背景技术:
1、随着大数据的迅速发展,用户在社交媒体平台上产生了庞大且多样的数据。这些数据涵盖了用户的文字内容、社交媒体活动等方面,包含了丰富的个体特征、情感表达和行为模式等信息。这样的数据源为深入了解和把握用户的人格提供了丰富的材料。
2、本发明主要聚焦于社交媒体用户帖文的人格检测方法,具有广泛的应用前景,可在推荐系统、对话系统和游戏设计等领域得以拓展。通过挖掘和分析用户在线文本中蕴含的人格关联信息,并将其与特定标签相关联,能够快速了解用户的人格特征,为个性化推荐领域提供重要支持。对于企业而言,建立精准的人格检测模型有助于深入分析用户需求,定制更符合用户期望的产品和服务,从而提升用户体验,实现更为精准的市场营销和推广活动。同时,对用户而言,人格分析有助于更全面地了解和发现适合其需求的产品和服务。
3、近年来,随着大规模预训练语言模型的流行,人格检测方法也从中获益。同时,鉴于用户的帖文通常呈无序且关系丰富的结构,图神经网络能够有效地处理这些数据。因此,将不同图的构造方式引入人格检测模型已经成为该领域的主流趋势。然而,简单的图神经网络无法提取复杂的人格线索,仍然需要设计更好的适应于人格检测的图方法。
4、本发明通过引入超图注意力机制,旨在提取用户帖文中的高阶上下文依赖关系并提取人格相关的线索,从而获得更高质量的文本表示和人格特征。因此,提出了一种基于超图注意力机制的人格检测方法,并构建了完整的基于超图注意力机制的人格检测模型。
技术实现思路
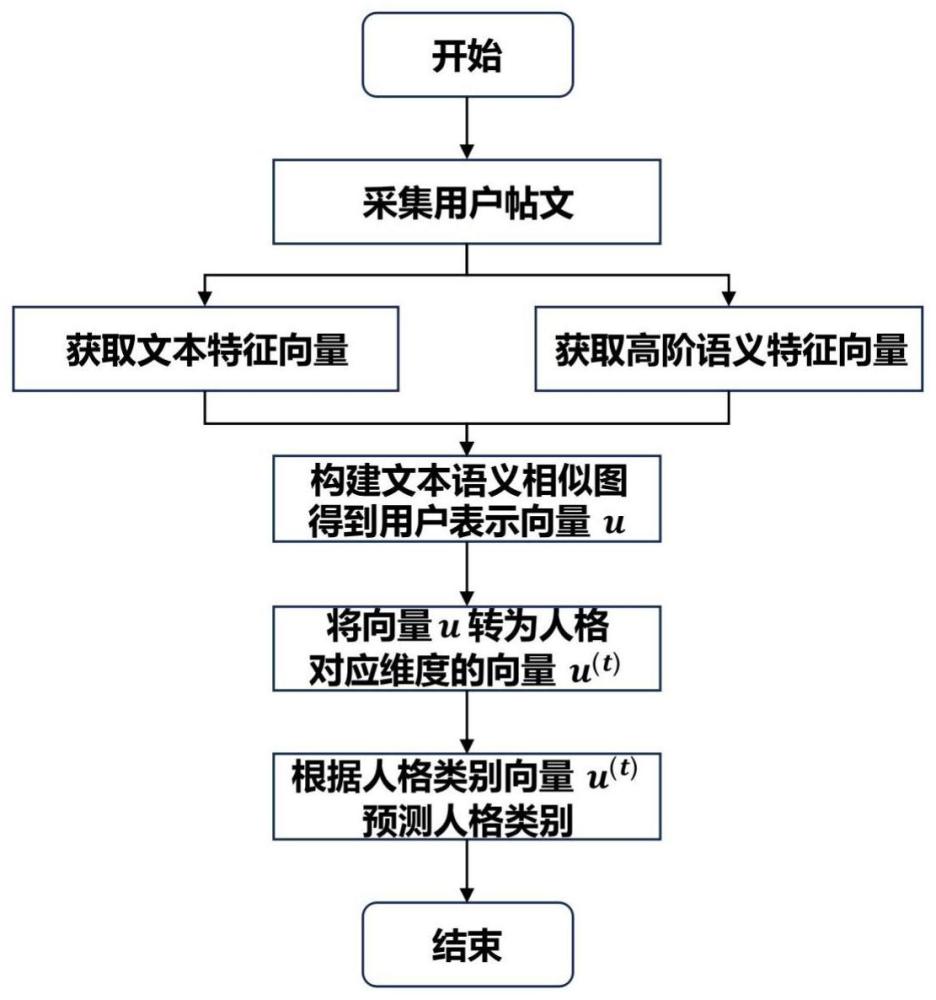
1、本发明的一个目的是针对现有技术人格检测准确率不足,提供的一种基于超图注意力机制的人格检测方法,该方法利用用户在社交媒体上的帖文信息,通过超图注意力机制学习帖文中的高阶语义信息,并采用预训练语言模型bert(bidirectional encoderrepresentation from transformers)提取帖文的语义特征,最后通过图卷积神经网络(gcn)进行信息聚合,得到最终的用户人格表征,以提升人格检测的准确度。
2、本发明所采用的技术方案如下:
3、步骤(1)、收集用户在社交媒体上的帖文文本,并获取帖文的文本特征向量,从而学习文本的语义特征;
4、步骤(2)、获取高阶语义特征向量,采用超图注意力机制获取帖文的高阶语义信息;
5、所述超图注意力机制由节点级别的注意力机制和超边级别的注意力机制组成;
6、步骤(3)、根据帖文的文本特征和高阶语义特征构建文本语义相似图,采用图卷积网络进一步聚合信息,得到用户表示向量u;
7、所述文本语义相似图采用动态的方式建立了节点之间的连接;
8、步骤(4)、将高维的用户表示向量u转化为人格特征对应维度的人格类别向量u(t);
9、步骤(5)、根据人格类别向量u(t)预测用户的人格类别。
10、本发明的另一个目的是提供一种计算机存储介质,其上存储有对应的计算程序,所述计算程序在计算机中运行时,用于执行上述的方法。
11、本发明的又一个目的是提供一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器在执行所述可执行代码时,实现上述的方法。
12、本发明提供的技术方案包含以下有益效果:
13、本发明提出一种基于超图注意力机制的人格检测模型,对用户的帖文文本进行高阶语义特征提取。本发明中的超图注意力机制包括节点级别的注意力机制和超边级别的注意力机制。其中,节点级别的注意力机制通过计算超边上所有节点对该边的注意力分数,突出对超边更有意义的节点信息。而超边级别的注意力机制则通过计算与一个节点相连的所有超边的注意力分数,突出对节点更有意义的超边信息。通过这两类注意力机制,解决了现有的文本处理方法在长距离依赖关系时提取不足的问题,从而获得更高质量的上下文表示。
14、本发明提出了面向人格检测的超图构建方法,该超图有三类超边分别是:帖文顺序超边,心理超边和情感超边。将每个帖文视为一个顺序超边,连接其中的所有单词,并同时保留了文档的结构信息。将liwc(linguistic inquiry andword count)词典中的k1个不同的类别和nrc(national research council canada)词典中的k2个不同的类别,分别作为心理超边和情感超边的类别,以捕获与心理或情感相关的单词之间的高阶关联性,从而更有效地提取帖文中的人格相关线索。
15、本发明通过预训练语言模型bert提取帖文的文本特征,通过图卷积神经网络聚合高阶语义特征和文本特征,从而获得更为准确的用户表征,提高了人格检测的准确性。
技术特征:1.一种基于超图注意力机制的人格检测方法,其特征在于包括以下步骤:
2.根据权利要求1所述的方法,其特征在于步骤(1)中,帖文的文本特征向量采用bert预训练语言模型获取。
3.根据权利要求1所述的方法,其特征在于步骤(2)具体是:
4.根据权利要求3所述的方法,其特征在于步骤(2)超图中是将每个帖文视为一个帖文顺序超边,连接帖文中的所有单词;选择liwc词典中的k1个不同心理类别作为不同的心理超边,将帖文中同属于一个心理类别的单词连接起来;选取nrc词典中的k2个不同的情感类别作为情感超边,将帖文中同属于一个情感类别的单词连接起来。
5.根据权利要求3所述的方法,其特征在于步骤(2)中节点级别的注意力机制通过计算一条超边ej上不同节点的注意力分数,并对它们进行加权得到超边表示
6.根据权利要求3所述的方法,其特征在于步骤(2)中边级别的注意力机制通过计算与节点vi相连的不同超边的注意力分数,并对它们进行加权得到新的节点表示
7.根据权利要求1所述的方法,其特征在于步骤(3)具体是:
8.实现权利要求1-7任一项所述方法的人格检测系统,其特征在于包括:
9.一种计算机存储介质,其上存储有对应的计算程序,所述计算程序在计算机中运行时,用于执行上述权利要求1-7任一项所述方法的步骤。
10.一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器在执行所述可执行代码时,实现上述权利要求1-7任一项所述方法的步骤。
技术总结本发明公开一种基于超图注意力机制的人格检测方法。本发明是收集用户在社交媒体上的帖文文本;接着通过BERT预训练语言模型获取帖文的文本特征向量,从而学习文本的语义特征;进一步获取高阶语义特征向量,采用超图注意力机制获取帖文的高阶语义信息;随后,构建图卷积网络,将文本特征向量和高阶语义特征向量作为节点,通过余弦相似度计算构建节点之间的边,并通过图卷积网络学习得到最终的用户人格表征。本发明通过超图注意力机制获取更为高质量的文本表示,弥补了目前文本表示方法在处理文本中的长距离依赖关系时的性能不足,提高了人格检测的准确性,为提供更加准确的个性化服务提供了技术支持。技术研发人员:周仁杰,占健豪,万健,张纪林,殷昱煜,倪天成,袁耀祖受保护的技术使用者:杭州电子科技大学技术研发日:技术公布日:2024/7/29本文地址:https://www.jishuxx.com/zhuanli/20240730/196417.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。